 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
Feb 05, 2025We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with other additions, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%. The search process of AlphaGeometry2 has also been greatly improved through the use of Gemini architecture for better language modeling, and a novel knowledge-sharing mechanism that combines multiple search trees. Together with further enhancements to the symbolic engine and synthetic data generation, we have significantly boosted the overall solving rate of AlphaGeometry2 to 84% for $\textit{all}$ geometry problems over the last 25 years, compared to 54% previously. AlphaGeometry2 was also part of the system that achieved silver-medal standard at IMO 2024 https://dpmd.ai/imo-silver. Last but not least, we report progress towards using AlphaGeometry2 as a part of a fully automated system that reliably solves geometry problems directly from natural language input.
Graph2Tac: Learning Hierarchical Representations of Math Concepts in Theorem proving
Jan 09, 2024



Concepts abound in mathematics and its applications. They vary greatly between subject areas, and new ones are introduced in each mathematical paper or application. A formal theory builds a hierarchy of definitions, theorems and proofs that reference each other. When an AI agent is proving a new theorem, most of the mathematical concepts and lemmas relevant to that theorem may have never been seen during training. This is especially true in the Coq proof assistant, which has a diverse library of Coq projects, each with its own definitions, lemmas, and even custom tactic procedures used to prove those lemmas. It is essential for agents to incorporate such new information into their knowledge base on the fly. We work towards this goal by utilizing a new, large-scale, graph-based dataset for machine learning in Coq. We leverage a faithful graph-representation of Coq terms that induces a directed graph of dependencies between definitions to create a novel graph neural network, Graph2Tac (G2T), that takes into account not only the current goal, but also the entire hierarchy of definitions that led to the current goal. G2T is an online model that is deeply integrated into the users' workflow and can adapt in real time to new Coq projects and their definitions. It complements well with other online models that learn in real time from new proof scripts. Our novel definition embedding task, which is trained to compute representations of mathematical concepts not seen during training, boosts the performance of the neural network to rival state-of-the-art k-nearest neighbor predictors.
Alien Coding
Jan 27, 2023



We introduce a self-learning algorithm for synthesizing programs for OEIS sequences. The algorithm starts from scratch initially generating programs at random. Then it runs many iterations of a self-learning loop that interleaves (i) training neural machine translation to learn the correspondence between sequences and the programs discovered so far, and (ii) proposing many new programs for each OEIS sequence by the trained neural machine translator. The algorithm discovers on its own programs for more than 78000 OEIS sequences, sometimes developing unusual programming methods. We analyze its behavior and the invented programs in several experiments.
Machine Learning Meets The Herbrand Universe
Oct 07, 2022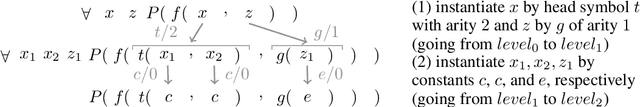
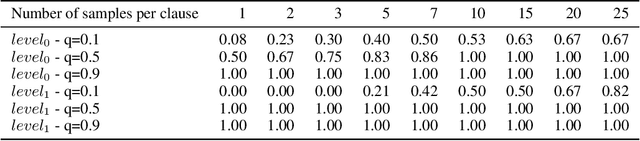
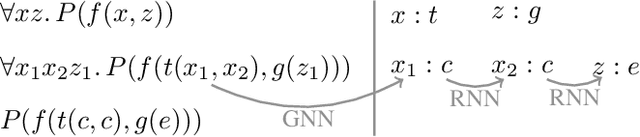
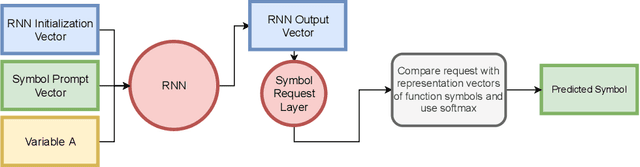
The appearance of strong CDCL-based propositional (SAT) solvers has greatly advanced several areas of automated reasoning (AR). One of the directions in AR is thus to apply SAT solvers to expressive formalisms such as first-order logic, for which large corpora of general mathematical problems exist today. This is possible due to Herbrand's theorem, which allows reduction of first-order problems to propositional problems by instantiation. The core challenge is choosing the right instances from the typically infinite Herbrand universe. In this work, we develop the first machine learning system targeting this task, addressing its combinatorial and invariance properties. In particular, we develop a GNN2RNN architecture based on an invariant graph neural network (GNN) that learns from problems and their solutions independently of symbol names (addressing the abundance of skolems), combined with a recurrent neural network (RNN) that proposes for each clause its instantiations. The architecture is then trained on a corpus of mathematical problems and their instantiation-based proofs, and its performance is evaluated in several ways. We show that the trained system achieves high accuracy in predicting the right instances, and that it is capable of solving many problems by educated guessing when combined with a ground solver. To our knowledge, this is the first convincing use of machine learning in synthesizing relevant elements from arbitrary Herbrand universes.
The Isabelle ENIGMA
May 04, 2022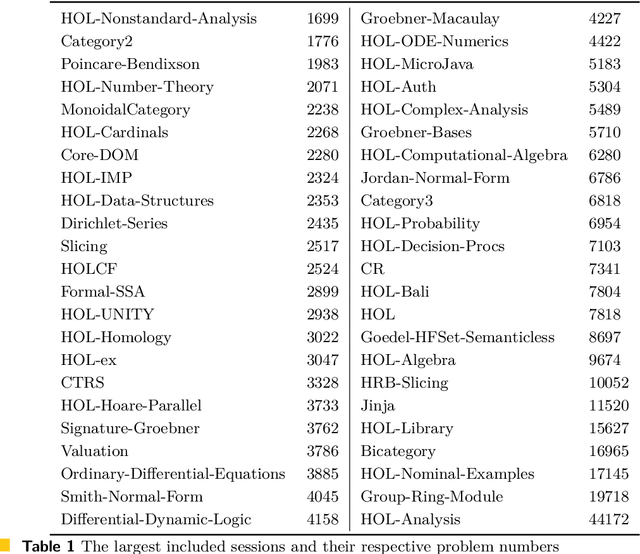



We significantly improve the performance of the E automated theorem prover on the Isabelle Sledgehammer problems by combining learning and theorem proving in several ways. In particular, we develop targeted versions of the ENIGMA guidance for the Isabelle problems, targeted versions of neural premise selection, and targeted strategies for E. The methods are trained in several iterations over hundreds of thousands untyped and typed first-order problems extracted from Isabelle. Our final best single-strategy ENIGMA and premise selection system improves the best previous version of E by 25.3% in 15 seconds, outperforming also all other previous ATP and SMT systems.
Learning Theorem Proving Components
Jul 21, 2021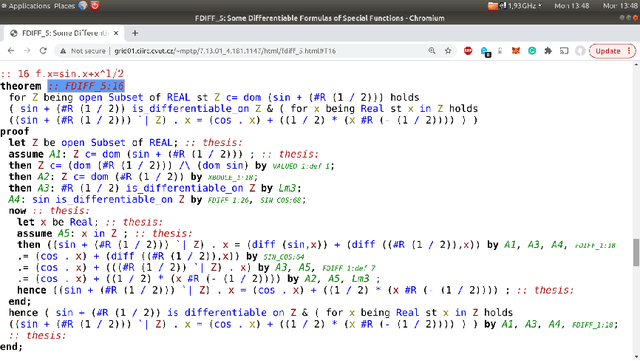

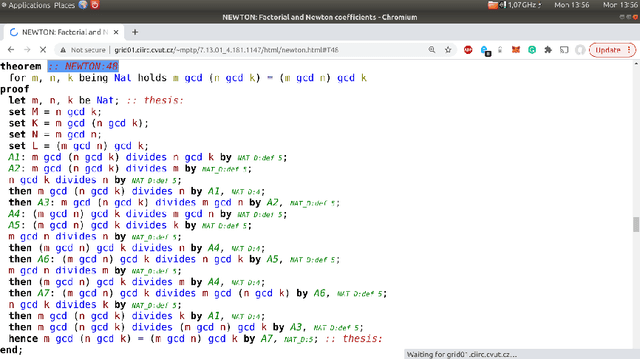
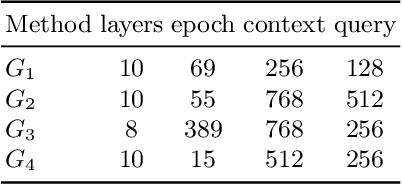
Saturation-style automated theorem provers (ATPs) based on the given clause procedure are today the strongest general reasoners for classical first-order logic. The clause selection heuristics in such systems are, however, often evaluating clauses in isolation, ignoring other clauses. This has changed recently by equipping the E/ENIGMA system with a graph neural network (GNN) that chooses the next given clause based on its evaluation in the context of previously selected clauses. In this work, we describe several algorithms and experiments with ENIGMA, advancing the idea of contextual evaluation based on learning important components of the graph of clauses.
Fast and Slow Enigmas and Parental Guidance
Jul 14, 2021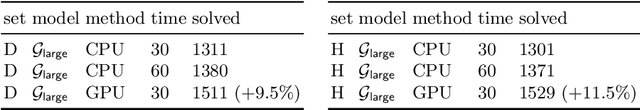
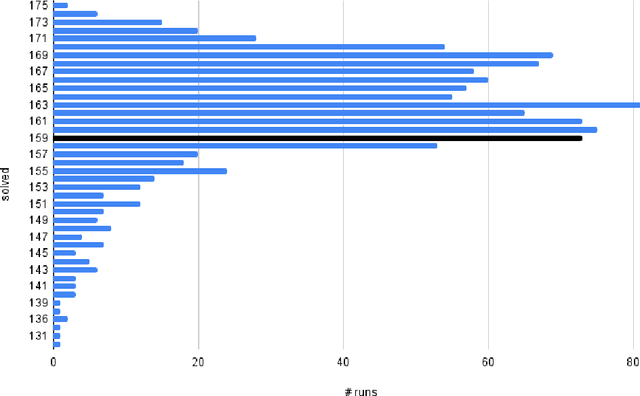
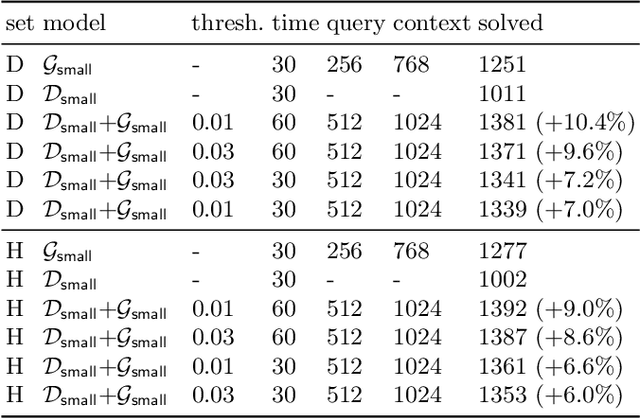
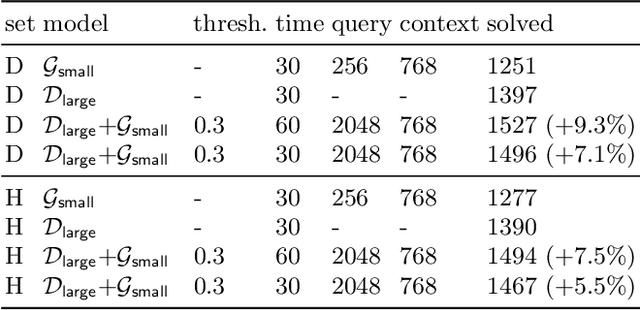
We describe several additions to the ENIGMA system that guides clause selection in the E automated theorem prover. First, we significantly speed up its neural guidance by adding server-based GPU evaluation. The second addition is motivated by fast weight-based rejection filters that are currently used in systems like E and Prover9. Such systems can be made more intelligent by instead training fast versions of ENIGMA that implement more intelligent pre-filtering. This results in combinations of trainable fast and slow thinking that improves over both the fast-only and slow-only methods. The third addition is based on "judging the children by their parents", i.e., possibly rejecting an inference before it produces a clause. This is motivated by standard evolutionary mechanisms, where there is always a cost to producing all possible offsprings in the current population. This saves time by not evaluating all clauses by more expensive methods and provides a complementary view of the generated clauses. The methods are evaluated on a large benchmark coming from the Mizar Mathematical Library, showing good improvements over the state of the art.
The Role of Entropy in Guiding a Connection Prover
May 31, 2021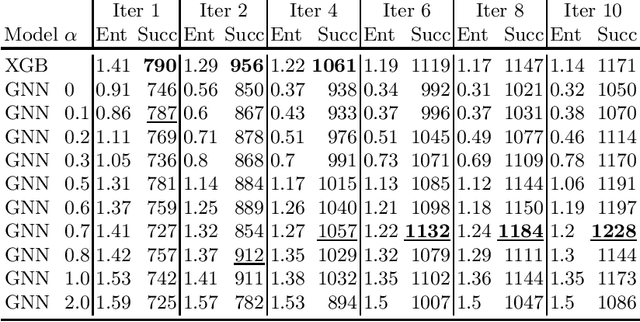
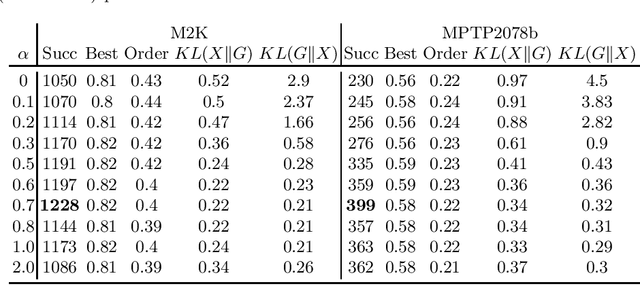
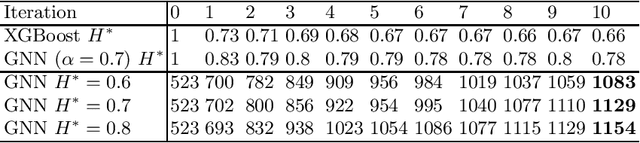
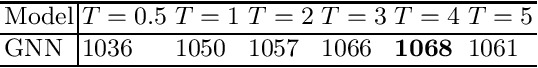
In this work we study how to learn good algorithms for selecting reasoning steps in theorem proving. We explore this in the connection tableau calculus implemented by leanCoP where the partial tableau provides a clean and compact notion of a state to which a limited number of inferences can be applied. We start by incorporating a state-of-the-art learning algorithm -- a graph neural network (GNN) -- into the plCoP theorem prover. Then we use it to observe the system's behaviour in a reinforcement learning setting, i.e., when learning inference guidance from successful Monte-Carlo tree searches on many problems. Despite its better pattern matching capability, the GNN initially performs worse than a simpler previously used learning algorithm. We observe that the simpler algorithm is less confident, i.e., its recommendations have higher entropy. This leads us to explore how the entropy of the inference selection implemented via the neural network influences the proof search. This is related to research in human decision-making under uncertainty, and in particular the probability matching theory. Our main result shows that a proper entropy regularisation, i.e., training the GNN not to be overconfident, greatly improves plCoP's performance on a large mathematical corpus.
ENIGMA Anonymous: Symbol-Independent Inference Guiding Machine (system description)
Feb 13, 2020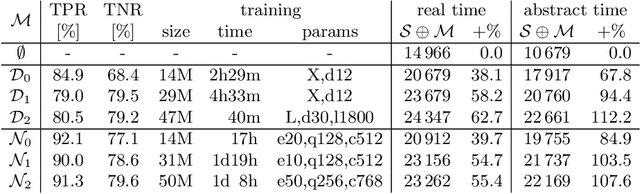
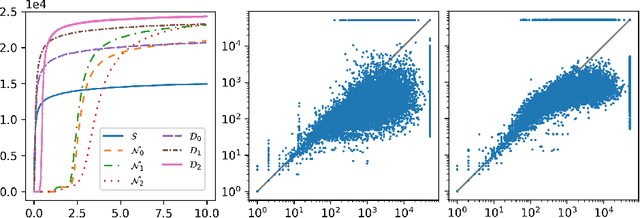
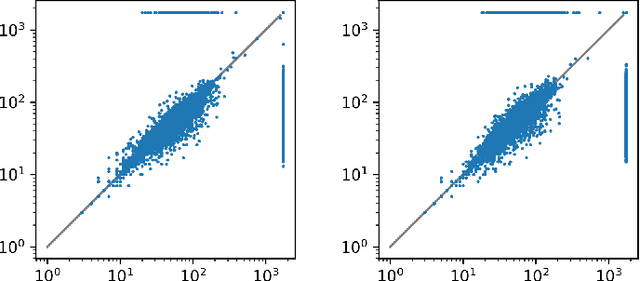
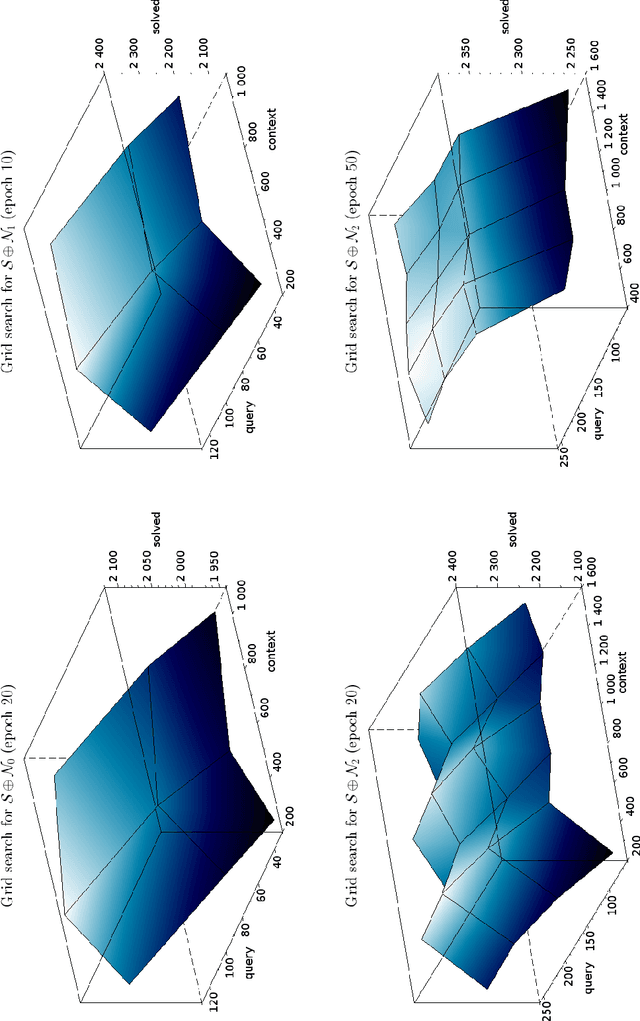
We describe an implementation of gradient boosting and neural guidance of saturation-style automated theorem provers that does not depend on consistent symbol names across problems. For the gradient-boosting guidance, we manually create abstracted features by considering arity-based encodings of formulas. For the neural guidance, we use symbol-independent graph neural networks and their embedding of the terms and clauses. The two methods are efficiently implemented in the E prover and its ENIGMA learning-guided framework and evaluated on the MPTP large-theory benchmark. Both methods are shown to achieve comparable real-time performance to state-of-the-art symbol-based methods.
Property Invariant Embedding for Automated Reasoning
Nov 27, 2019


Automated reasoning and theorem proving have recently become major challenges for machine learning. In other domains, representations that are able to abstract over unimportant transformations, such as abstraction over translations and rotations in vision, are becoming more common. Standard methods of embedding mathematical formulas for learning theorem proving are however yet unable to handle many important transformations. In particular, embedding previously unseen labels, that often arise in definitional encodings and in Skolemization, has been very weak so far. Similar problems appear when transferring knowledge between known symbols. We propose a novel encoding of formulas that extends existing graph neural network models. This encoding represents symbols only by nodes in the graph, without giving the network any knowledge of the original labels. We provide additional links between such nodes that allow the network to recover the meaning and therefore correctly embed such nodes irrespective of the given labels. We test the proposed encoding in an automated theorem prover based on the tableaux connection calculus, and show that it improves on the best characterizations used so far. The encoding is further evaluated on the premise selection task and a newly introduced symbol guessing task, and shown to correctly predict 65% of the symbol names.