 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Label Language Learning
Paper and Code
Sep 19, 2021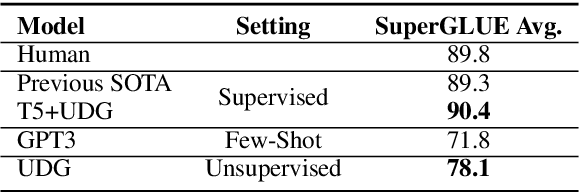
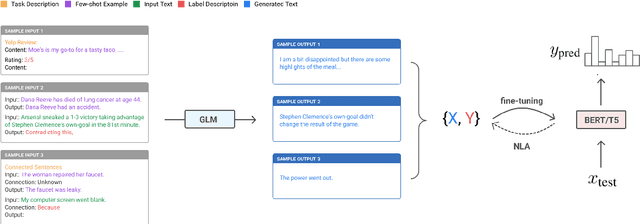
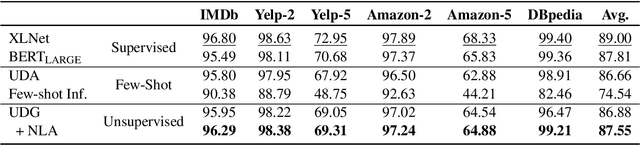
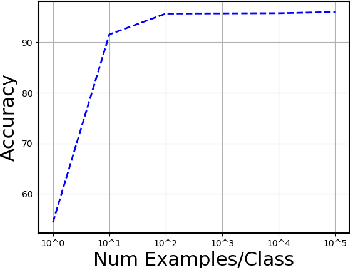
This paper explores zero-label learning in Natural Language Processing (NLP), whereby no human-annotated data is used anywhere during training and models are trained purely on synthetic data. At the core of our framework is a novel approach for better leveraging the powerful pretrained language models. Specifically, inspired by the recent success of few-shot inference on GPT-3, we present a training data creation procedure named Unsupervised Data Generation (UDG), which leverages few-shot prompts to synthesize high-quality training data without real human annotations. Our method enables zero-label learning as we train task-specific models solely on the synthetic data, yet we achieve better or comparable results from strong baseline models trained on human-labeled data. Furthermore, when mixed with labeled data, our approach serves as a highly effective data augmentation procedure, achieving new state-of-the-art results on the SuperGLUE benchmark.