Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTet: Multi-domain Translation for English and Vietnamese
Oct 19, 2022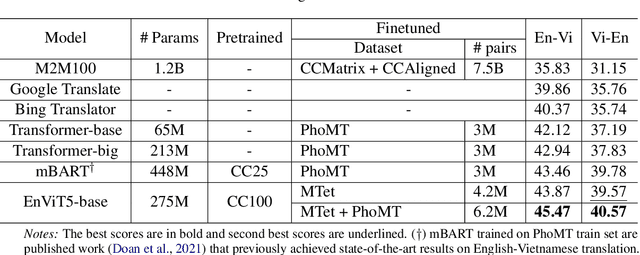
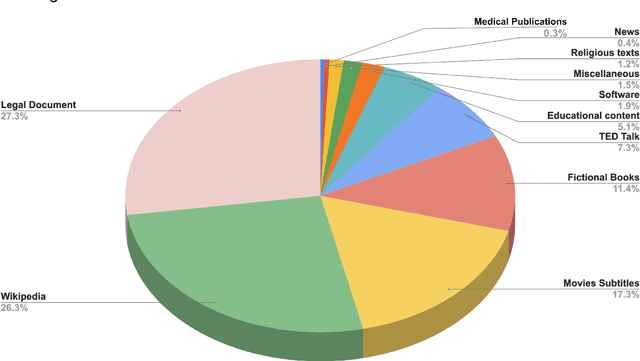

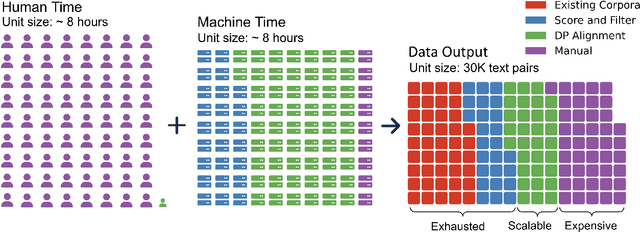
We introduce MTet, the largest publicly available parallel corpus for English-Vietnamese translation. MTet consists of 4.2M high-quality training sentence pairs and a multi-domain test set refined by the Vietnamese research community. Combining with previous works on English-Vietnamese translation, we grow the existing parallel dataset to 6.2M sentence pairs. We also release the first pretrained model EnViT5 for English and Vietnamese languages. Combining both resources, our model significantly outperforms previous state-of-the-art results by up to 2 points in translation BLEU score, while being 1.6 times smaller.
Via