Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-dependent Pruning to find the Winning Lottery Ticket
Paper and Code
Jun 25, 2020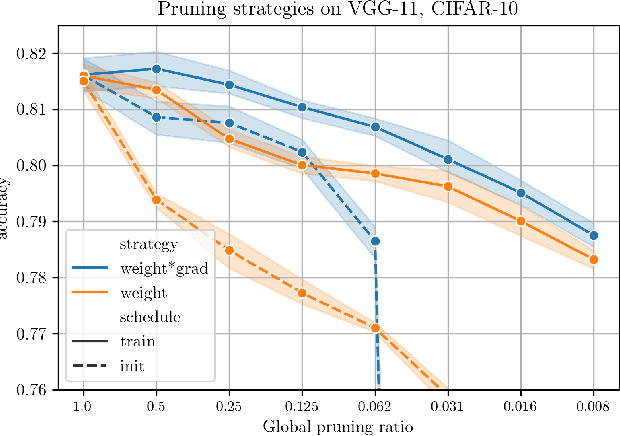
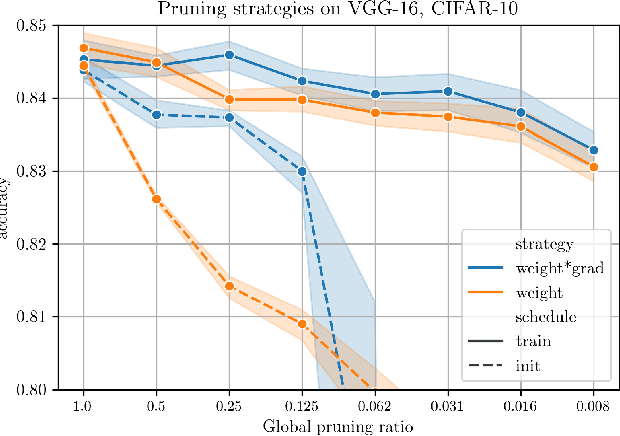
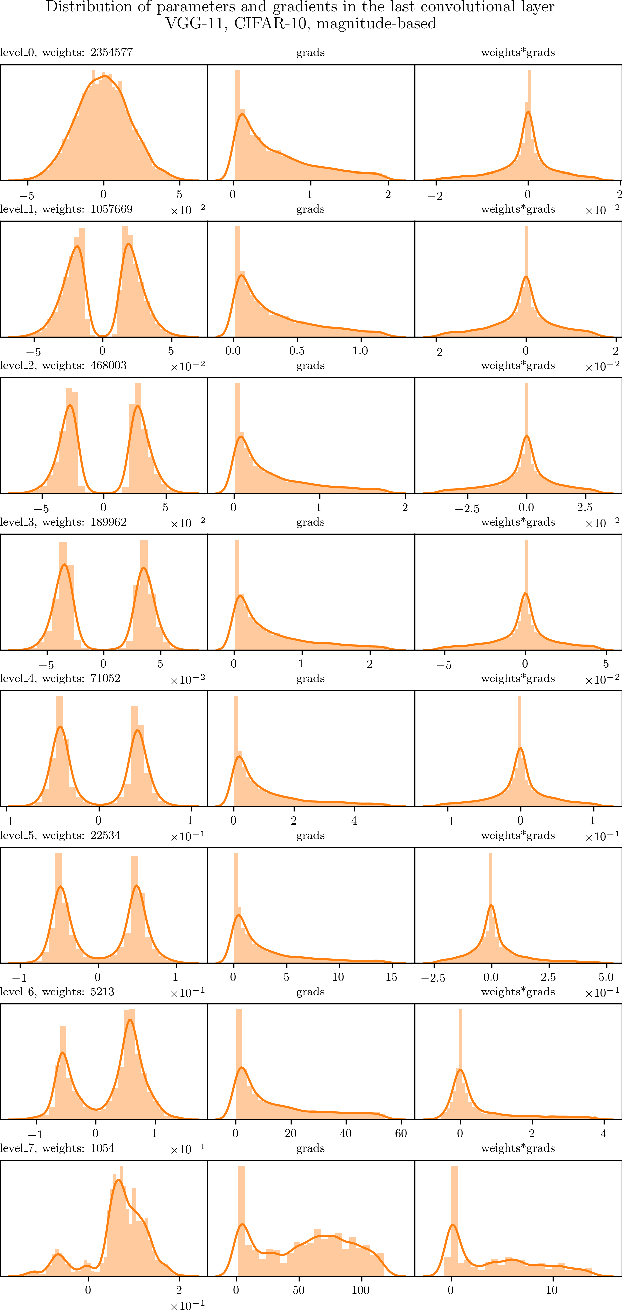
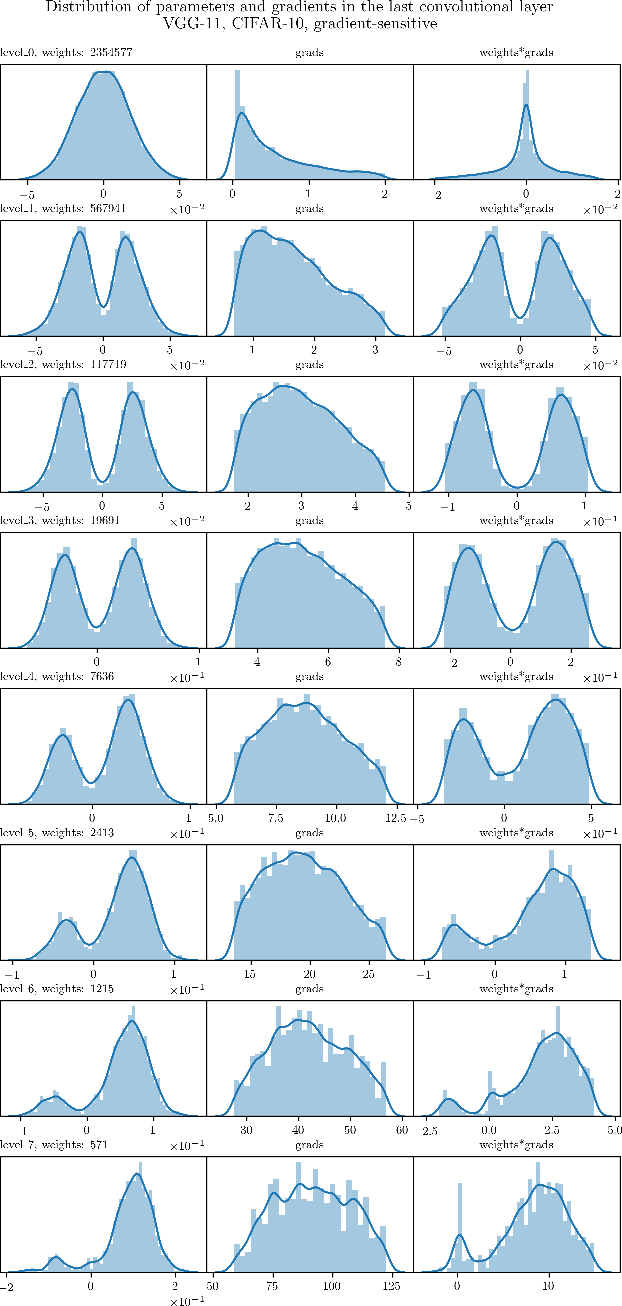
The Lottery Ticket Hypothesis postulates that a freshly initialized neural network contains a small subnetwork that can be trained in isolation to achieve similar performance as the full network. Our paper examines several alternatives to search for such subnetworks. We conclude that incorporating a data dependent component into the pruning criterion in the form of the gradient of the training loss -- as done in the SNIP method -- consistently improves the performance of existing pruning algorithms.
View paper on