 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Vision Transformer from scratch in less than 24 hours with 1 GPU
Nov 09, 2022
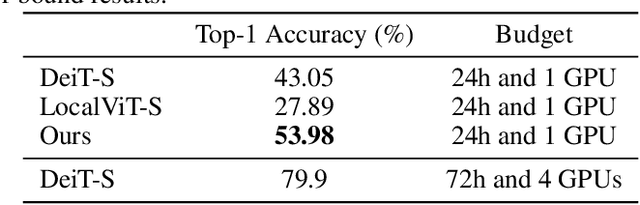
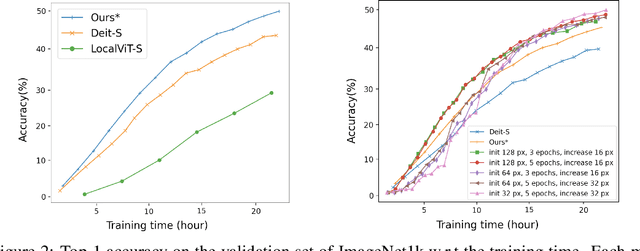
Transformers have become central to recent advances in computer vision. However, training a vision Transformer (ViT) model from scratch can be resource intensive and time consuming. In this paper, we aim to explore approaches to reduce the training costs of ViT models. We introduce some algorithmic improvements to enable training a ViT model from scratch with limited hardware (1 GPU) and time (24 hours) resources. First, we propose an efficient approach to add locality to the ViT architecture. Second, we develop a new image size curriculum learning strategy, which allows to reduce the number of patches extracted from each image at the beginning of the training. Finally, we propose a new variant of the popular ImageNet1k benchmark by adding hardware and time constraints. We evaluate our contributions on this benchmark, and show they can significantly improve performances given the proposed training budget. We will share the code in https://github.com/BorealisAI/efficient-vit-training.
Turing: an Accurate and Interpretable Multi-Hypothesis Cross-Domain Natural Language Database Interface
Jun 08, 2021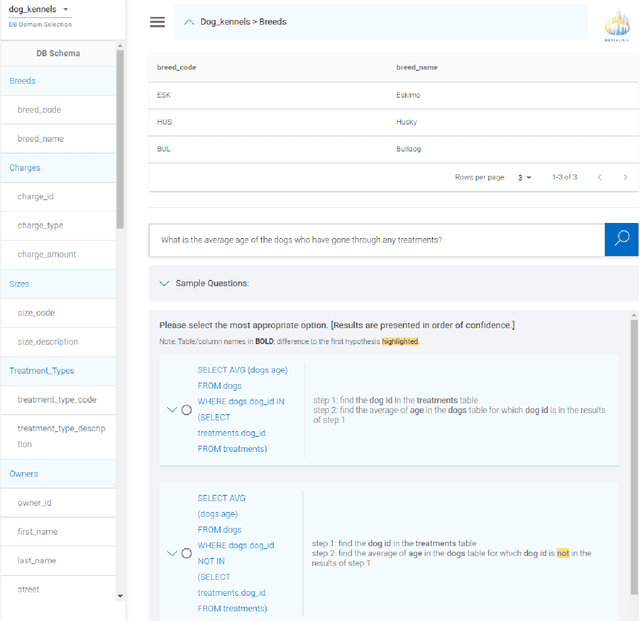



A natural language database interface (NLDB) can democratize data-driven insights for non-technical users. However, existing Text-to-SQL semantic parsers cannot achieve high enough accuracy in the cross-database setting to allow good usability in practice. This work presents Turing, a NLDB system toward bridging this gap. The cross-domain semantic parser of Turing with our novel value prediction method achieves $75.1\%$ execution accuracy, and $78.3\%$ top-5 beam execution accuracy on the Spider validation set. To benefit from the higher beam accuracy, we design an interactive system where the SQL hypotheses in the beam are explained step-by-step in natural language, with their differences highlighted. The user can then compare and judge the hypotheses to select which one reflects their intention if any. The English explanations of SQL queries in Turing are produced by our high-precision natural language generation system based on synchronous grammars.
Optimizing Deeper Transformers on Small Datasets: An Application on Text-to-SQL Semantic Parsing
Dec 30, 2020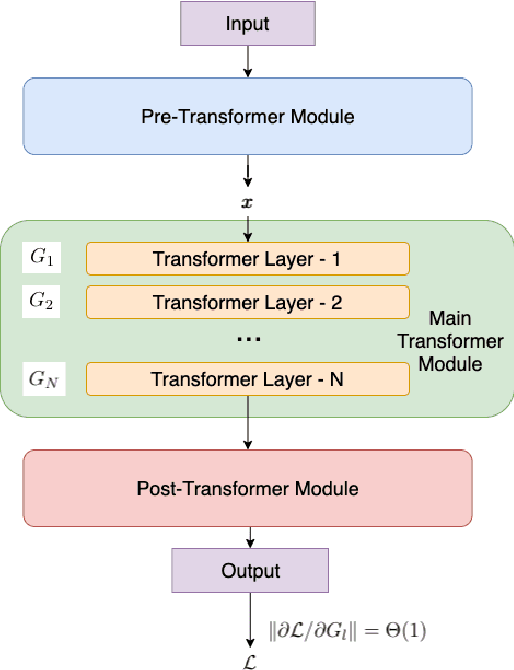
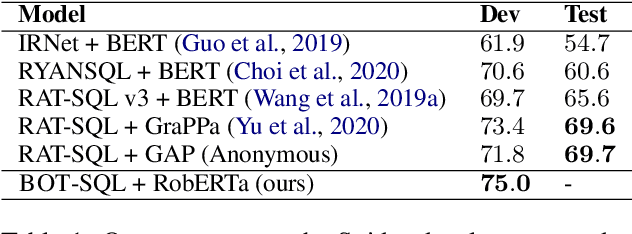
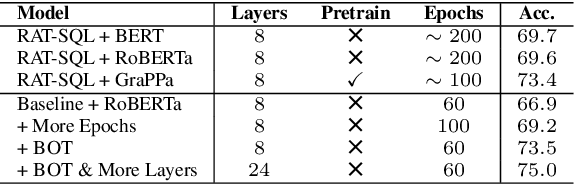
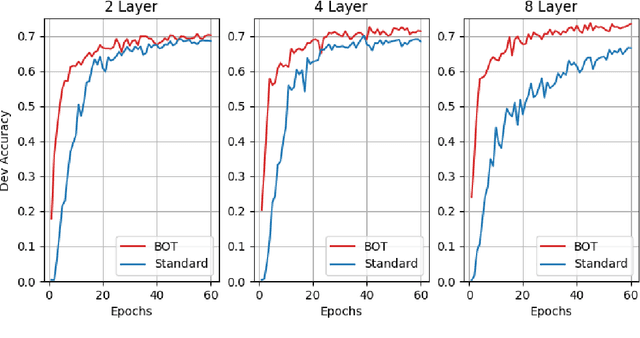
Due to the common belief that training deep transformers from scratch requires large datasets, people usually only use shallow and simple additional layers on top of pre-trained models during fine-tuning on small datasets. We provide evidence that this does not always need to be the case: with proper initialization and training techniques, the benefits of very deep transformers are shown to carry over to hard structural prediction tasks, even using small datasets. In particular, we successfully train 48 layers of transformers for a semantic parsing task. These comprise 24 fine-tuned transformer layers from pre-trained RoBERTa and 24 relation-aware transformer layers trained from scratch. With fewer training steps and no task-specific pre-training, we obtain the state of the art performance on the challenging cross-domain Text-to-SQL semantic parsing benchmark Spider. We achieve this by deriving a novel Data dependent Transformer Fixed-update initialization scheme (DT-Fixup), inspired by the prior T-Fixup work. Further error analysis demonstrates that increasing the depth of the transformer model can help improve generalization on the cases requiring reasoning and structural understanding.