 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti hash embeddings in spaCy
Dec 19, 2022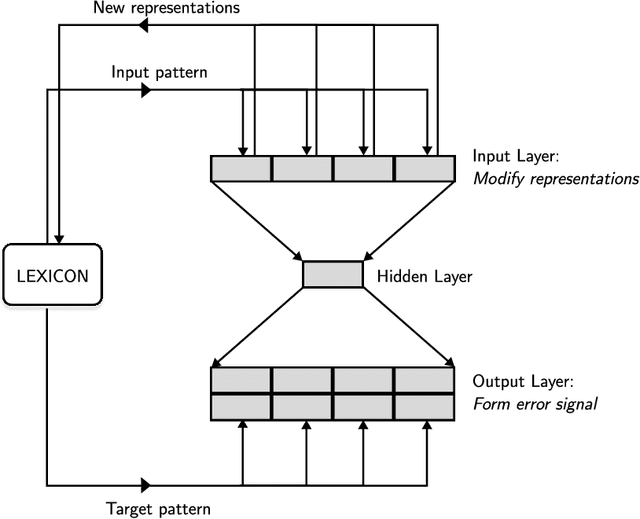


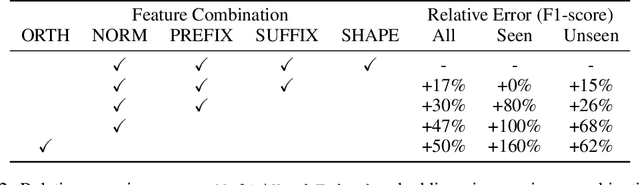
The distributed representation of symbols is one of the key technologies in machine learning systems today, playing a pivotal role in modern natural language processing. Traditional word embeddings associate a separate vector with each word. While this approach is simple and leads to good performance, it requires a lot of memory for representing a large vocabulary. To reduce the memory footprint, the default embedding layer in spaCy is a hash embeddings layer. It is a stochastic approximation of traditional embeddings that provides unique vectors for a large number of words without explicitly storing a separate vector for each of them. To be able to compute meaningful representations for both known and unknown words, hash embeddings represent each word as a summary of the normalized word form, subword information and word shape. Together, these features produce a multi-embedding of a word. In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Second, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages. The experiments validate most key design choices behind spaCy's embedders, but we also uncover a few surprising results.