Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Options with Hellinger Distance Regularizer
Paper and Code
Apr 15, 2019
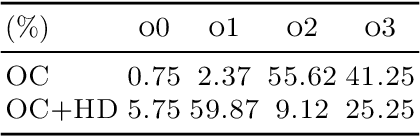
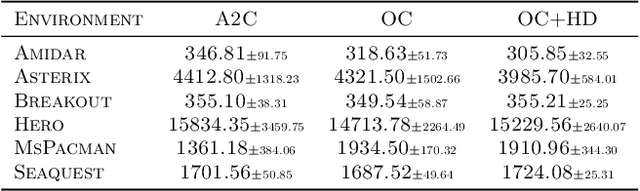
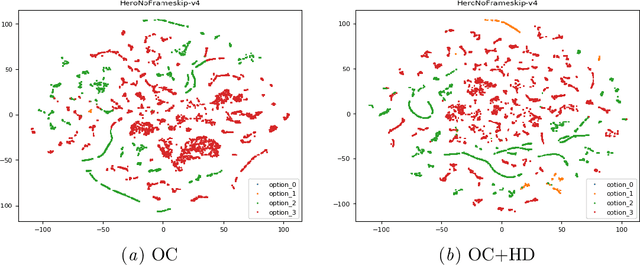
In reinforcement learning (RL), temporal abstraction still remains as an important and unsolved problem. The options framework provided clues to temporal abstraction in the RL, and the option-critic architecture elegantly solved the two problems of finding options and learning RL agents in an end-to-end manner. However, it is necessary to examine whether the options learned through this method play a mutually exclusive role. In this paper, we propose a Hellinger distance regularizer, a method for disentangling options. In addition, we will shed light on various indicators from the statistical point of view to compare with the options learned through the existing option-critic architecture.
View paper on