 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti hash embeddings in spaCy
Dec 19, 2022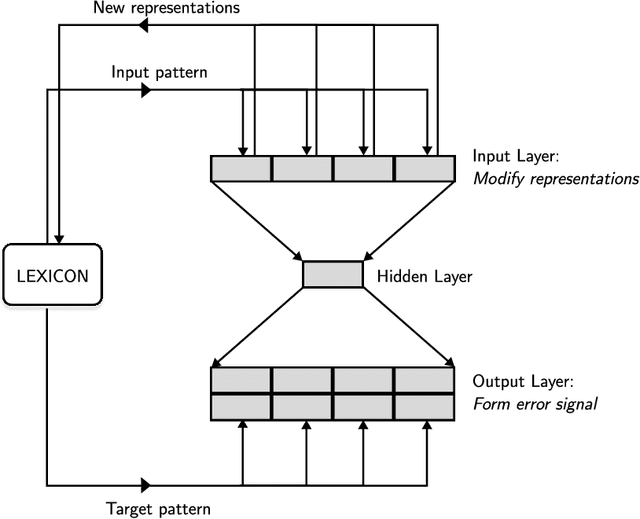


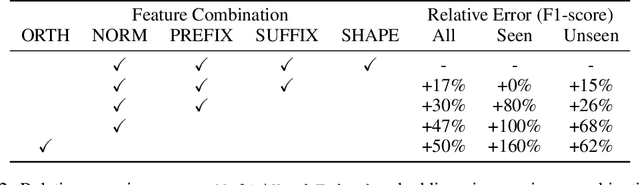
The distributed representation of symbols is one of the key technologies in machine learning systems today, playing a pivotal role in modern natural language processing. Traditional word embeddings associate a separate vector with each word. While this approach is simple and leads to good performance, it requires a lot of memory for representing a large vocabulary. To reduce the memory footprint, the default embedding layer in spaCy is a hash embeddings layer. It is a stochastic approximation of traditional embeddings that provides unique vectors for a large number of words without explicitly storing a separate vector for each of them. To be able to compute meaningful representations for both known and unknown words, hash embeddings represent each word as a summary of the normalized word form, subword information and word shape. Together, these features produce a multi-embedding of a word. In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy's embedders, but we also uncover a few surprising results.
Cyberbullying Classifiers are Sensitive to Model-Agnostic Perturbations
Jan 17, 2022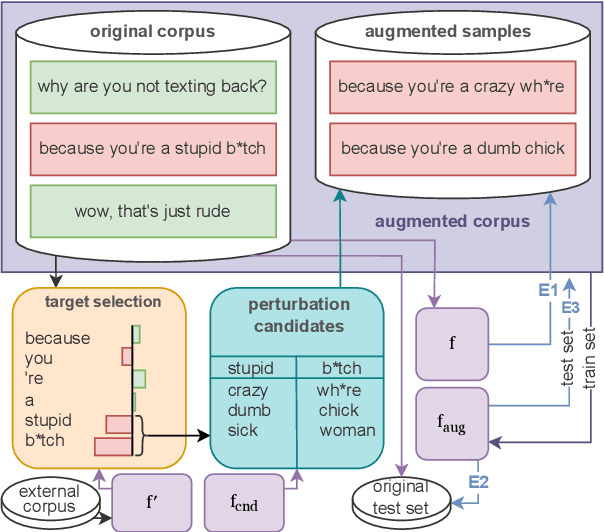
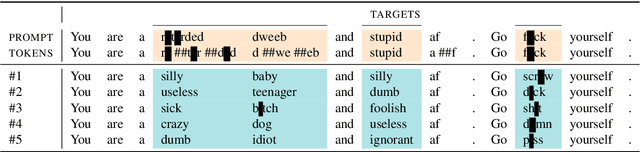
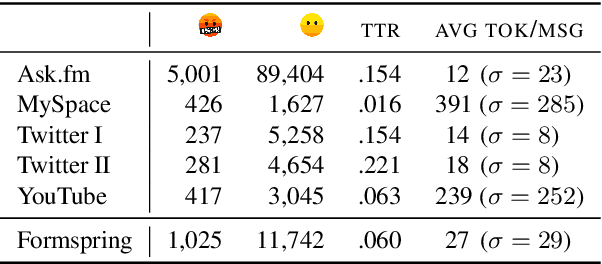
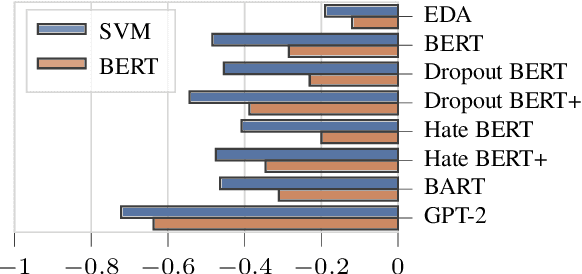
A limited amount of studies investigates the role of model-agnostic adversarial behavior in toxic content classification. As toxicity classifiers predominantly rely on lexical cues, (deliberately) creative and evolving language-use can be detrimental to the utility of current corpora and state-of-the-art models when they are deployed for content moderation. The less training data is available, the more vulnerable models might become. This study is, to our knowledge, the first to investigate the effect of adversarial behavior and augmentation for cyberbullying detection. We demonstrate that model-agnostic lexical substitutions significantly hurt classifier performance. Moreover, when these perturbed samples are used for augmentation, we show models become robust against word-level perturbations at a slight trade-off in overall task performance. Augmentations proposed in prior work on toxicity prove to be less effective. Our results underline the need for such evaluations in online harm areas with small corpora. The perturbed data, models, and code are available for reproduction at https://github.com/cmry/augtox
Turing: an Accurate and Interpretable Multi-Hypothesis Cross-Domain Natural Language Database Interface
Jun 08, 2021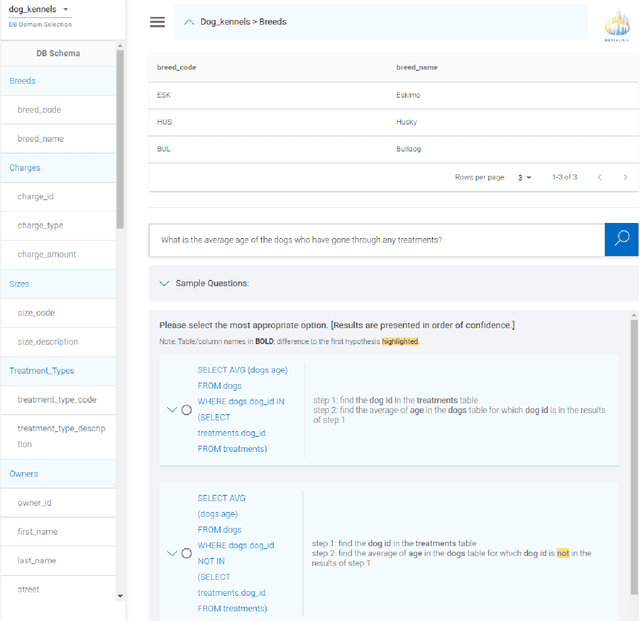



A natural language database interface (NLDB) can democratize data-driven insights for non-technical users. However, existing Text-to-SQL semantic parsers cannot achieve high enough accuracy in the cross-database setting to allow good usability in practice. This work presents Turing, a NLDB system toward bridging this gap. The cross-domain semantic parser of Turing with our novel value prediction method achieves $75.1\%$ execution accuracy, and $78.3\%$ top-5 beam execution accuracy on the Spider validation set. To benefit from the higher beam accuracy, we design an interactive system where the SQL hypotheses in the beam are explained step-by-step in natural language, with their differences highlighted. The user can then compare and judge the hypotheses to select which one reflects their intention if any. The English explanations of SQL queries in Turing are produced by our high-precision natural language generation system based on synchronous grammars.
Subword Pooling Makes a Difference
Feb 22, 2021
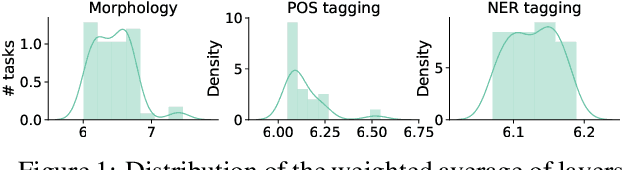
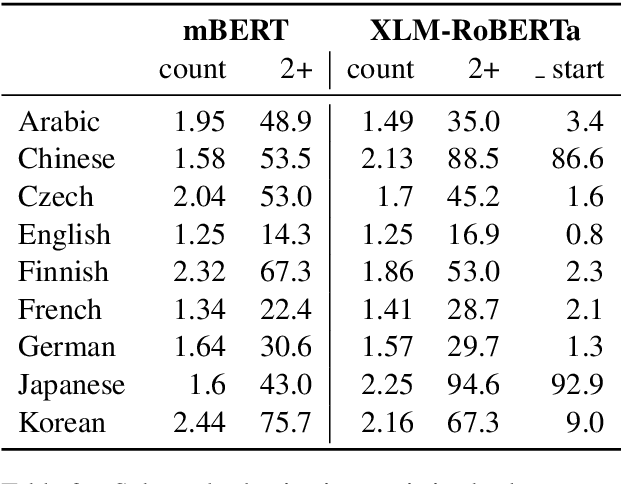

Contextual word-representations became a standard in modern natural language processing systems. These models use subword tokenization to handle large vocabularies and unknown words. Word-level usage of such systems requires a way of pooling multiple subwords that correspond to a single word. In this paper we investigate how the choice of subword pooling affects the downstream performance on three tasks: morphological probing, POS tagging and NER, in 9 typologically diverse languages. We compare these in two massively multilingual models, mBERT and XLM-RoBERTa. For morphological tasks, the widely used `choose the first subword' is the worst strategy and the best results are obtained by using attention over the subwords. For POS tagging both of these strategies perform poorly and the best choice is to use a small LSTM over the subwords. The same strategy works best for NER and we show that mBERT is better than XLM-RoBERTa in all 9 languages. We publicly release all code, data and the full result tables at \url{https://github.com/juditacs/subword-choice}.
Adversarial Stylometry in the Wild: Transferable Lexical Substitution Attacks on Author Profiling
Jan 27, 2021


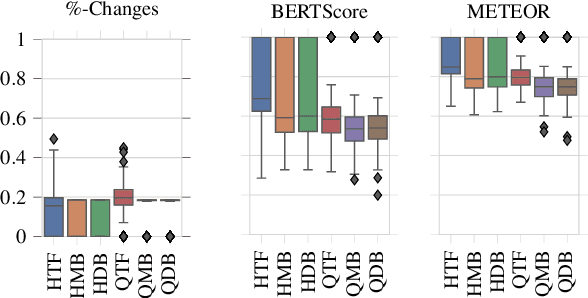
Written language contains stylistic cues that can be exploited to automatically infer a variety of potentially sensitive author information. Adversarial stylometry intends to attack such models by rewriting an author's text. Our research proposes several components to facilitate deployment of these adversarial attacks in the wild, where neither data nor target models are accessible. We introduce a transformer-based extension of a lexical replacement attack, and show it achieves high transferability when trained on a weakly labeled corpus -- decreasing target model performance below chance. While not completely inconspicuous, our more successful attacks also prove notably less detectable by humans. Our framework therefore provides a promising direction for future privacy-preserving adversarial attacks.
Bootstrapping Disjoint Datasets for Multilingual Multimodal Representation Learning
Nov 09, 2019



Recent work has highlighted the advantage of jointly learning grounded sentence representations from multiple languages. However, the data used in these studies has been limited to an aligned scenario: the same images annotated with sentences in multiple languages. We focus on the more realistic disjoint scenario in which there is no overlap between the images in multilingual image--caption datasets. We confirm that training with aligned data results in better grounded sentence representations than training with disjoint data, as measured by image--sentence retrieval performance. In order to close this gap in performance, we propose a pseudopairing method to generate synthetically aligned English--German--image triplets from the disjoint sets. The method works by first training a model on the disjoint data, and then creating new triples across datasets using sentence similarity under the learned model. Experiments show that pseudopairs improve image--sentence retrieval performance compared to disjoint training, despite requiring no external data or models. However, we do find that using an external machine translation model to generate the synthetic data sets results in better performance.
Improving Lemmatization of Non-Standard Languages with Joint Learning
Mar 16, 2019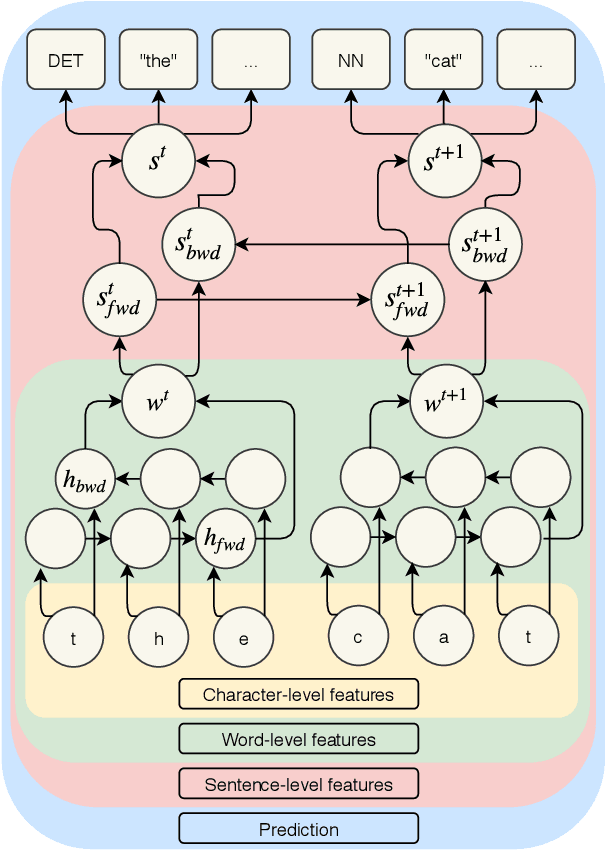
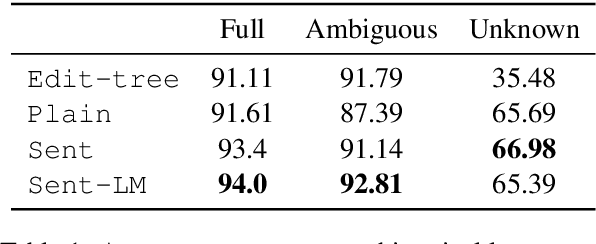
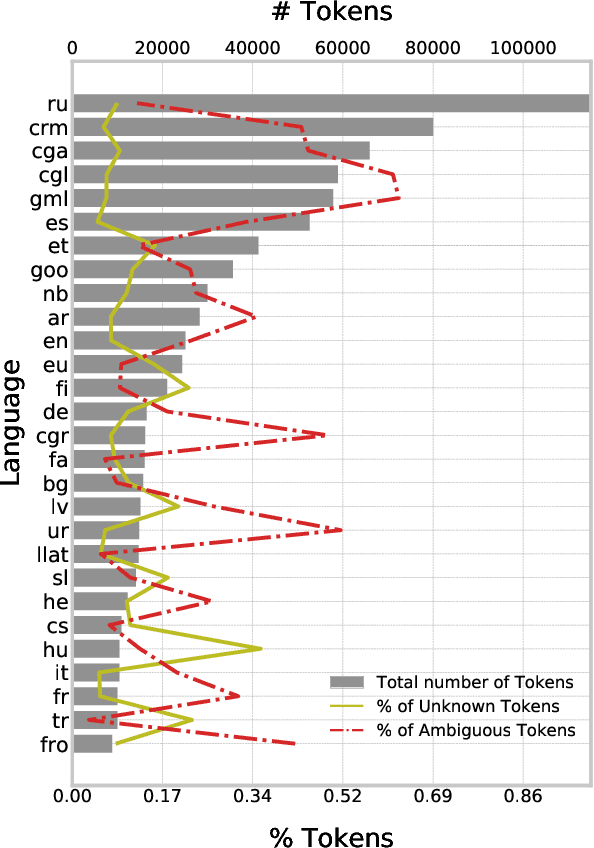

Lemmatization of standard languages is concerned with (i) abstracting over morphological differences and (ii) resolving token-lemma ambiguities of inflected words in order to map them to a dictionary headword. In the present paper we aim to improve lemmatization performance on a set of non-standard historical languages in which the difficulty is increased by an additional aspect (iii): spelling variation due to lacking orthographic standards. We approach lemmatization as a string-transduction task with an encoder-decoder architecture which we enrich with sentence context information using a hierarchical sentence encoder. We show significant improvements over the state-of-the-art when training the sentence encoder jointly for lemmatization and language modeling. Crucially, our architecture does not require POS or morphological annotations, which are not always available for historical corpora. Additionally, we also test the proposed model on a set of typologically diverse standard languages showing results on par or better than a model without enhanced sentence representations and previous state-of-the-art systems. Finally, to encourage future work on processing of non-standard varieties, we release the dataset of non-standard languages underlying the present study, based on openly accessible sources.
On the difficulty of a distributional semantics of spoken language
Oct 26, 2018

In the domain of unsupervised learning most work on speech has focused on discovering low-level constructs such as phoneme inventories or word-like units. In contrast, for written language, where there is a large body of work on unsupervised induction of semantic representations of words, whole sentences and longer texts. In this study we examine the challenges of adapting these approaches from written to spoken language. We conjecture that unsupervised learning of the semantics of spoken language becomes feasible if we abstract from the surface variability. We simulate this setting with a dataset of utterances spoken by a realistic but uniform synthetic voice. We evaluate two simple unsupervised models which, to varying degrees of success, learn semantic representations of speech fragments. Finally we present inconclusive results on human speech, and discuss the challenges inherent in learning distributional semantic representations on unrestricted natural spoken language.
Lessons learned in multilingual grounded language learning
Sep 20, 2018
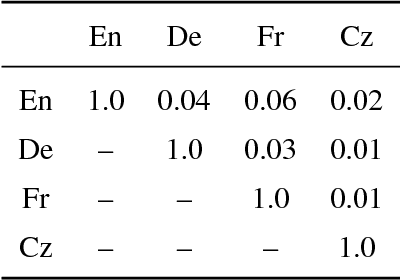


Recent work has shown how to learn better visual-semantic embeddings by leveraging image descriptions in more than one language. Here, we investigate in detail which conditions affect the performance of this type of grounded language learning model. We show that multilingual training improves over bilingual training, and that low-resource languages benefit from training with higher-resource languages. We demonstrate that a multilingual model can be trained equally well on either translations or comparable sentence pairs, and that annotating the same set of images in multiple language enables further improvements via an additional caption-caption ranking objective.
Revisiting the Hierarchical Multiscale LSTM
Jul 10, 2018


Hierarchical Multiscale LSTM (Chung et al., 2016a) is a state-of-the-art language model that learns interpretable structure from character-level input. Such models can provide fertile ground for (cognitive) computational linguistics studies. However, the high complexity of the architecture, training procedure and implementations might hinder its applicability. We provide a detailed reproduction and ablation study of the architecture, shedding light on some of the potential caveats of re-purposing complex deep-learning architectures. We further show that simplifying certain aspects of the architecture can in fact improve its performance. We also investigate the linguistic units (segments) learned by various levels of the model, and argue that their quality does not correlate with the overall performance of the model on language modeling.