 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Structure of Relation Decoding Linear Operators in Large Language Models
Oct 30, 2025This paper investigates the structure of linear operators introduced in Hernandez et al. [2023] that decode specific relational facts in transformer language models. We extend their single-relation findings to a collection of relations and systematically chart their organization. We show that such collections of relation decoders can be highly compressed by simple order-3 tensor networks without significant loss in decoding accuracy. To explain this surprising redundancy, we develop a cross-evaluation protocol, in which we apply each linear decoder operator to the subjects of every other relation. Our results reveal that these linear maps do not encode distinct relations, but extract recurring, coarse-grained semantic properties (e.g., country of capital city and country of food are both in the country-of-X property). This property-centric structure clarifies both the operators' compressibility and highlights why they generalize only to new relations that are semantically close. Our findings thus interpret linear relational decoding in transformer language models as primarily property-based, rather than relation-specific.
Mode Combinability: Exploring Convex Combinations of Permutation Aligned Models
Aug 22, 2023



We explore element-wise convex combinations of two permutation-aligned neural network parameter vectors $\Theta_A$ and $\Theta_B$ of size $d$. We conduct extensive experiments by examining various distributions of such model combinations parametrized by elements of the hypercube $[0,1]^{d}$ and its vicinity. Our findings reveal that broad regions of the hypercube form surfaces of low loss values, indicating that the notion of linear mode connectivity extends to a more general phenomenon which we call mode combinability. We also make several novel observations regarding linear mode connectivity and model re-basin. We demonstrate a transitivity property: two models re-based to a common third model are also linear mode connected, and a robustness property: even with significant perturbations of the neuron matchings the resulting combinations continue to form a working model. Moreover, we analyze the functional and weight similarity of model combinations and show that such combinations are non-vacuous in the sense that there are significant functional differences between the resulting models.
Similarity and Matching of Neural Network Representations
Oct 27, 2021



We employ a toolset -- dubbed Dr. Frankenstein -- to analyse the similarity of representations in deep neural networks. With this toolset, we aim to match the activations on given layers of two trained neural networks by joining them with a stitching layer. We demonstrate that the inner representations emerging in deep convolutional neural networks with the same architecture but different initializations can be matched with a surprisingly high degree of accuracy even with a single, affine stitching layer. We choose the stitching layer from several possible classes of linear transformations and investigate their performance and properties. The task of matching representations is closely related to notions of similarity. Using this toolset, we also provide a novel viewpoint on the current line of research regarding similarity indices of neural network representations: the perspective of the performance on a task.
Visualizing Transfer Learning
Jul 15, 2020



We provide visualizations of individual neurons of a deep image recognition network during the temporal process of transfer learning. These visualizations qualitatively demonstrate various novel properties of the transfer learning process regarding the speed and characteristics of adaptation, neuron reuse, spatial scale of the represented image features, and behavior of transfer learning to small data. We publish the large-scale dataset that we have created for the purposes of this analysis.
Negative Sampling in Variational Autoencoders
Oct 07, 2019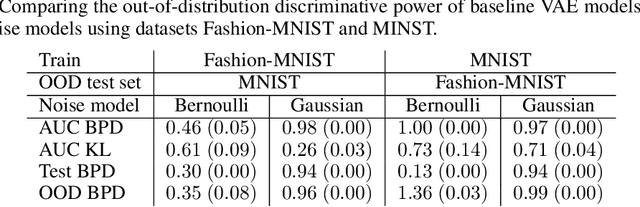
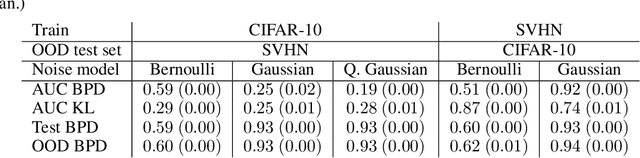


We propose negative sampling as an approach to improve the notoriously bad out-of-distribution likelihood estimates of Variational Autoencoder models. Our model pushes latent images of negative samples away from the prior. When the source of negative samples is an auxiliary dataset, such a model can vastly improve on baselines when evaluated on OOD detection tasks. Perhaps more surprisingly, we present a fully unsupervised variant that can also significantly improve detection performance: using the output of the generator as negative samples results in a fully unsupervised model that can be interpreted as adversarially trained.
Towards Finding Longer Proofs
May 30, 2019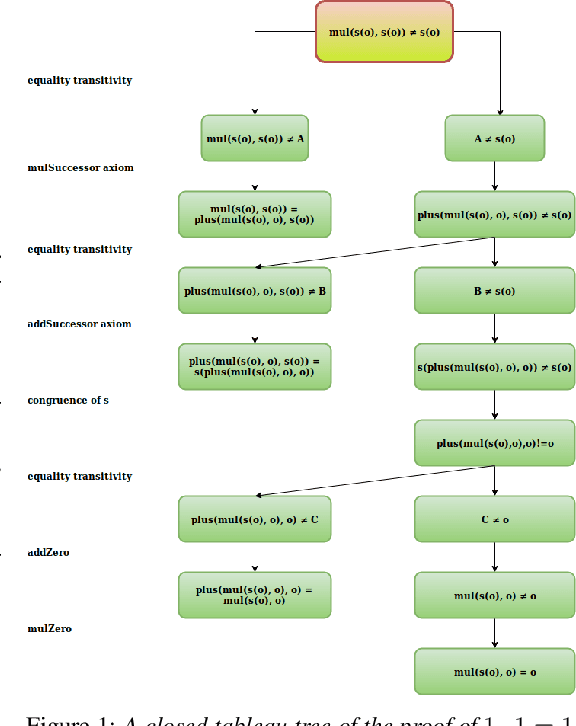
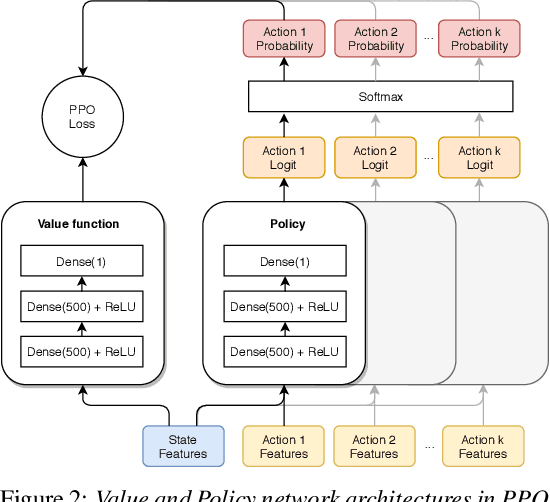
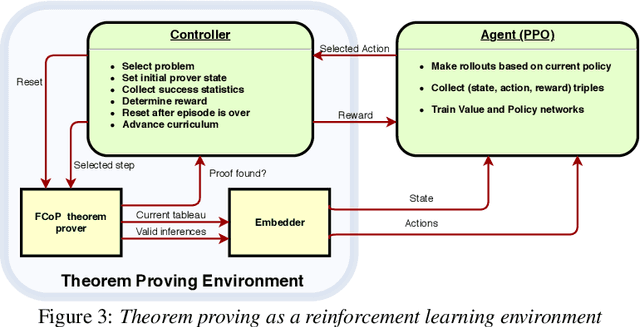
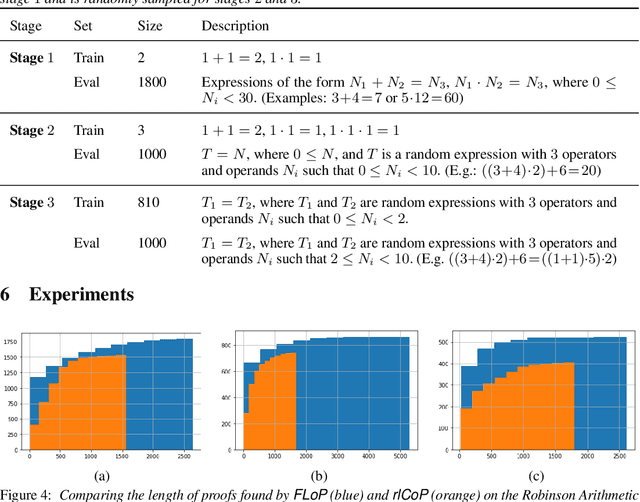
We present a reinforcement learning (RL) based guidance system for automated theorem proving geared towards Finding Longer Proofs (FLoP). FLoP focuses on generalizing from short proofs to longer ones of similar structure. To achieve that, FLoP uses state-of-the-art RL approaches that were previously not applied in theorem proving. In particular, we show that curriculum learning significantly outperforms previous learning-based proof guidance on a synthetic dataset of increasingly difficult arithmetic problems.
Gradient Regularization Improves Accuracy of Discriminative Models
May 24, 2018



Regularizing the gradient norm of the output of a neural network with respect to its inputs is a powerful technique, rediscovered several times. This paper presents evidence that gradient regularization can consistently improve classification accuracy on vision tasks, using modern deep neural networks, especially when the amount of training data is small. We introduce our regularizers as members of a broader class of Jacobian-based regularizers. We demonstrate empirically on real and synthetic data that the learning process leads to gradients controlled beyond the training points, and results in solutions that generalize well.