 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization in Spider-Style Strategy Discovery and Schedule Construction
Mar 19, 2024To achieve the best performance, automatic theorem provers often rely on schedules of diverse proving strategies to be tried out (either sequentially or in parallel) on a given problem. In this paper, we report on a large-scale experiment with discovering strategies for the Vampire prover, targeting the FOF fragment of the TPTP library and constructing a schedule for it, based on the ideas of Andrei Voronkov's system Spider. We examine the process from various angles, discuss the difficulty (or ease) of obtaining a strong Vampire schedule for the CASC competition, and establish how well a schedule can be expected to generalize to unseen problems and what factors influence this property.
MizAR 60 for Mizar 50
Mar 12, 2023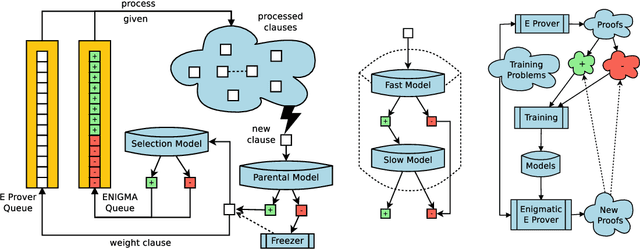



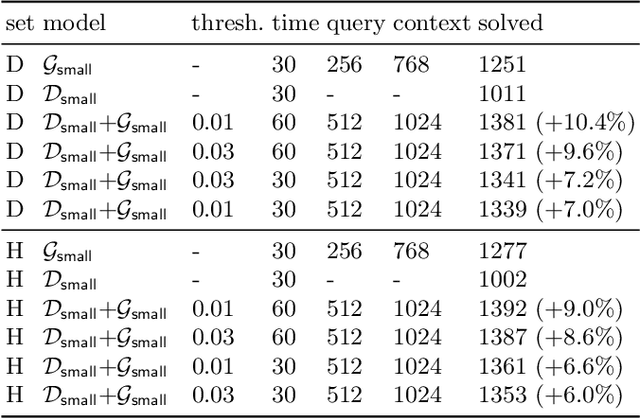
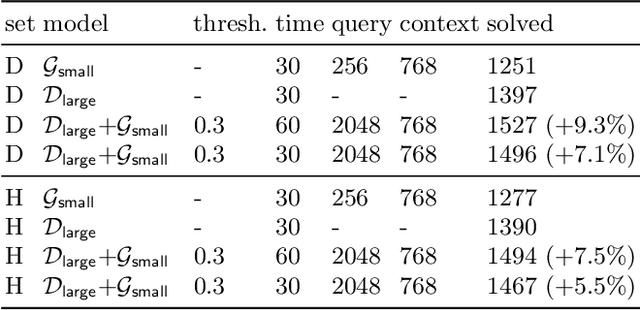
As a present to Mizar on its 50th anniversary, we develop an AI/TP system that automatically proves about 60\% of the Mizar theorems in the hammer setting. We also automatically prove 75\% of the Mizar theorems when the automated provers are helped by using only the premises used in the human-written Mizar proofs. We describe the methods and large-scale experiments leading to these results. This includes in particular the E and Vampire provers, their ENIGMA and Deepire learning modifications, a number of learning-based premise selection methods, and the incremental loop that interleaves growing a corpus of millions of ATP proofs with training increasingly strong AI/TP systems on them. We also present a selection of Mizar problems that were proved automatically.
Learning Theorem Proving Components
Jul 21, 2021

Saturation-style automated theorem provers (ATPs) based on the given clause procedure are today the strongest general reasoners for classical first-order logic. The clause selection heuristics in such systems are, however, often evaluating clauses in isolation, ignoring other clauses. This has changed recently by equipping the E/ENIGMA system with a graph neural network (GNN) that chooses the next given clause based on its evaluation in the context of previously selected clauses. In this work, we describe several algorithms and experiments with ENIGMA, advancing the idea of contextual evaluation based on learning important components of the graph of clauses.
Fast and Slow Enigmas and Parental Guidance
Jul 14, 2021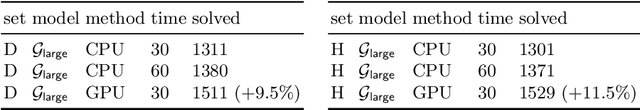
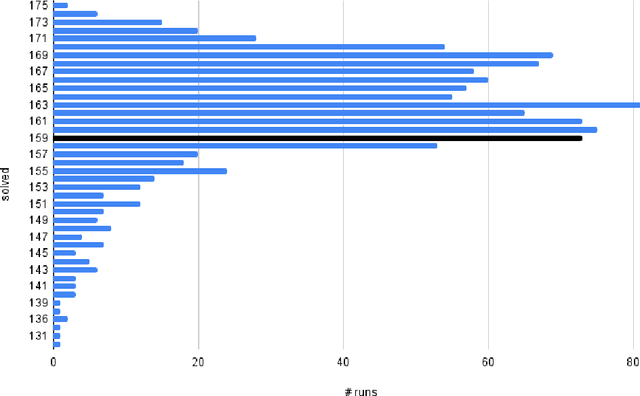
We describe several additions to the ENIGMA system that guides clause selection in the E automated theorem prover. First, we significantly speed up its neural guidance by adding server-based GPU evaluation. The second addition is motivated by fast weight-based rejection filters that are currently used in systems like E and Prover9. Such systems can be made more intelligent by instead training fast versions of ENIGMA that implement more intelligent pre-filtering. This results in combinations of trainable fast and slow thinking that improves over both the fast-only and slow-only methods. The third addition is based on "judging the children by their parents", i.e., possibly rejecting an inference before it produces a clause. This is motivated by standard evolutionary mechanisms, where there is always a cost to producing all possible offsprings in the current population. This saves time by not evaluating all clauses by more expensive methods and provides a complementary view of the generated clauses. The methods are evaluated on a large benchmark coming from the Mizar Mathematical Library, showing good improvements over the state of the art.
ENIGMA Anonymous: Symbol-Independent Inference Guiding Machine (system description)
Feb 13, 2020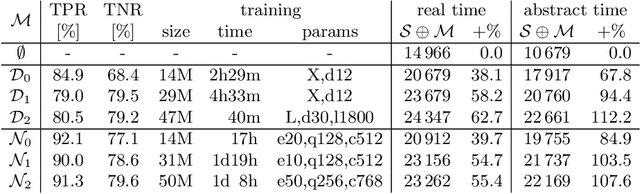
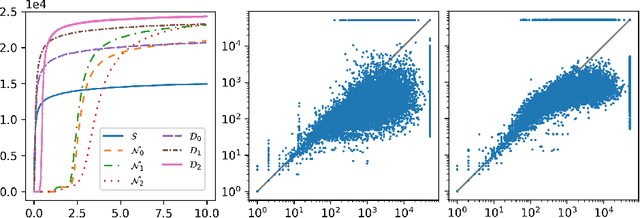
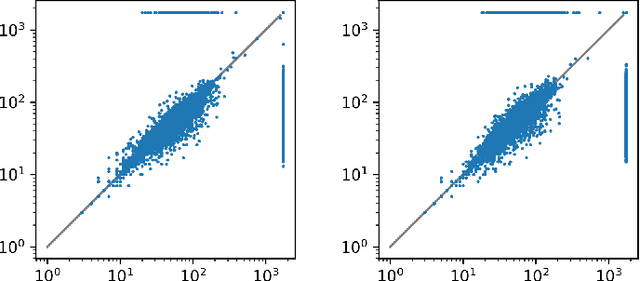
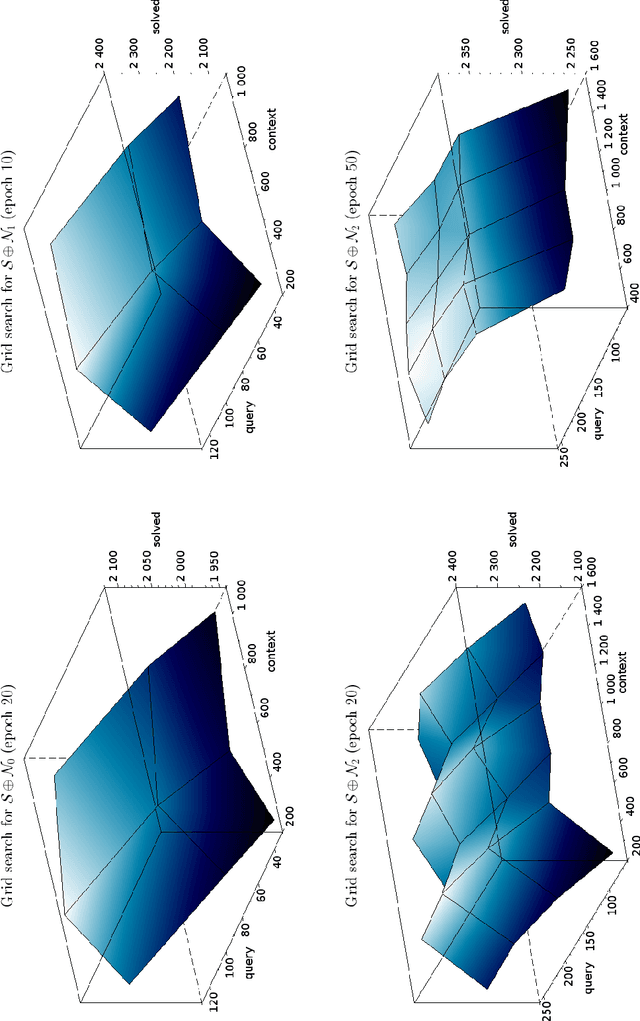
We describe an implementation of gradient boosting and neural guidance of saturation-style automated theorem provers that does not depend on consistent symbol names across problems. For the gradient-boosting guidance, we manually create abstracted features by considering arity-based encodings of formulas. For the neural guidance, we use symbol-independent graph neural networks and their embedding of the terms and clauses. The two methods are efficiently implemented in the E prover and its ENIGMA learning-guided framework and evaluated on the MPTP large-theory benchmark. Both methods are shown to achieve comparable real-time performance to state-of-the-art symbol-based methods.
ENIGMA-NG: Efficient Neural and Gradient-Boosted Inference Guidance for E
Mar 07, 2019
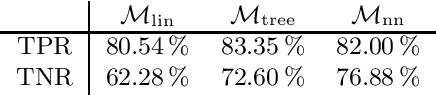
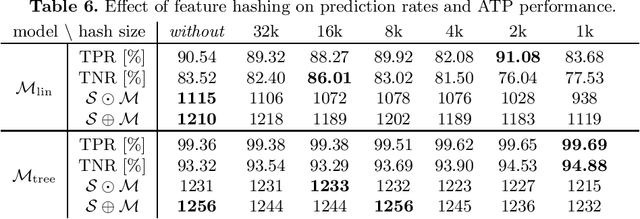
We describe an efficient implementation of clause guidance in saturation-based automated theorem provers extending the ENIGMA approach. Unlike in the first ENIGMA implementation where fast linear classifier is trained and used together with manually engineered features, we have started to experiment with more sophisticated state-of-the-art machine learning methods such as gradient boosted trees and recursive neural networks. In particular the latter approach poses challenges in terms of efficiency of clause evaluation, however, we show that deep integration of the neural evaluation with the ATP data-structures can largely amortize this cost and lead to competitive real-time results. Both methods are evaluated on a large dataset of theorem proving problems and compared with the previous approaches. The resulting methods improve on the manually designed clause guidance, providing the first practically convincing application of gradient-boosted and neural clause guidance in saturation-style automated theorem provers.