 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking generative image pretraining: How far are we from scaling up next-pixel prediction?
Nov 11, 2025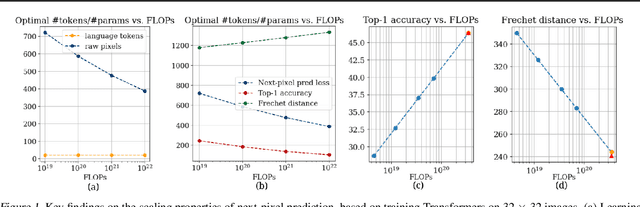
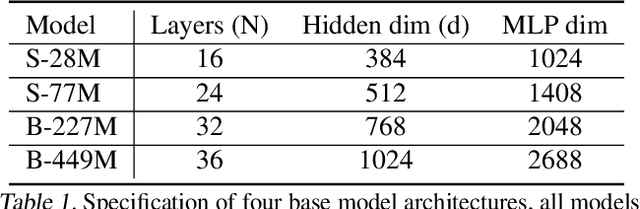

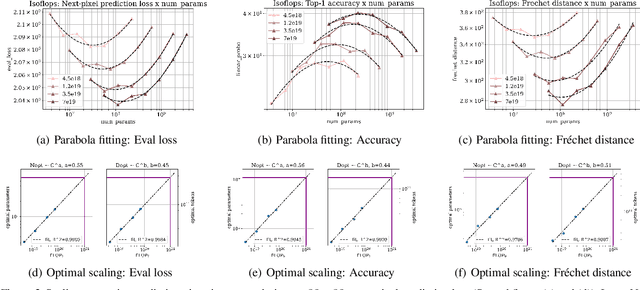
This paper investigates the scaling properties of autoregressive next-pixel prediction, a simple, end-to-end yet under-explored framework for unified vision models. Starting with images at resolutions of 32x32, we train a family of Transformers using IsoFlops profiles across compute budgets up to 7e19 FLOPs and evaluate three distinct target metrics: next-pixel prediction objective, ImageNet classification accuracy, and generation quality measured by Fr'echet Distance. First, optimal scaling strategy is critically task-dependent. At a fixed 32x32 resolution alone, the optimal scaling properties for image classification and image generation diverge, where generation optimal setup requires the data size grow three to five times faster than for the classification optimal setup. Second, as image resolution increases, the optimal scaling strategy indicates that the model size must grow much faster than data size. Surprisingly, by projecting our findings, we discover that the primary bottleneck is compute rather than the amount of training data. As compute continues to grow four to five times annually, we forecast the feasibility of pixel-by-pixel modeling of images within the next five years.
Large Language Models Cannot Self-Correct Reasoning Yet
Oct 03, 2023



Large Language Models (LLMs) have emerged as a groundbreaking technology with their unparalleled text generation capabilities across various applications. Nevertheless, concerns persist regarding the accuracy and appropriateness of their generated content. A contemporary methodology, self-correction, has been proposed as a remedy to these issues. Building upon this premise, this paper critically examines the role and efficacy of self-correction within LLMs, shedding light on its true potential and limitations. Central to our investigation is the notion of intrinsic self-correction, whereby an LLM attempts to correct its initial responses based solely on its inherent capabilities, without the crutch of external feedback. In the context of reasoning, our research indicates that LLMs struggle to self-correct their responses without external feedback, and at times, their performance might even degrade post self-correction. Drawing from these insights, we offer suggestions for future research and practical applications in this field.
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
May 24, 2023The mixture proportions of pretraining data domains (e.g., Wikipedia, books, web text) greatly affect language model (LM) performance. In this paper, we propose Domain Reweighting with Minimax Optimization (DoReMi), which first trains a small proxy model using group distributionally robust optimization (Group DRO) over domains to produce domain weights (mixture proportions) without knowledge of downstream tasks. We then resample a dataset with these domain weights and train a larger, full-sized model. In our experiments, we use DoReMi on a 280M-parameter proxy model to find domain weights for training an 8B-parameter model (30x larger) more efficiently. On The Pile, DoReMi improves perplexity across all domains, even when it downweights a domain. DoReMi improves average few-shot downstream accuracy by 6.5% points over a baseline model trained using The Pile's default domain weights and reaches the baseline accuracy with 2.6x fewer training steps. On the GLaM dataset, DoReMi, which has no knowledge of downstream tasks, even matches the performance of using domain weights tuned on downstream tasks.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022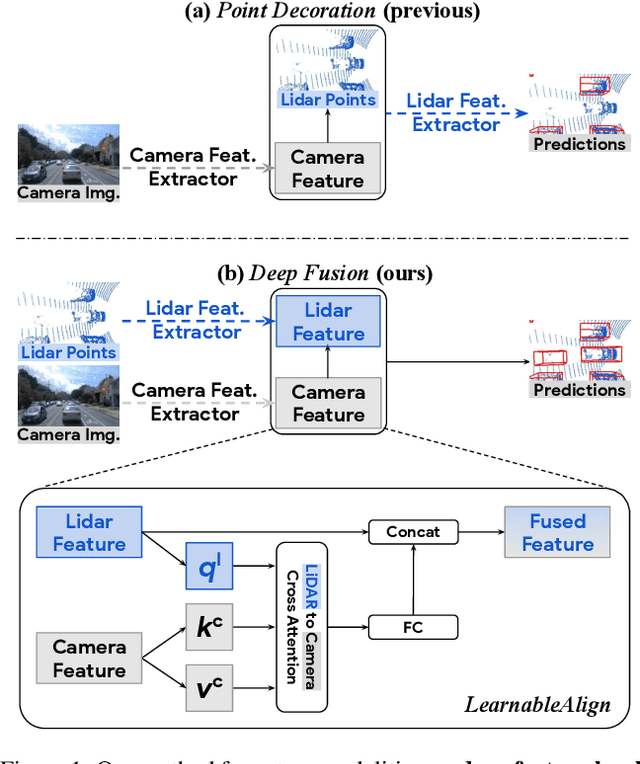
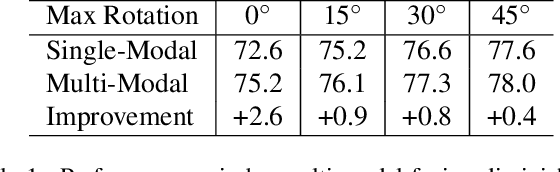
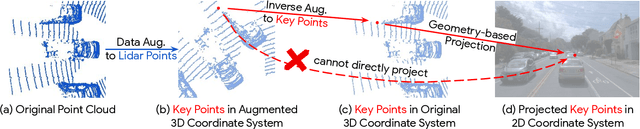
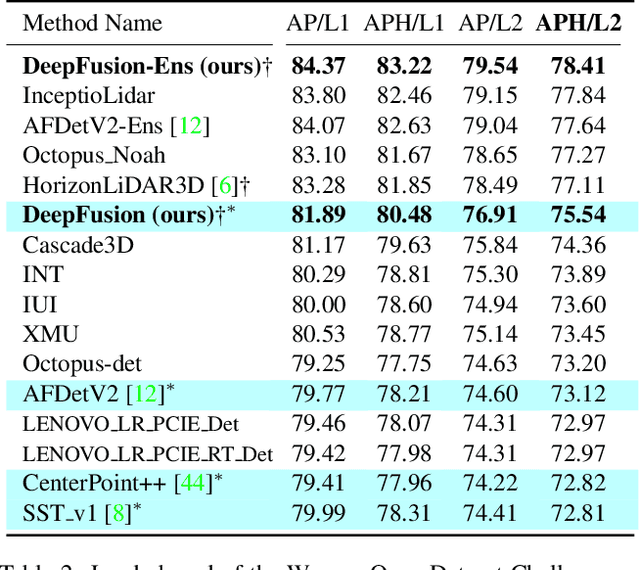
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021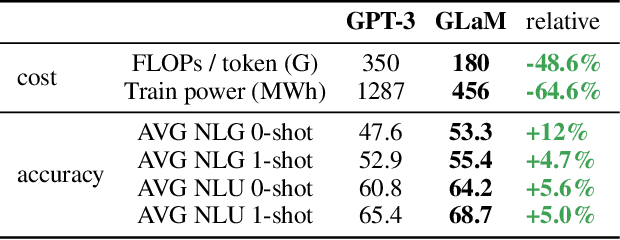
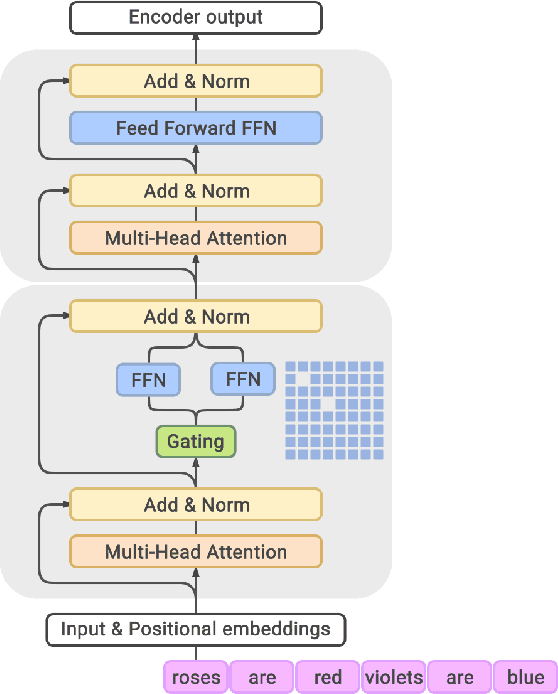
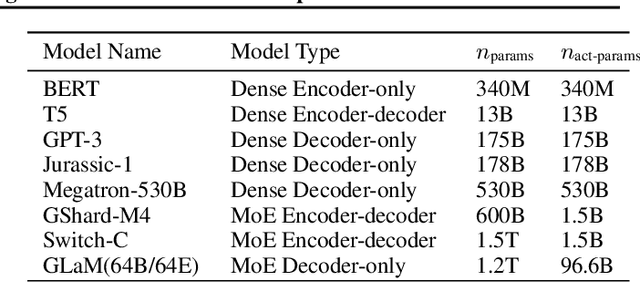
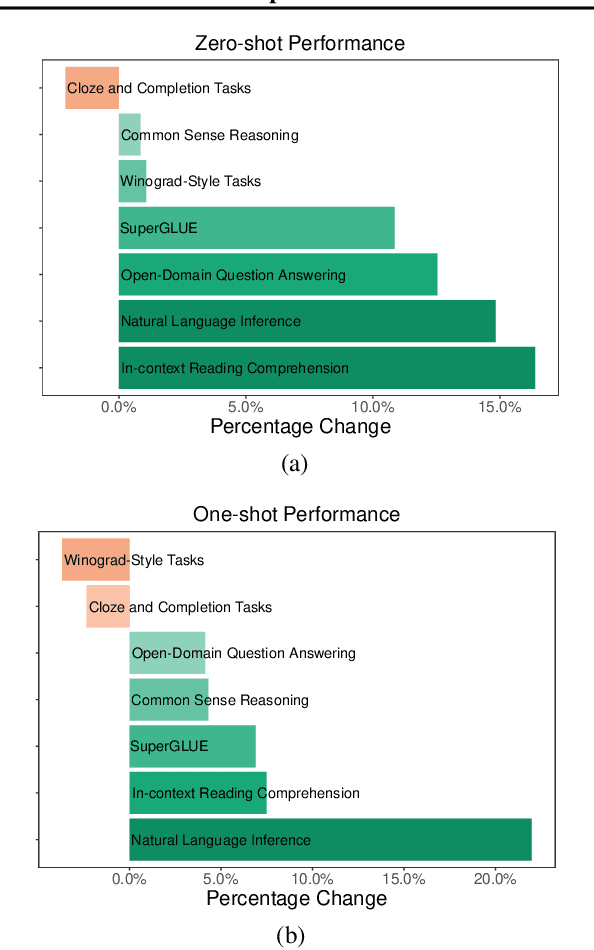
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
Combined Scaling for Zero-shot Transfer Learning
Nov 19, 2021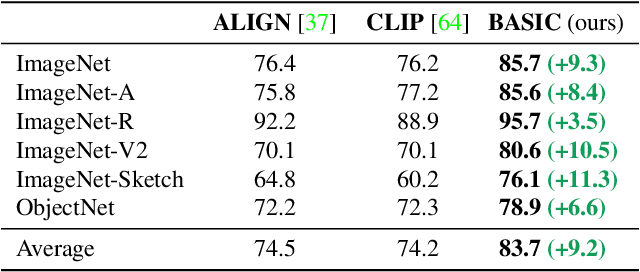
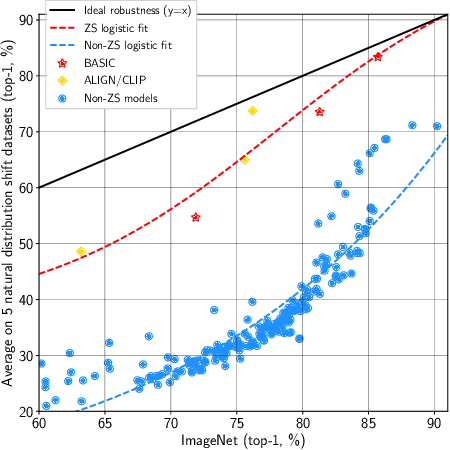
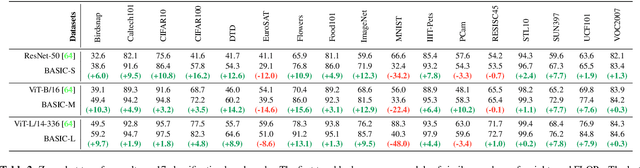

We present a combined scaling method called BASIC that achieves 85.7% top-1 zero-shot accuracy on the ImageNet ILSVRC-2012 validation set, surpassing the best-published zero-shot models - CLIP and ALIGN - by 9.3%. Our BASIC model also shows significant improvements in robustness benchmarks. For instance, on 5 test sets with natural distribution shifts such as ImageNet-{A,R,V2,Sketch} and ObjectNet, our model achieves 83.7% top-1 average accuracy, only a small drop from the its original ImageNet accuracy. To achieve these results, we scale up the contrastive learning framework of CLIP and ALIGN in three dimensions: data size, model size, and batch size. Our dataset has 6.6B noisy image-text pairs, which is 4x larger than ALIGN, and 16x larger than CLIP. Our largest model has 3B weights, which is 3.75x larger in parameters and 8x larger in FLOPs than ALIGN and CLIP. Our batch size is 65536 which is 2x more than CLIP and 4x more than ALIGN. The main challenge with scaling is the limited memory of our accelerators such as GPUs and TPUs. We hence propose a simple method of online gradient caching to overcome this limit.
Towards Zero-Label Language Learning
Sep 19, 2021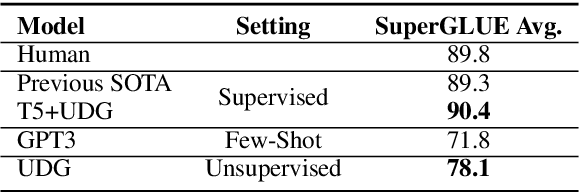
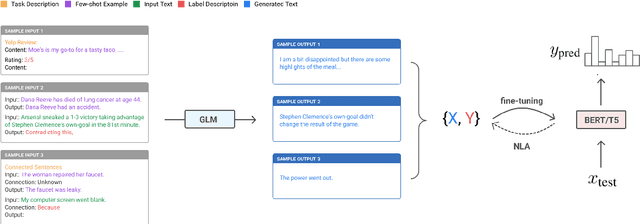
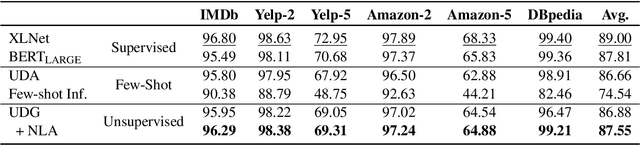
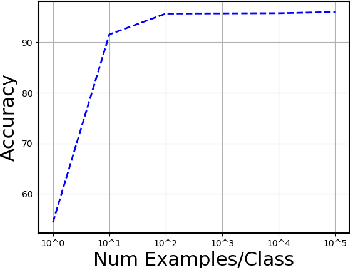
This paper explores zero-label learning in Natural Language Processing (NLP), whereby no human-annotated data is used anywhere during training and models are trained purely on synthetic data. At the core of our framework is a novel approach for better leveraging the powerful pretrained language models. Specifically, inspired by the recent success of few-shot inference on GPT-3, we present a training data creation procedure named Unsupervised Data Generation (UDG), which leverages few-shot prompts to synthesize high-quality training data without real human annotations. Our method enables zero-label learning as we train task-specific models solely on the synthetic data, yet we achieve better or comparable results from strong baseline models trained on human-labeled data. Furthermore, when mixed with labeled data, our approach serves as a highly effective data augmentation procedure, achieving new state-of-the-art results on the SuperGLUE benchmark.
Finetuned Language Models Are Zero-Shot Learners
Sep 03, 2021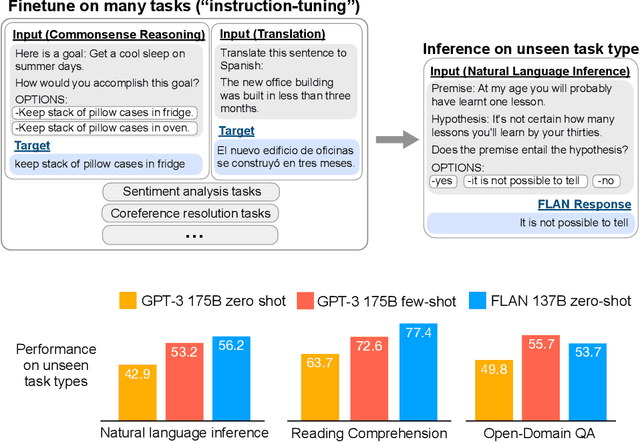
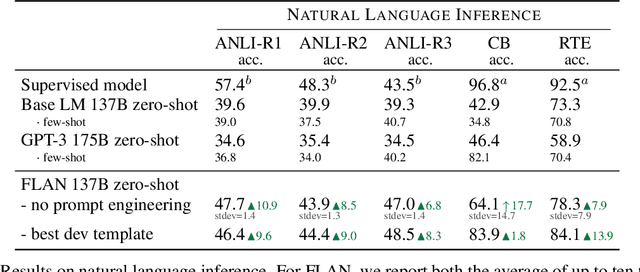
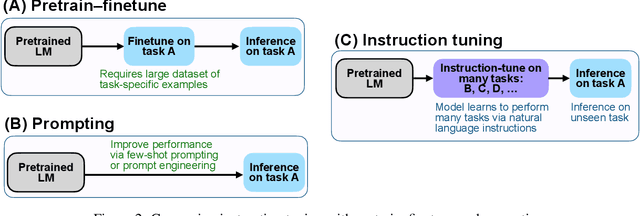
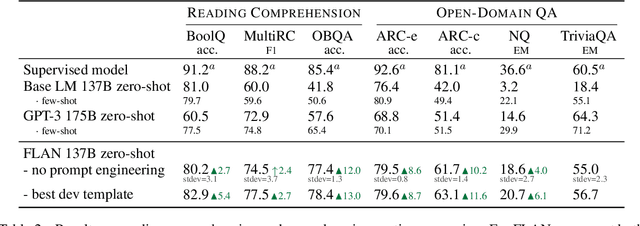
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially boosts zero-shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction-tune it on over 60 NLP tasks verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 19 of 25 tasks that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of tasks and model scale are key components to the success of instruction tuning.
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
Aug 24, 2021
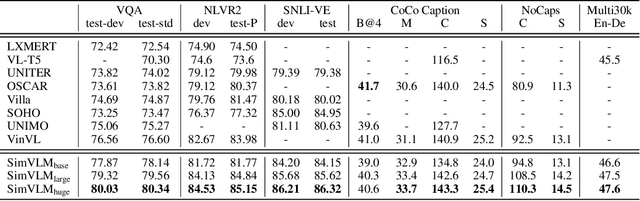
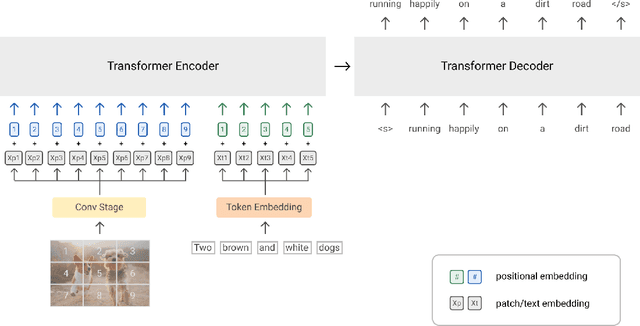
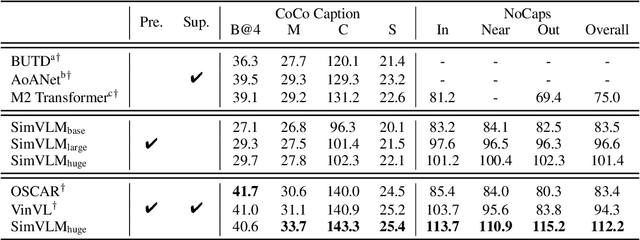
With recent progress in joint modeling of visual and textual representations, Vision-Language Pretraining (VLP) has achieved impressive performance on many multimodal downstream tasks. However, the requirement for expensive annotations including clean image captions and regional labels limits the scalability of existing approaches, and complicates the pretraining procedure with the introduction of multiple dataset-specific objectives. In this work, we relax these constraints and present a minimalist pretraining framework, named Simple Visual Language Model (SimVLM). Unlike prior work, SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective. Without utilizing extra data or task-specific customization, the resulting model significantly outperforms previous pretraining methods and achieves new state-of-the-art results on a wide range of discriminative and generative vision-language benchmarks, including VQA (+3.74% vqa-score), NLVR2 (+1.17% accuracy), SNLI-VE (+1.37% accuracy) and image captioning tasks (+10.1% average CIDEr score). Furthermore, we demonstrate that SimVLM acquires strong generalization and transfer ability, enabling zero-shot behavior including open-ended visual question answering and cross-modality transfer.
Compositional Generalization via Neural-Symbolic Stack Machines
Aug 15, 2020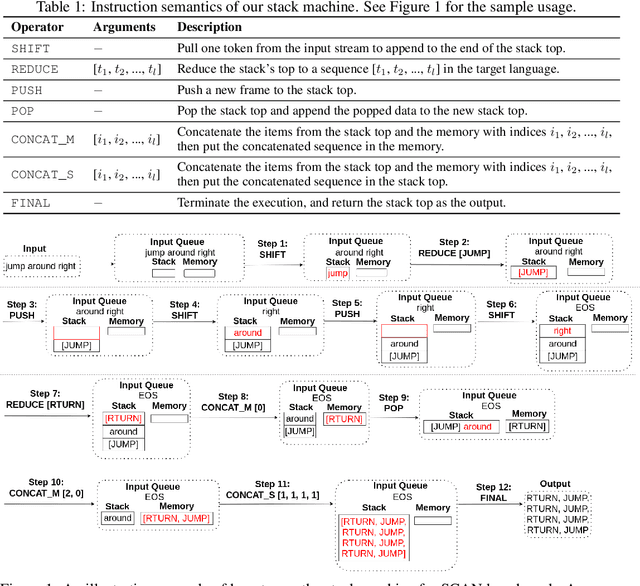
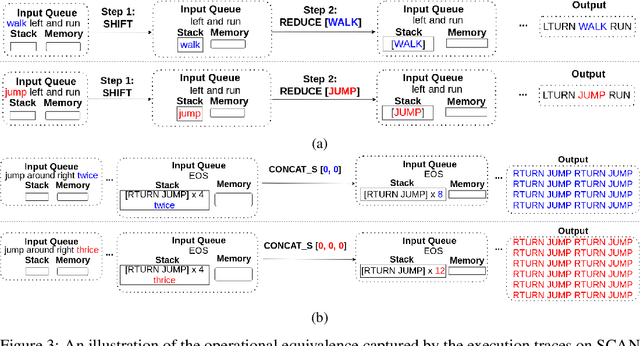
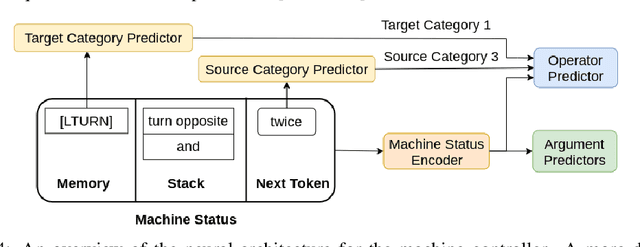

Despite achieving tremendous success, existing deep learning models have exposed limitations in compositional generalization, the capability to learn compositional rules and apply them to unseen cases in a systematic manner. To tackle this issue, we propose the Neural-Symbolic Stack Machine (NeSS). It contains a neural network to generate traces, which are then executed by a symbolic stack machine enhanced with sequence manipulation operations. NeSS combines the expressive power of neural sequence models with the recursion supported by the symbolic stack machine. Without training supervision on execution traces, NeSS achieves 100% generalization performance in three domains: the SCAN benchmark of language-driven navigation tasks, the compositional machine translation benchmark, and context-free grammar parsing tasks.