 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoEmotions: A Dataset of Fine-Grained Emotions
Jun 03, 2020
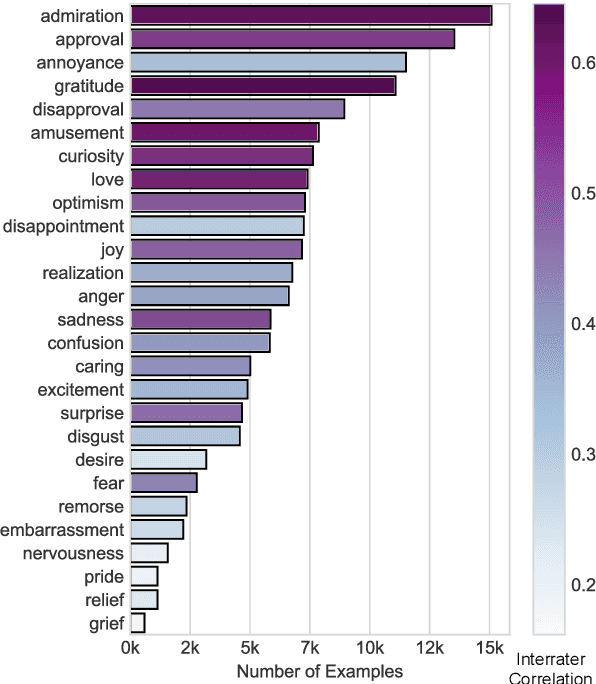
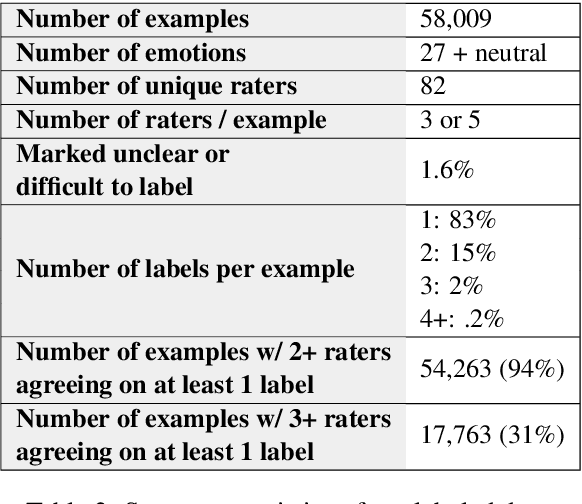

Understanding emotion expressed in language has a wide range of applications, from building empathetic chatbots to detecting harmful online behavior. Advancement in this area can be improved using large-scale datasets with a fine-grained typology, adaptable to multiple downstream tasks. We introduce GoEmotions, the largest manually annotated dataset of 58k English Reddit comments, labeled for 27 emotion categories or Neutral. We demonstrate the high quality of the annotations via Principal Preserved Component Analysis. We conduct transfer learning experiments with existing emotion benchmarks to show that our dataset generalizes well to other domains and different emotion taxonomies. Our BERT-based model achieves an average F1-score of .46 across our proposed taxonomy, leaving much room for improvement.
Towards a Human-like Open-Domain Chatbot
Feb 27, 2020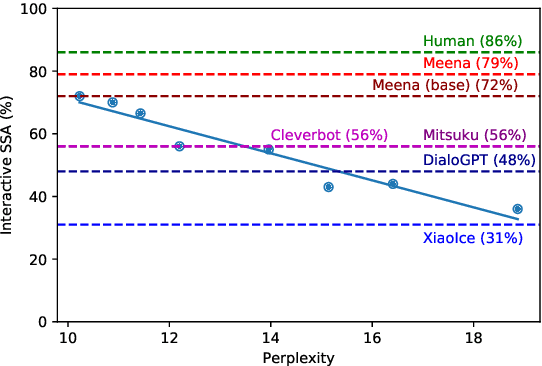

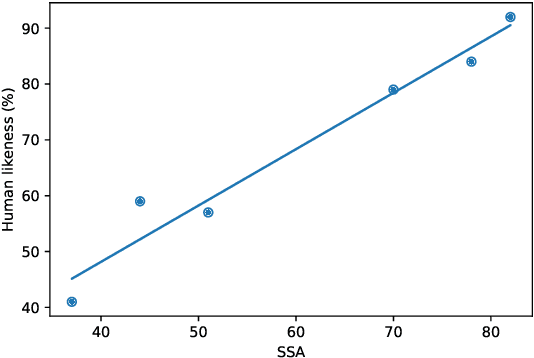

We present Meena, a multi-turn open-domain chatbot trained end-to-end on data mined and filtered from public domain social media conversations. This 2.6B parameter neural network is simply trained to minimize perplexity of the next token. We also propose a human evaluation metric called Sensibleness and Specificity Average (SSA), which captures key elements of a human-like multi-turn conversation. Our experiments show strong correlation between perplexity and SSA. The fact that the best perplexity end-to-end trained Meena scores high on SSA (72% on multi-turn evaluation) suggests that a human-level SSA of 86% is potentially within reach if we can better optimize perplexity. Additionally, the full version of Meena (with a filtering mechanism and tuned decoding) scores 79% SSA, 23% higher in absolute SSA than the existing chatbots we evaluated.