 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024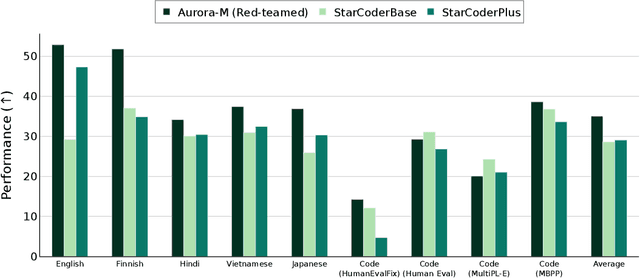

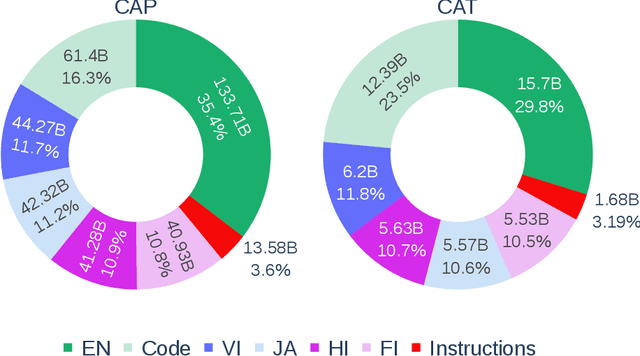
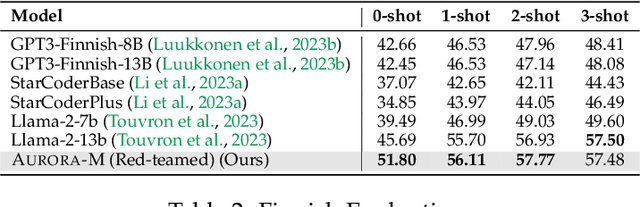
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
MTet: Multi-domain Translation for English and Vietnamese
Oct 19, 2022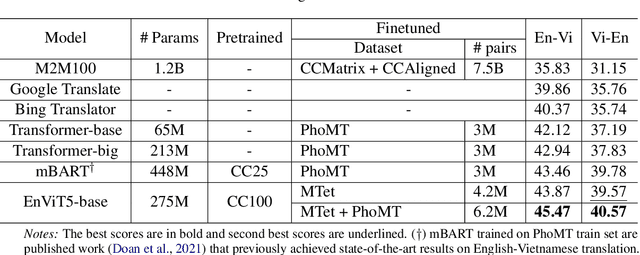
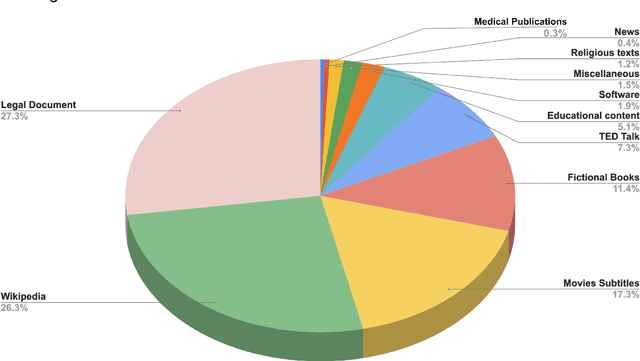

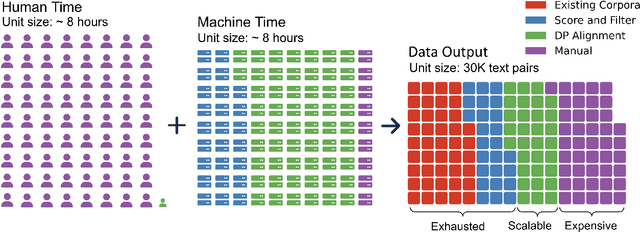
We introduce MTet, the largest publicly available parallel corpus for English-Vietnamese translation. MTet consists of 4.2M high-quality training sentence pairs and a multi-domain test set refined by the Vietnamese research community. Combining with previous works on English-Vietnamese translation, we grow the existing parallel dataset to 6.2M sentence pairs. We also release the first pretrained model EnViT5 for English and Vietnamese languages. Combining both resources, our model significantly outperforms previous state-of-the-art results by up to 2 points in translation BLEU score, while being 1.6 times smaller.
Enriching Biomedical Knowledge for Low-resource Language Through Translation
Oct 11, 2022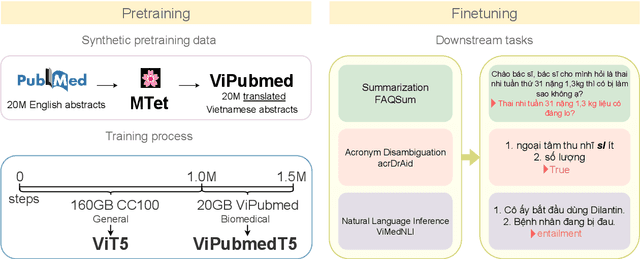
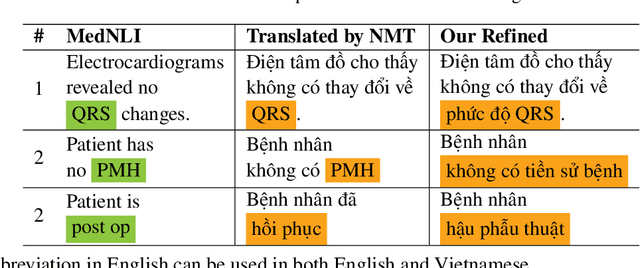

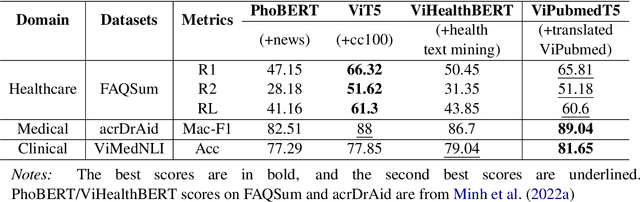
Biomedical data and benchmarks are highly valuable yet very limited in low-resource languages other than English such as Vietnamese. In this paper, we make use of a state-of-the-art translation model in English-Vietnamese to translate and produce both pretrained as well as supervised data in the biomedical domains. Thanks to such large-scale translation, we introduce ViPubmedT5, a pretrained Encoder-Decoder Transformer model trained on 20 million translated abstracts from the high-quality public PubMed corpus. ViPubMedT5 demonstrates state-of-the-art results on two different biomedical benchmarks in summarization and acronym disambiguation. Further, we release ViMedNLI - a new NLP task in Vietnamese translated from MedNLI using the recently public En-vi translation model and carefully refined by human experts, with evaluations of existing methods against ViPubmedT5.