 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me What They're Holding: Weakly-supervised Object Detection with Transferable Knowledge from Human-object Interaction
Nov 19, 2019


In this work, we introduce a novel weakly supervised object detection (WSOD) paradigm to detect objects belonging to rare classes that have not many examples using transferable knowledge from human-object interactions (HOI). While WSOD shows lower performance than full supervision, we mainly focus on HOI as the main context which can strongly supervise complex semantics in images. Therefore, we propose a novel module called RRPN (relational region proposal network) which outputs an object-localizing attention map only with human poses and action verbs. In the source domain, we fully train an object detector and the RRPN with full supervision of HOI. With transferred knowledge about localization map from the trained RRPN, a new object detector can learn unseen objects with weak verbal supervision of HOI without bounding box annotations in the target domain. Because the RRPN is designed as an add-on type, we can apply it not only to the object detection but also to other domains such as semantic segmentation. The experimental results on HICO-DET dataset show the possibility that the proposed method can be a cheap alternative for the current supervised object detection paradigm. Moreover, qualitative results demonstrate that our model can properly localize unseen objects on HICO-DET and V-COCO datasets.
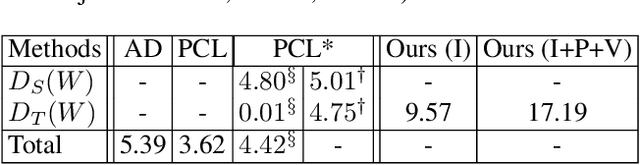
Towards Governing Agent's Efficacy: Action-Conditional $β$-VAE for Deep Transparent Reinforcement Learning
Nov 11, 2018

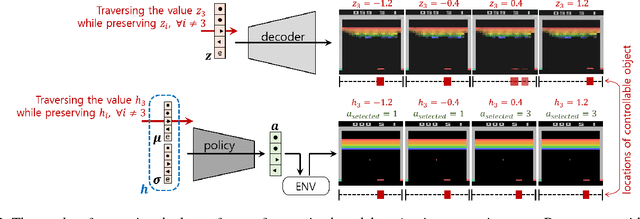

We tackle the blackbox issue of deep neural networks in the settings of reinforcement learning (RL) where neural agents learn towards maximizing reward gains in an uncontrollable way. Such learning approach is risky when the interacting environment includes an expanse of state space because it is then almost impossible to foresee all unwanted outcomes and penalize them with negative rewards beforehand. Unlike reverse analysis of learned neural features from previous works, our proposed method \nj{tackles the blackbox issue by encouraging} an RL policy network to learn interpretable latent features through an implementation of a disentangled representation learning method. Toward this end, our method allows an RL agent to understand self-efficacy by distinguishing its influences from uncontrollable environmental factors, which closely resembles the way humans understand their scenes. Our experimental results show that the learned latent factors not only are interpretable, but also enable modeling the distribution of entire visited state space with a specific action condition. We have experimented that this characteristic of the proposed structure can lead to ex post facto governance for desired behaviors of RL agents.