 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTet: Multi-domain Translation for English and Vietnamese
Oct 19, 2022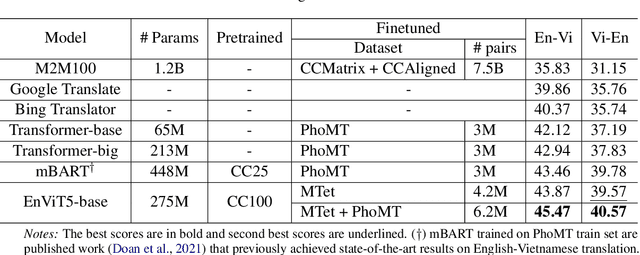
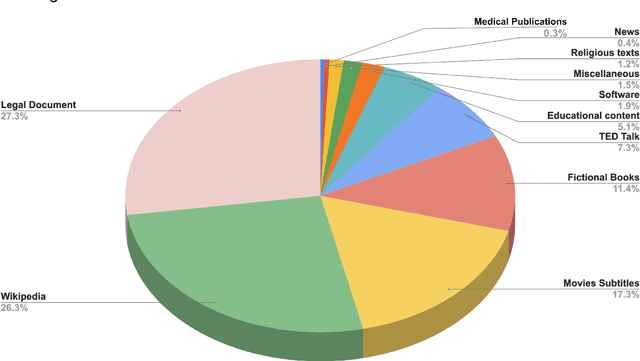

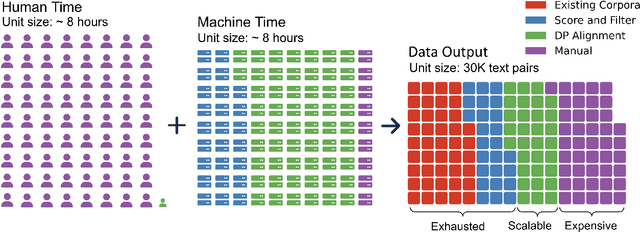
We introduce MTet, the largest publicly available parallel corpus for English-Vietnamese translation. MTet consists of 4.2M high-quality training sentence pairs and a multi-domain test set refined by the Vietnamese research community. Combining with previous works on English-Vietnamese translation, we grow the existing parallel dataset to 6.2M sentence pairs. We also release the first pretrained model EnViT5 for English and Vietnamese languages. Combining both resources, our model significantly outperforms previous state-of-the-art results by up to 2 points in translation BLEU score, while being 1.6 times smaller.
Combined Scaling for Zero-shot Transfer Learning
Nov 19, 2021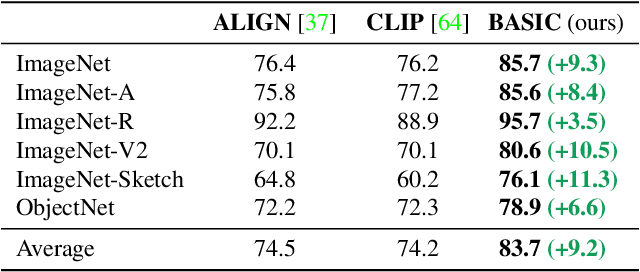
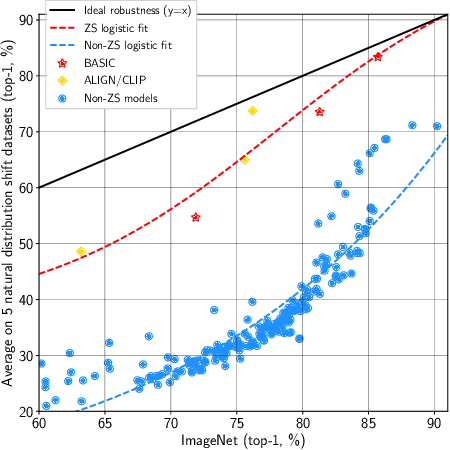
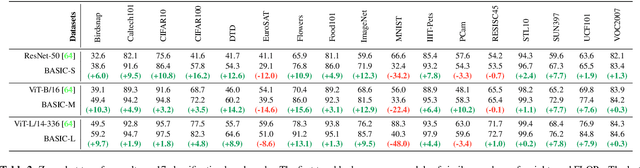

We present a combined scaling method called BASIC that achieves 85.7% top-1 zero-shot accuracy on the ImageNet ILSVRC-2012 validation set, surpassing the best-published zero-shot models - CLIP and ALIGN - by 9.3%. Our BASIC model also shows significant improvements in robustness benchmarks. For instance, on 5 test sets with natural distribution shifts such as ImageNet-{A,R,V2,Sketch} and ObjectNet, our model achieves 83.7% top-1 average accuracy, only a small drop from the its original ImageNet accuracy. To achieve these results, we scale up the contrastive learning framework of CLIP and ALIGN in three dimensions: data size, model size, and batch size. Our dataset has 6.6B noisy image-text pairs, which is 4x larger than ALIGN, and 16x larger than CLIP. Our largest model has 3B weights, which is 3.75x larger in parameters and 8x larger in FLOPs than ALIGN and CLIP. Our batch size is 65536 which is 2x more than CLIP and 4x more than ALIGN. The main challenge with scaling is the limited memory of our accelerators such as GPUs and TPUs. We hence propose a simple method of online gradient caching to overcome this limit.
Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference
Sep 24, 2021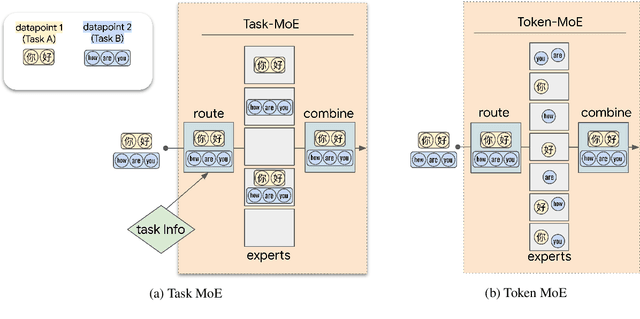
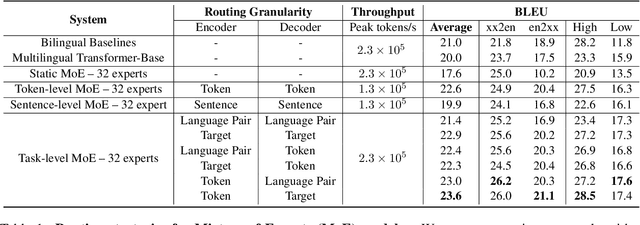
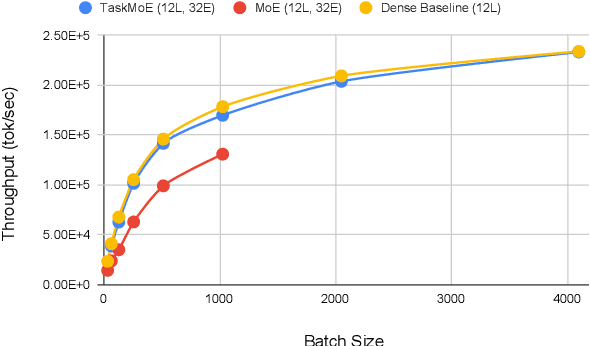

Sparse Mixture-of-Experts (MoE) has been a successful approach for scaling multilingual translation models to billions of parameters without a proportional increase in training computation. However, MoE models are prohibitively large and practitioners often resort to methods such as distillation for serving. In this work, we investigate routing strategies at different granularity (token, sentence, task) in MoE models to bypass distillation. Experiments on WMT and a web-scale dataset suggest that task-level routing (task-MoE) enables us to extract smaller, ready-to-deploy sub-networks from large sparse models. On WMT, our task-MoE with 32 experts (533M parameters) outperforms the best performing token-level MoE model (token-MoE) by +1.0 BLEU on average across 30 language pairs. The peak inference throughput is also improved by a factor of 1.9x when we route by tasks instead of tokens. While distilling a token-MoE to a smaller dense model preserves only 32% of the BLEU gains, our sub-network task-MoE, by design, preserves all the gains with the same inference cost as the distilled student model. Finally, when scaling up to 200 language pairs, our 128-expert task-MoE (13B parameters) performs competitively with a token-level counterpart, while improving the peak inference throughput by a factor of 2.6x.
STraTA: Self-Training with Task Augmentation for Better Few-shot Learning
Sep 13, 2021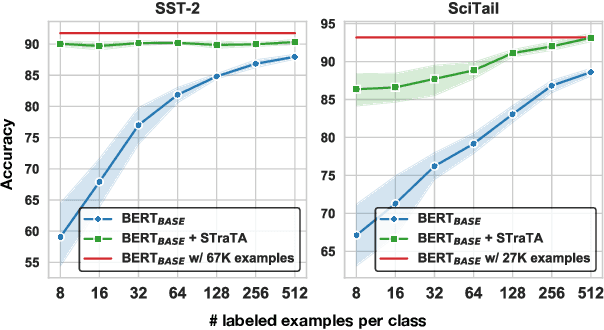
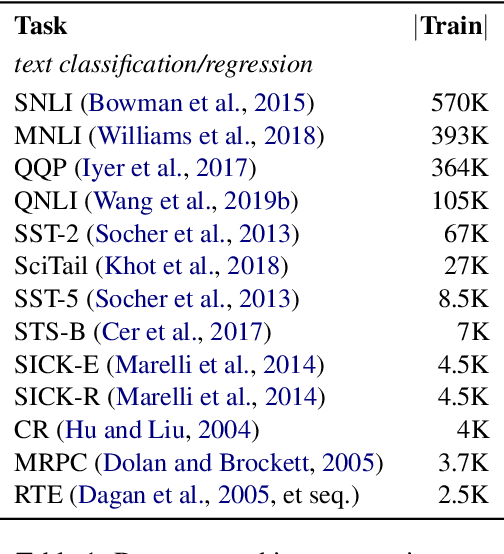
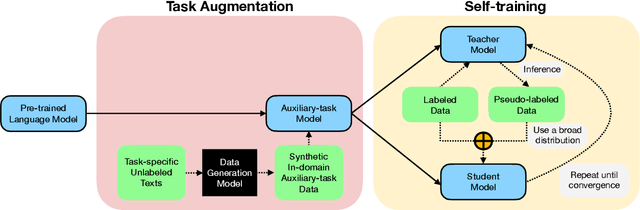
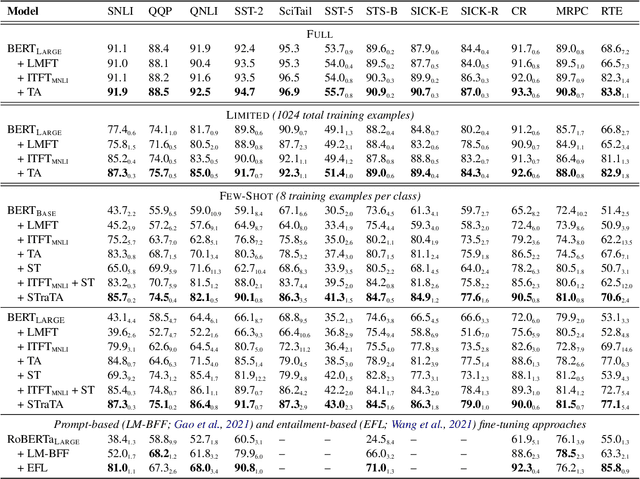
Despite their recent successes in tackling many NLP tasks, large-scale pre-trained language models do not perform as well in few-shot settings where only a handful of training examples are available. To address this shortcoming, we propose STraTA, which stands for Self-Training with Task Augmentation, an approach that builds on two key ideas for effective leverage of unlabeled data. First, STraTA uses task augmentation, a novel technique that synthesizes a large amount of data for auxiliary-task fine-tuning from target-task unlabeled texts. Second, STraTA performs self-training by further fine-tuning the strong base model created by task augmentation on a broad distribution of pseudo-labeled data. Our experiments demonstrate that STraTA can substantially improve sample efficiency across 12 few-shot benchmarks. Remarkably, on the SST-2 sentiment dataset, STraTA, with only 8 training examples per class, achieves comparable results to standard fine-tuning with 67K training examples. Our analyses reveal that task augmentation and self-training are both complementary and independently effective.
Pre-Training Transformers as Energy-Based Cloze Models
Dec 15, 2020
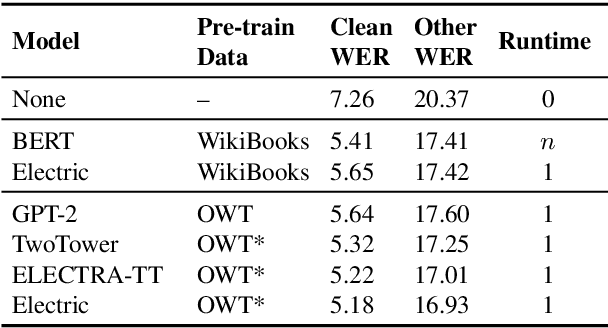
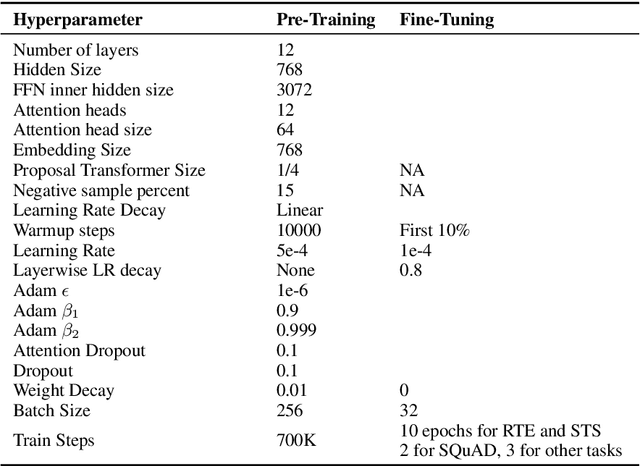
We introduce Electric, an energy-based cloze model for representation learning over text. Like BERT, it is a conditional generative model of tokens given their contexts. However, Electric does not use masking or output a full distribution over tokens that could occur in a context. Instead, it assigns a scalar energy score to each input token indicating how likely it is given its context. We train Electric using an algorithm based on noise-contrastive estimation and elucidate how this learning objective is closely related to the recently proposed ELECTRA pre-training method. Electric performs well when transferred to downstream tasks and is particularly effective at producing likelihood scores for text: it re-ranks speech recognition n-best lists better than language models and much faster than masked language models. Furthermore, it offers a clearer and more principled view of what ELECTRA learns during pre-training.
Towards Domain-Agnostic Contrastive Learning
Nov 09, 2020
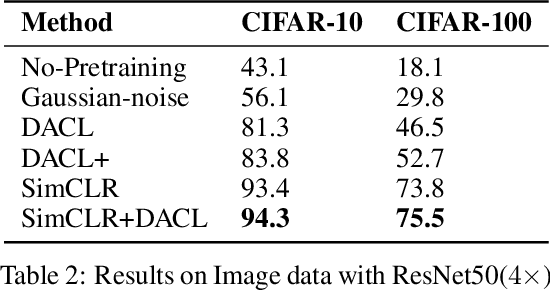
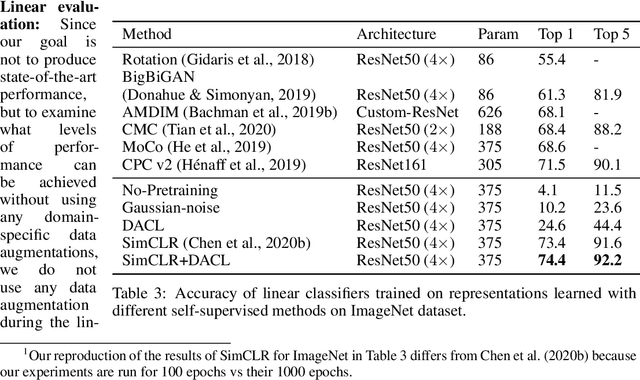

Despite recent success, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a novel domain-agnostic approach to contrastive learning, named DACL, that is applicable to domains where invariances, and thus, data augmentation techniques, are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning. Finally, we theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach.
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
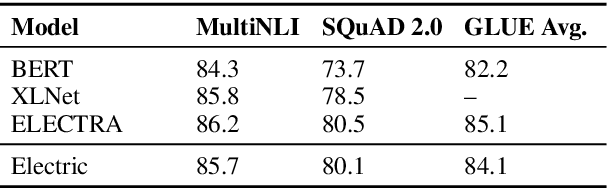
Mar 23, 2020Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, they generally require large amounts of compute to be effective. As an alternative, we propose a more sample-efficient pre-training task called replaced token detection. Instead of masking the input, our approach corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network. Then, instead of training a model that predicts the original identities of the corrupted tokens, we train a discriminative model that predicts whether each token in the corrupted input was replaced by a generator sample or not. Thorough experiments demonstrate this new pre-training task is more efficient than MLM because the task is defined over all input tokens rather than just the small subset that was masked out. As a result, the contextual representations learned by our approach substantially outperform the ones learned by BERT given the same model size, data, and compute. The gains are particularly strong for small models; for example, we train a model on one GPU for 4 days that outperforms GPT (trained using 30x more compute) on the GLUE natural language understanding benchmark. Our approach also works well at scale, where it performs comparably to RoBERTa and XLNet while using less than 1/4 of their compute and outperforms them when using the same amount of compute.
Towards a Human-like Open-Domain Chatbot
Feb 27, 2020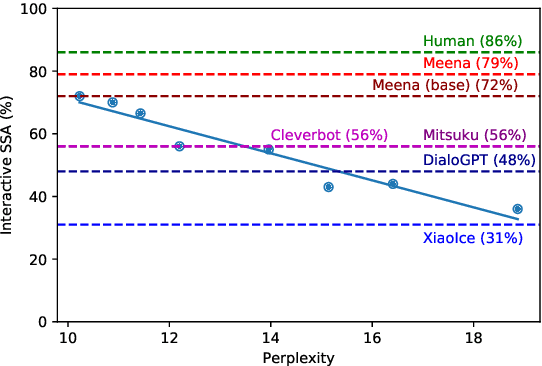

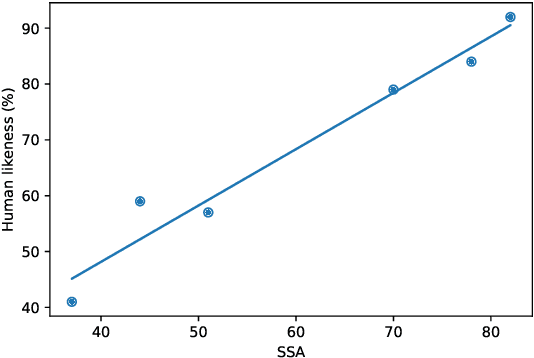

We present Meena, a multi-turn open-domain chatbot trained end-to-end on data mined and filtered from public domain social media conversations. This 2.6B parameter neural network is simply trained to minimize perplexity of the next token. We also propose a human evaluation metric called Sensibleness and Specificity Average (SSA), which captures key elements of a human-like multi-turn conversation. Our experiments show strong correlation between perplexity and SSA. The fact that the best perplexity end-to-end trained Meena scores high on SSA (72% on multi-turn evaluation) suggests that a human-level SSA of 86% is potentially within reach if we can better optimize perplexity. Additionally, the full version of Meena (with a filtering mechanism and tuned decoding) scores 79% SSA, 23% higher in absolute SSA than the existing chatbots we evaluated.
A Hybrid Morpheme-Word Representation for Machine Translation of Morphologically Rich Languages
Nov 19, 2019
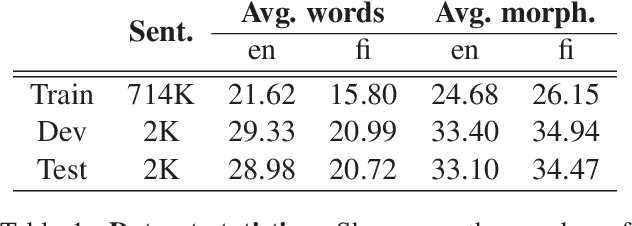

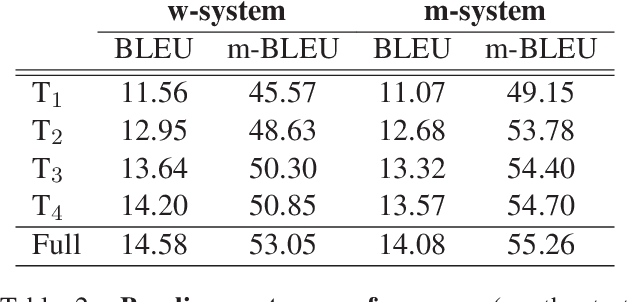
We propose a language-independent approach for improving statistical machine translation for morphologically rich languages using a hybrid morpheme-word representation where the basic unit of translation is the morpheme, but word boundaries are respected at all stages of the translation process. Our model extends the classic phrase-based model by means of (1) word boundary-aware morpheme-level phrase extraction, (2) minimum error-rate training for a morpheme-level translation model using word-level BLEU, and (3) joint scoring with morpheme- and word-level language models. Further improvements are achieved by combining our model with the classic one. The evaluation on English to Finnish using Europarl (714K sentence pairs; 15.5M English words) shows statistically significant improvements over the classic model based on BLEU and human judgments.
Self-training with Noisy Student improves ImageNet classification
Nov 11, 2019
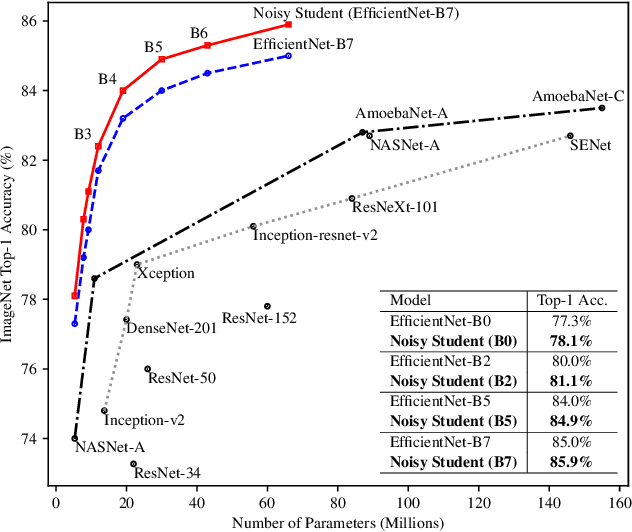
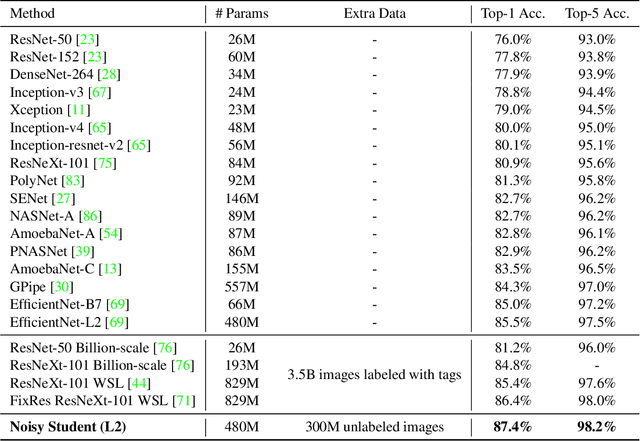

We present a simple self-training method that achieves 87.4% top-1 accuracy on ImageNet, which is 1.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 16.6% to 74.2%, reduces ImageNet-C mean corruption error from 45.7 to 31.2, and reduces ImageNet-P mean flip rate from 27.8 to 16.1. To achieve this result, we first train an EfficientNet model on labeled ImageNet images and use it as a teacher to generate pseudo labels on 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the generation of the pseudo labels, the teacher is not noised so that the pseudo labels are as good as possible. But during the learning of the student, we inject noise such as data augmentation, dropout, stochastic depth to the student so that the noised student is forced to learn harder from the pseudo labels.