 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGold-medalist Performance in Solving Olympiad Geometry with AlphaGeometry2
Feb 05, 2025We present AlphaGeometry2, a significantly improved version of AlphaGeometry introduced in Trinh et al. (2024), which has now surpassed an average gold medalist in solving Olympiad geometry problems. To achieve this, we first extend the original AlphaGeometry language to tackle harder problems involving movements of objects, and problems containing linear equations of angles, ratios, and distances. This, together with other additions, has markedly improved the coverage rate of the AlphaGeometry language on International Math Olympiads (IMO) 2000-2024 geometry problems from 66% to 88%. The search process of AlphaGeometry2 has also been greatly improved through the use of Gemini architecture for better language modeling, and a novel knowledge-sharing mechanism that combines multiple search trees. Together with further enhancements to the symbolic engine and synthetic data generation, we have significantly boosted the overall solving rate of AlphaGeometry2 to 84% for $\textit{all}$ geometry problems over the last 25 years, compared to 54% previously. AlphaGeometry2 was also part of the system that achieved silver-medal standard at IMO 2024 https://dpmd.ai/imo-silver. Last but not least, we report progress towards using AlphaGeometry2 as a part of a fully automated system that reliably solves geometry problems directly from natural language input.
Leveraging Out-of-Domain Data for Domain-Specific Prompt Tuning in Multi-Modal Fake News Detection
Nov 27, 2023The spread of fake news using out-of-context images has become widespread and is a challenging task in this era of information overload. Since annotating huge amounts of such data requires significant time of domain experts, it is imperative to develop methods which can work in limited annotated data scenarios. In this work, we explore whether out-of-domain data can help to improve out-of-context misinformation detection (termed here as multi-modal fake news detection) of a desired domain, eg. politics, healthcare, etc. Towards this goal, we propose a novel framework termed DPOD (Domain-specific Prompt-tuning using Out-of-Domain data). First, to compute generalizable features, we modify the Vision-Language Model, CLIP to extract features that helps to align the representations of the images and corresponding text captions of both the in-domain and out-of-domain data in a label-aware manner. Further, we propose a domain-specific prompt learning technique which leverages the training samples of all the available domains based on the the extent they can be useful to the desired domain. Extensive experiments on a large-scale benchmark dataset, namely NewsClippings demonstrate that the proposed framework achieves state of-the-art performance, significantly surpassing the existing approaches for this challenging task.
MixupE: Understanding and Improving Mixup from Directional Derivative Perspective
Dec 29, 2022



Mixup is a popular data augmentation technique for training deep neural networks where additional samples are generated by linearly interpolating pairs of inputs and their labels. This technique is known to improve the generalization performance in many learning paradigms and applications. In this work, we first analyze Mixup and show that it implicitly regularizes infinitely many directional derivatives of all orders. We then propose a new method to improve Mixup based on the novel insight. To demonstrate the effectiveness of the proposed method, we conduct experiments across various domains such as images, tabular data, speech, and graphs. Our results show that the proposed method improves Mixup across various datasets using a variety of architectures, for instance, exhibiting an improvement over Mixup by 0.8% in ImageNet top-1 accuracy.
CNT : A new Algorithm for Leveraging Top-Down Feedback
Oct 18, 2022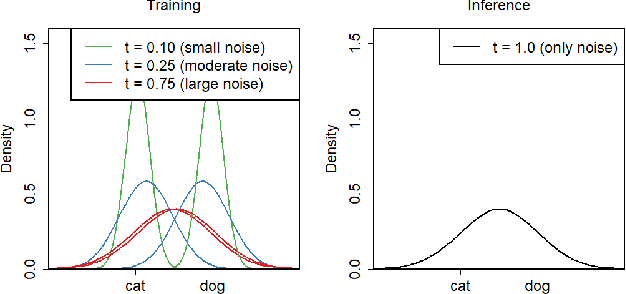
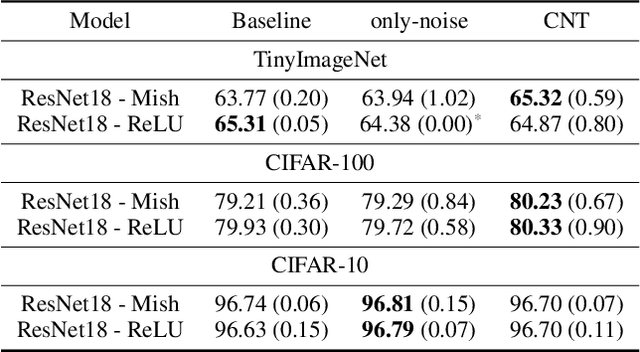
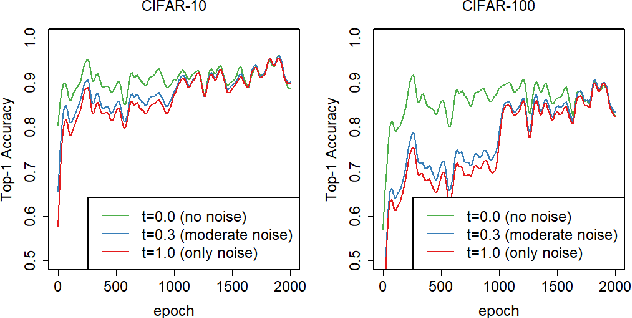
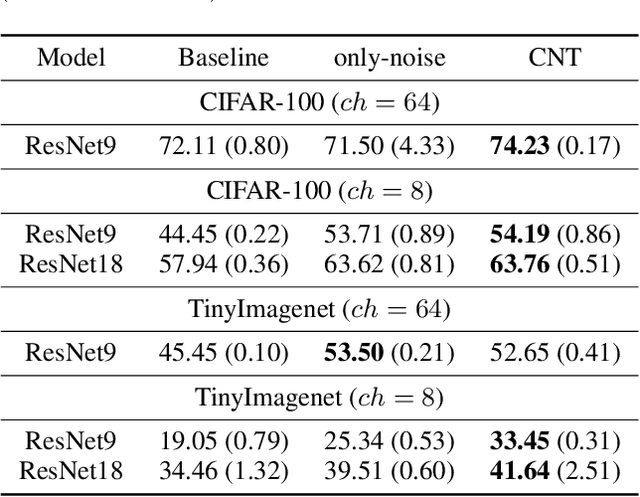
We propose a novel regularizer for supervised learning called Conditioning on Noisy Targets (CNT). This approach consists in conditioning the model on a noisy version of the target(s) (e.g., actions in imitation learning or labels in classification) at a random noise level (from small to large noise). At inference time, since we do not know the target, we run the network with only noise in place of the noisy target. CNT provides hints through the noisy label (with less noise, we can more easily infer the true target). This give two main benefits: 1) the top-down feedback allows the model to focus on simpler and more digestible sub-problems and 2) rather than learning to solve the task from scratch, the model will first learn to master easy examples (with less noise), while slowly progressing toward harder examples (with more noise).
Towards Domain-Agnostic Contrastive Learning
Nov 09, 2020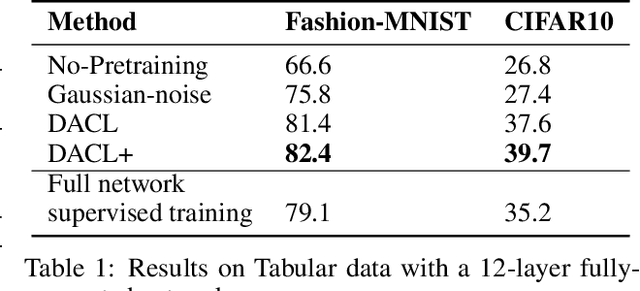
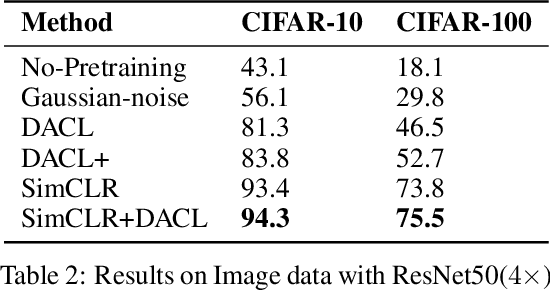
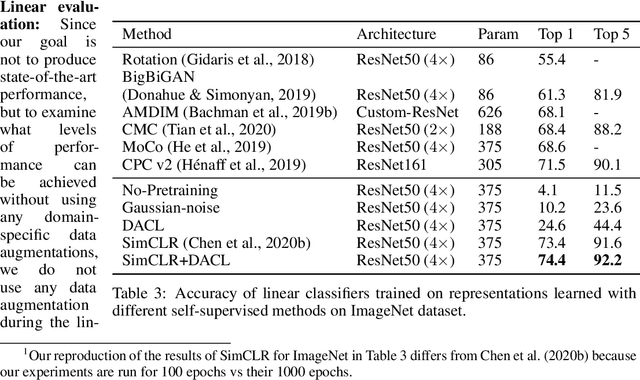

Despite recent success, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a novel domain-agnostic approach to contrastive learning, named DACL, that is applicable to domains where invariances, and thus, data augmentation techniques, are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning. Finally, we theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach.
PatchUp: A Regularization Technique for Convolutional Neural Networks
Jun 14, 2020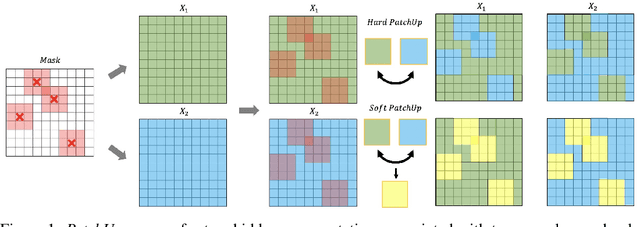
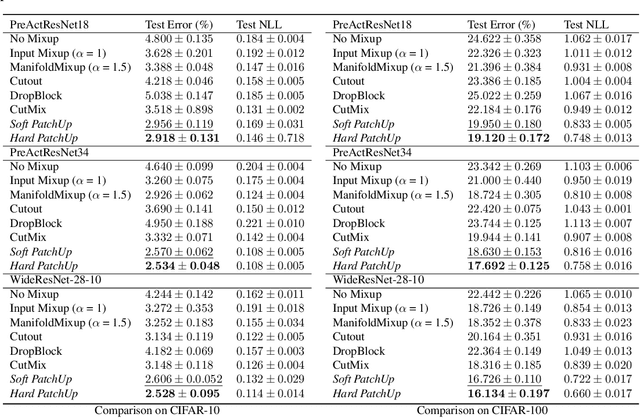
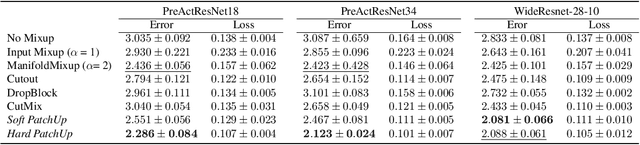
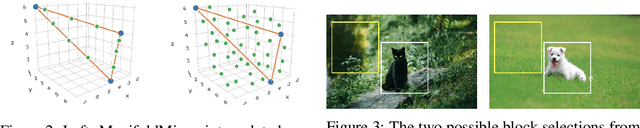
Large capacity deep learning models are often prone to a high generalization gap when trained with a limited amount of labeled training data. A recent class of methods to address this problem uses various ways to construct a new training sample by mixing a pair (or more) of training samples. We propose PatchUp, a hidden state block-level regularization technique for Convolutional Neural Networks (CNNs), that is applied on selected contiguous blocks of feature maps from a random pair of samples. Our approach improves the robustness of CNN models against the manifold intrusion problem that may occur in other state-of-the-art mixing approaches like Mixup and CutMix. Moreover, since we are mixing the contiguous block of features in the hidden space, which has more dimensions than the input space, we obtain more diverse samples for training towards different dimensions. Our experiments on CIFAR-10, CIFAR-100, and SVHN datasets with PreactResnet18, PreactResnet34, and WideResnet-28-10 models show that PatchUp improves upon, or equals, the performance of current state-of-the-art regularizers for CNNs. We also show that PatchUp can provide better generalization to affine transformations of samples and is more robust against adversarial attacks.
Interpolation-based semi-supervised learning for object detection
Jun 03, 2020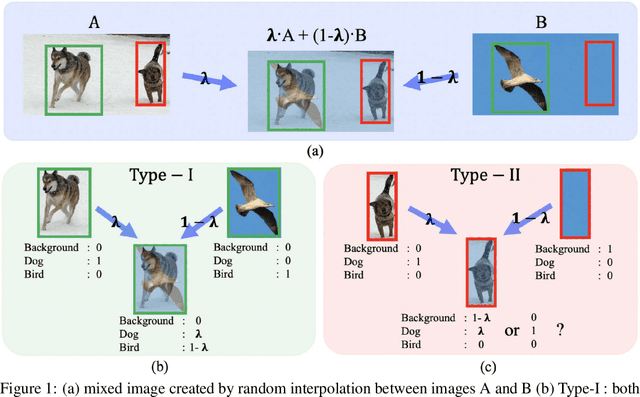
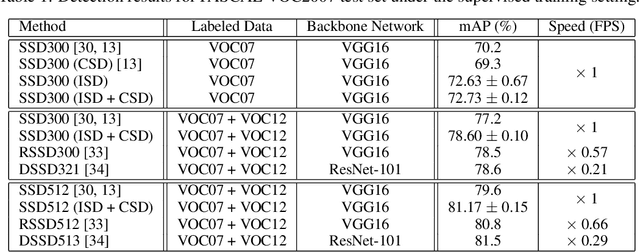

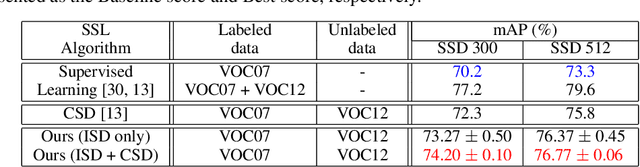
Despite the data labeling cost for the object detection tasks being substantially more than that of the classification tasks, semi-supervised learning methods for object detection have not been studied much. In this paper, we propose an Interpolation-based Semi-supervised learning method for object Detection (ISD), which considers and solves the problems caused by applying conventional Interpolation Regularization (IR) directly to object detection. We divide the output of the model into two types according to the objectness scores of both original patches that are mixed in IR. Then, we apply semi-supervised learning methods suitable for each type. This method dramatically improves the performance of semi-supervised learning as well as supervised learning. In the semi-supervised learning setting, our algorithm improves the current state-of-the-art performance on benchmark dataset (PASCAL VOC07 as labeled data and PASCAL VOC12 as unlabeled data) and benchmark architectures (SSD300 and SSD512). In the supervised learning setting, our method, trained with VOC07 as labeled data, improves the baseline methods by a significant margin, as well as shows better performance than the model that is trained using the previous state-of-the-art semi-supervised learning method using VOC07 as the labeled data and VOC12 + MSCOCO as the unlabeled data. Code is available at: https://github.com/soo89/ISD-SSD .
SketchTransfer: A Challenging New Task for Exploring Detail-Invariance and the Abstractions Learned by Deep Networks
Dec 25, 2019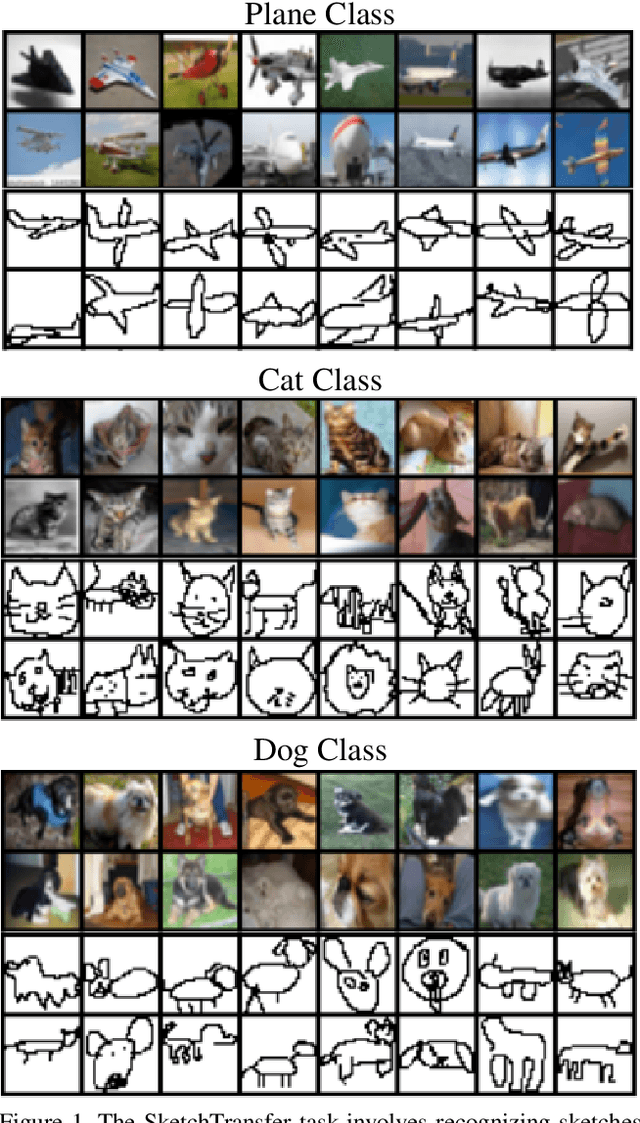

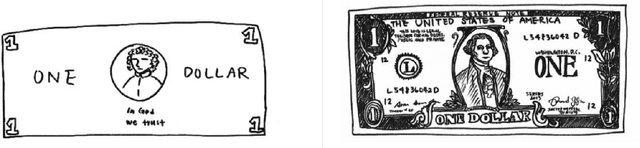
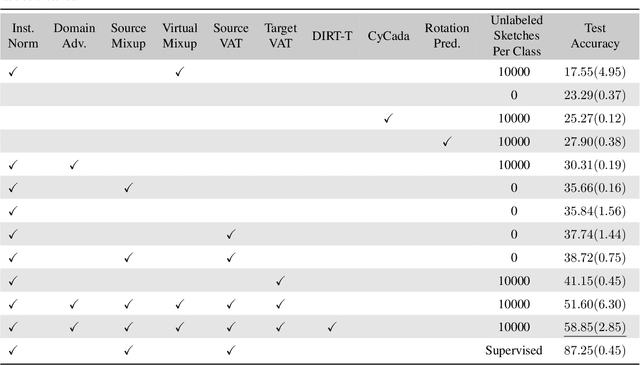
Deep networks have achieved excellent results in perceptual tasks, yet their ability to generalize to variations not seen during training has come under increasing scrutiny. In this work we focus on their ability to have invariance towards the presence or absence of details. For example, humans are able to watch cartoons, which are missing many visual details, without being explicitly trained to do so. As another example, 3D rendering software is a relatively recent development, yet people are able to understand such rendered scenes even though they are missing details (consider a film like Toy Story). The failure of machine learning algorithms to do this indicates a significant gap in generalization between human abilities and the abilities of deep networks. We propose a dataset that will make it easier to study the detail-invariance problem concretely. We produce a concrete task for this: SketchTransfer, and we show that state-of-the-art domain transfer algorithms still struggle with this task. The state-of-the-art technique which achieves over 95\% on MNIST $\xrightarrow{}$ SVHN transfer only achieves 59\% accuracy on the SketchTransfer task, which is much better than random (11\% accuracy) but falls short of the 87\% accuracy of a classifier trained directly on labeled sketches. This indicates that this task is approachable with today's best methods but has substantial room for improvement.
GraphMix: Regularized Training of Graph Neural Networks for Semi-Supervised Learning
Sep 25, 2019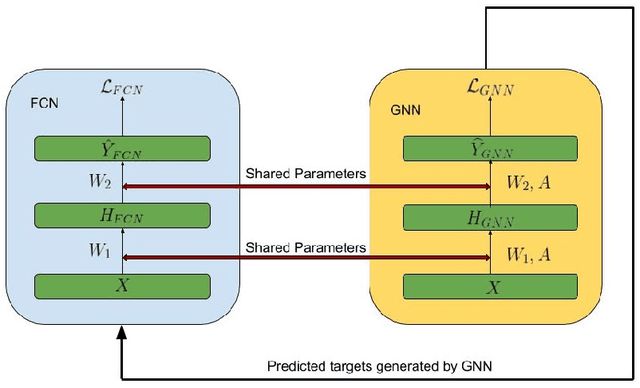
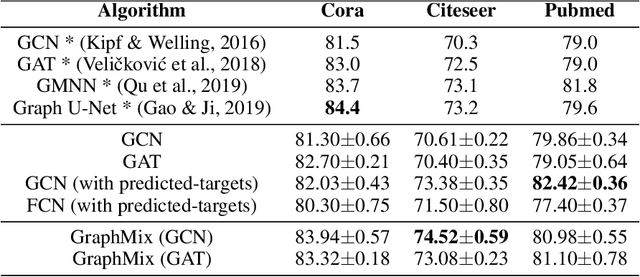

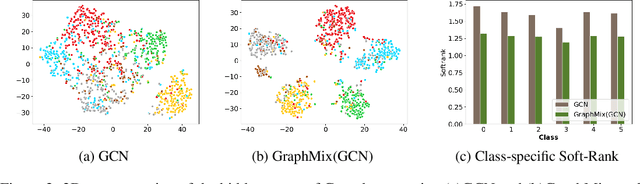
We present GraphMix, a regularization technique for Graph Neural Network based semi-supervised object classification, leveraging the recent advances in the regularization of classical deep neural networks. Specifically, we propose a unified approach in which we train a fully-connected network jointly with the graph neural network via parameter sharing, interpolation-based regularization, and self-predicted-targets. Our proposed method is architecture agnostic in the sense that it can be applied to any variant of graph neural networks which applies a parametric transformation to the features of the graph nodes. Despite its simplicity, with GraphMix we can consistently improve results and achieve or closely match state-of-the-art performance using even simpler architectures such as Graph Convolutional Networks, across three established graph benchmarks: the Cora, Citeseer and Pubmed citation network datasets, as well as three newly proposed datasets : Cora-Full, Co-author-CS and Co-author-Physics.
Towards Understanding Generalization in Gradient-Based Meta-Learning
Jul 16, 2019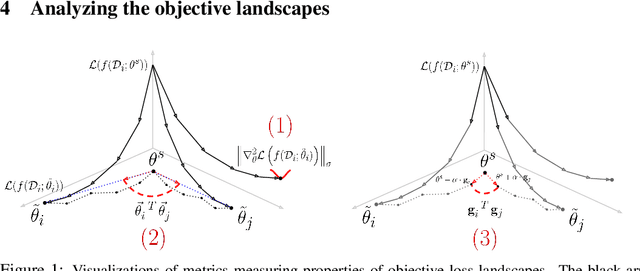
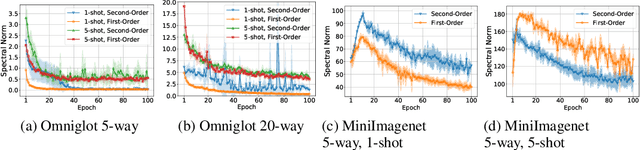
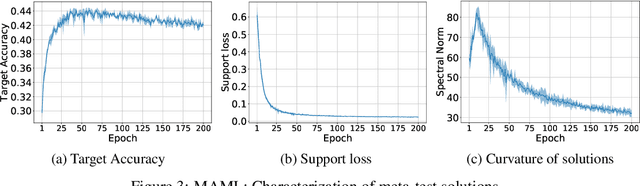
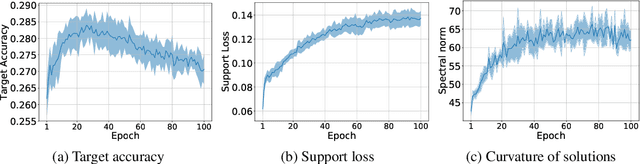
In this work we study generalization of neural networks in gradient-based meta-learning by analyzing various properties of the objective landscapes. We experimentally demonstrate that as meta-training progresses, the meta-test solutions, obtained after adapting the meta-train solution of the model, to new tasks via few steps of gradient-based fine-tuning, become flatter, lower in loss, and further away from the meta-train solution. We also show that those meta-test solutions become flatter even as generalization starts to degrade, thus providing an experimental evidence against the correlation between generalization and flat minima in the paradigm of gradient-based meta-leaning. Furthermore, we provide empirical evidence that generalization to new tasks is correlated with the coherence between their adaptation trajectories in parameter space, measured by the average cosine similarity between task-specific trajectory directions, starting from a same meta-train solution. We also show that coherence of meta-test gradients, measured by the average inner product between the task-specific gradient vectors evaluated at meta-train solution, is also correlated with generalization. Based on these observations, we propose a novel regularizer for MAML and provide experimental evidence for its effectiveness.