 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuring: an Accurate and Interpretable Multi-Hypothesis Cross-Domain Natural Language Database Interface
Jun 08, 2021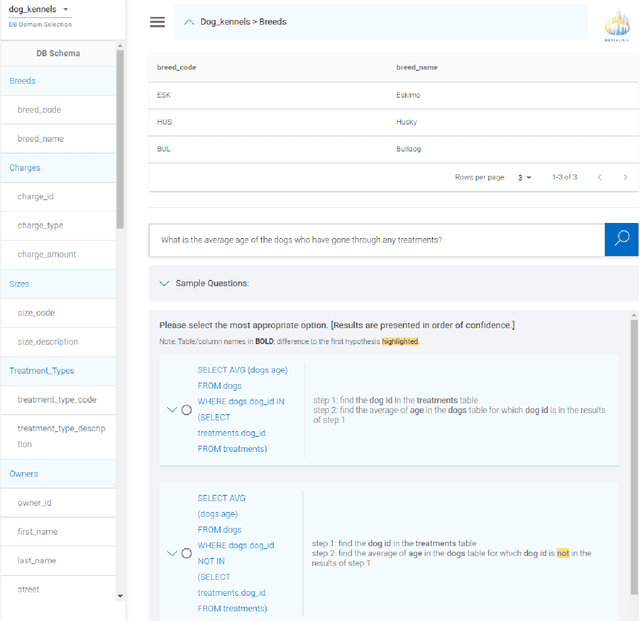



A natural language database interface (NLDB) can democratize data-driven insights for non-technical users. However, existing Text-to-SQL semantic parsers cannot achieve high enough accuracy in the cross-database setting to allow good usability in practice. This work presents Turing, a NLDB system toward bridging this gap. The cross-domain semantic parser of Turing with our novel value prediction method achieves $75.1\%$ execution accuracy, and $78.3\%$ top-5 beam execution accuracy on the Spider validation set. To benefit from the higher beam accuracy, we design an interactive system where the SQL hypotheses in the beam are explained step-by-step in natural language, with their differences highlighted. The user can then compare and judge the hypotheses to select which one reflects their intention if any. The English explanations of SQL queries in Turing are produced by our high-precision natural language generation system based on synchronous grammars.
Two Birds, One Stone: A Simple, Unified Model for Text Generation from Structured and Unstructured Data
Sep 23, 2019


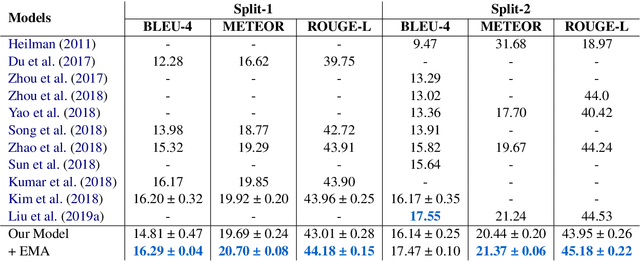
A number of researchers have recently questioned the necessity of increasingly complex neural network (NN) architectures. In particular, several recent papers have shown that simpler, properly tuned models are at least competitive across several NLP tasks. In this work, we show that this is also the case for text generation from structured and unstructured data. We consider neural table-to-text generation and neural question generation (NQG) tasks for text generation from structured and unstructured data, respectively. Table-to-text generation aims to generate a description based on a given table, and NQG is the task of generating a question from a given passage where the generated question can be answered by a certain sub-span of the passage using NN models. Experimental results demonstrate that a basic attention-based seq2seq model trained with the exponential moving average technique achieves the state of the art in both tasks.