 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpolation-based semi-supervised learning for object detection
Jun 03, 2020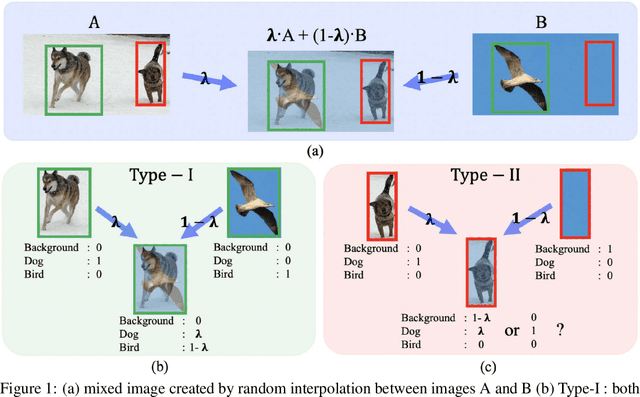
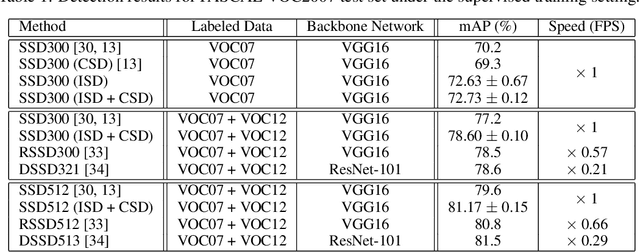

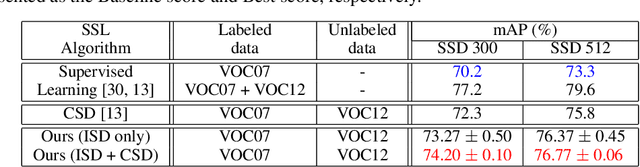
Despite the data labeling cost for the object detection tasks being substantially more than that of the classification tasks, semi-supervised learning methods for object detection have not been studied much. In this paper, we propose an Interpolation-based Semi-supervised learning method for object Detection (ISD), which considers and solves the problems caused by applying conventional Interpolation Regularization (IR) directly to object detection. We divide the output of the model into two types according to the objectness scores of both original patches that are mixed in IR. Then, we apply semi-supervised learning methods suitable for each type. This method dramatically improves the performance of semi-supervised learning as well as supervised learning. In the semi-supervised learning setting, our algorithm improves the current state-of-the-art performance on benchmark dataset (PASCAL VOC07 as labeled data and PASCAL VOC12 as unlabeled data) and benchmark architectures (SSD300 and SSD512). In the supervised learning setting, our method, trained with VOC07 as labeled data, improves the baseline methods by a significant margin, as well as shows better performance than the model that is trained using the previous state-of-the-art semi-supervised learning method using VOC07 as the labeled data and VOC12 + MSCOCO as the unlabeled data. Code is available at: https://github.com/soo89/ISD-SSD .
Class-Imbalanced Semi-Supervised Learning
Feb 17, 2020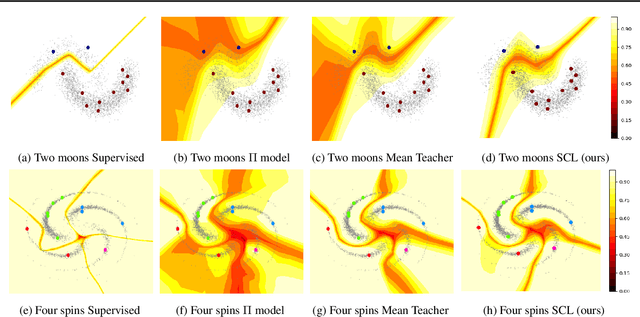
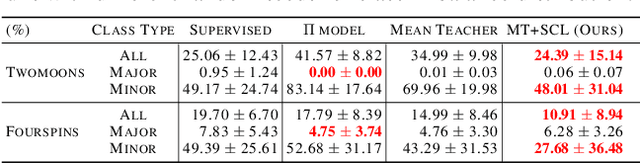
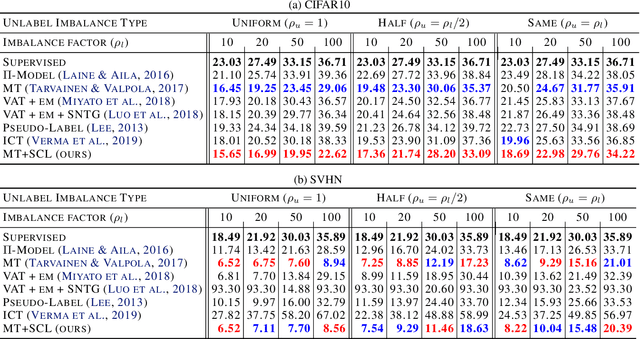
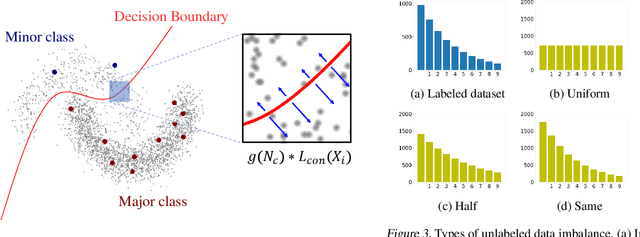
Semi-Supervised Learning (SSL) has achieved great success in overcoming the difficulties of labeling and making full use of unlabeled data. However, SSL has a limited assumption that the numbers of samples in different classes are balanced, and many SSL algorithms show lower performance for the datasets with the imbalanced class distribution. In this paper, we introduce a task of class-imbalanced semi-supervised learning (CISSL), which refers to semi-supervised learning with class-imbalanced data. In doing so, we consider class imbalance in both labeled and unlabeled sets. First, we analyze existing SSL methods in imbalanced environments and examine how the class imbalance affects SSL methods. Then we propose Suppressed Consistency Loss (SCL), a regularization method robust to class imbalance. Our method shows better performance than the conventional methods in the CISSL environment. In particular, the more severe the class imbalance and the smaller the size of the labeled data, the better our method performs.
Feature Fusion for Online Mutual Knowledge Distillation
Apr 19, 2019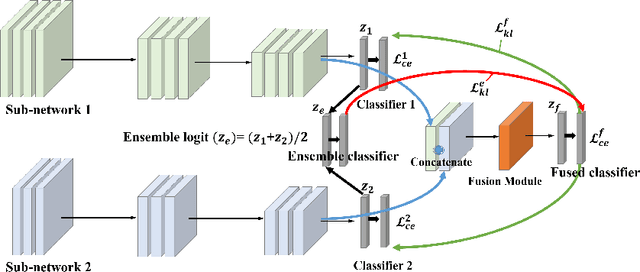
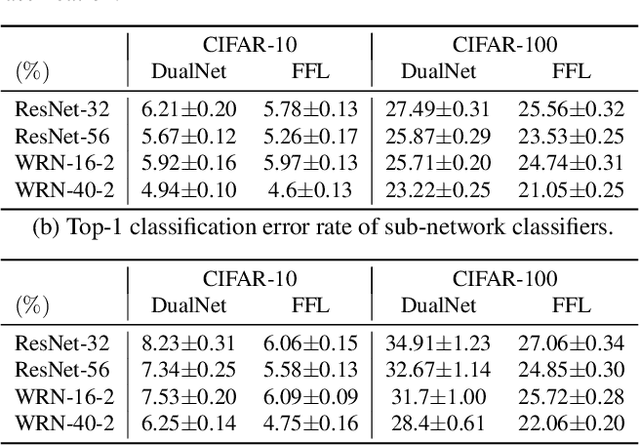

We propose a learning framework named Feature Fusion Learning (FFL) that efficiently trains a powerful classifier through a fusion module which combines the feature maps generated from parallel neural networks. Specifically, we train a number of parallel neural networks as sub-networks, then we combine the feature maps from each sub-network using a fusion module to create a more meaningful feature map. The fused feature map is passed into the fused classifier for overall classification. Unlike existing feature fusion methods, in our framework, an ensemble of sub-network classifiers transfers its knowledge to the fused classifier and then the fused classifier delivers its knowledge back to each sub-network, mutually teaching one another in an online-knowledge distillation manner. This mutually teaching system not only improves the performance of the fused classifier but also obtains performance gain in each sub-network. Moreover, our model is more beneficial because different types of network can be used for each sub-network. We have performed a variety of experiments on multiple datasets such as CIFAR-10, CIFAR-100 and ImageNet and proved that our method is more effective than other alternative methods in terms of performance of both sub-networks and the fused classifier.
Disentangling Options with Hellinger Distance Regularizer
Apr 15, 2019
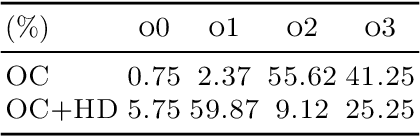
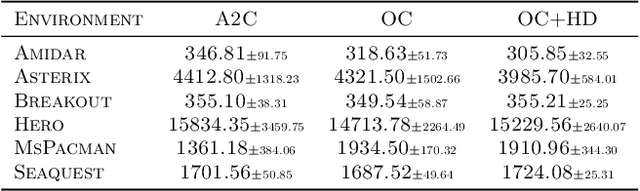
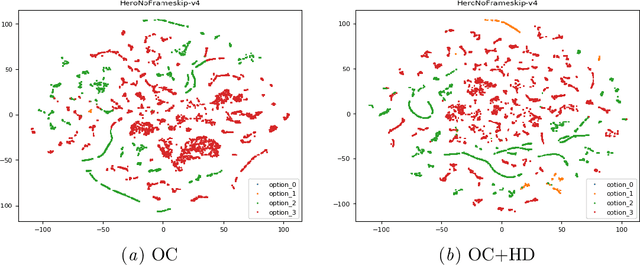
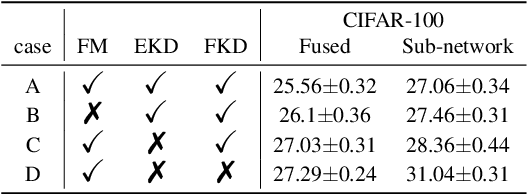
In reinforcement learning (RL), temporal abstraction still remains as an important and unsolved problem. The options framework provided clues to temporal abstraction in the RL, and the option-critic architecture elegantly solved the two problems of finding options and learning RL agents in an end-to-end manner. However, it is necessary to examine whether the options learned through this method play a mutually exclusive role. In this paper, we propose a Hellinger distance regularizer, a method for disentangling options. In addition, we will shed light on various indicators from the statistical point of view to compare with the options learned through the existing option-critic architecture.
Task-oriented Design through Deep Reinforcement Learning
Mar 13, 2019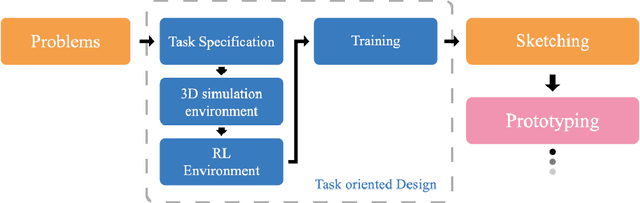



We propose a new low-cost machine-learning-based methodology which assists designers in reducing the gap between the problem and the solution in the design process. Our work applies reinforcement learning (RL) to find the optimal task-oriented design solution through the construction of the design action for each task. For this task-oriented design, the 3D design process in product design is assigned to an action space in Deep RL, and the desired 3D model is obtained by training each design action according to the task. By showing that this method achieves satisfactory design even when applied to a task pursuing multiple goals, we suggest the direction of how machine learning can contribute to the design process. Also, we have validated with product designers that this methodology can assist the creative part in the process of design.
Towards Governing Agent's Efficacy: Action-Conditional $β$-VAE for Deep Transparent Reinforcement Learning
Nov 11, 2018

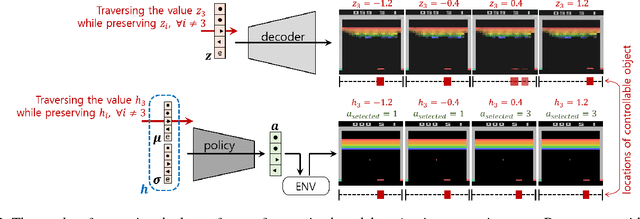

We tackle the blackbox issue of deep neural networks in the settings of reinforcement learning (RL) where neural agents learn towards maximizing reward gains in an uncontrollable way. Such learning approach is risky when the interacting environment includes an expanse of state space because it is then almost impossible to foresee all unwanted outcomes and penalize them with negative rewards beforehand. Unlike reverse analysis of learned neural features from previous works, our proposed method \nj{tackles the blackbox issue by encouraging} an RL policy network to learn interpretable latent features through an implementation of a disentangled representation learning method. Toward this end, our method allows an RL agent to understand self-efficacy by distinguishing its influences from uncontrollable environmental factors, which closely resembles the way humans understand their scenes. Our experimental results show that the learned latent factors not only are interpretable, but also enable modeling the distribution of entire visited state space with a specific action condition. We have experimented that this characteristic of the proposed structure can lead to ex post facto governance for desired behaviors of RL agents.