 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP-IRL: Fokker-Planck-based Inverse Reinforcement Learning -- A Physics-Constrained Approach to Markov Decision Processes
Jun 17, 2023



Inverse Reinforcement Learning (IRL) is a compelling technique for revealing the rationale underlying the behavior of autonomous agents. IRL seeks to estimate the unknown reward function of a Markov decision process (MDP) from observed agent trajectories. However, IRL needs a transition function, and most algorithms assume it is known or can be estimated in advance from data. It therefore becomes even more challenging when such transition dynamics is not known a-priori, since it enters the estimation of the policy in addition to determining the system's evolution. When the dynamics of these agents in the state-action space is described by stochastic differential equations (SDE) in It^{o} calculus, these transitions can be inferred from the mean-field theory described by the Fokker-Planck (FP) equation. We conjecture there exists an isomorphism between the time-discrete FP and MDP that extends beyond the minimization of free energy (in FP) and maximization of the reward (in MDP). We identify specific manifestations of this isomorphism and use them to create a novel physics-aware IRL algorithm, FP-IRL, which can simultaneously infer the transition and reward functions using only observed trajectories. We employ variational system identification to infer the potential function in FP, which consequently allows the evaluation of reward, transition, and policy by leveraging the conjecture. We demonstrate the effectiveness of FP-IRL by applying it to a synthetic benchmark and a biological problem of cancer cell dynamics, where the transition function is inaccessible.
Optimizing Deeper Transformers on Small Datasets: An Application on Text-to-SQL Semantic Parsing
Dec 30, 2020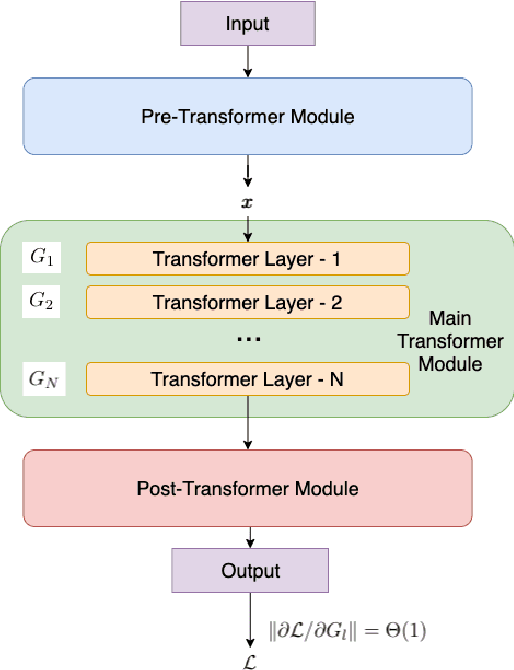
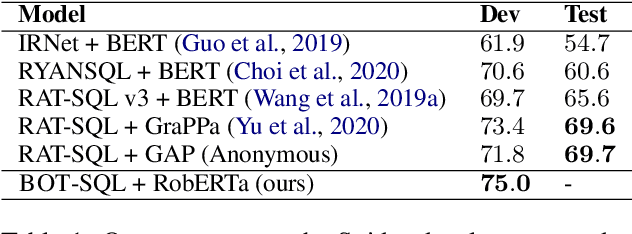
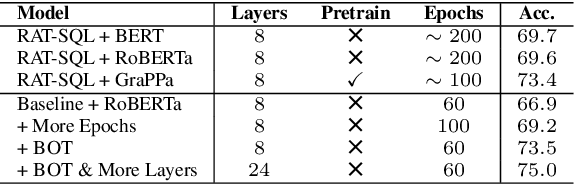
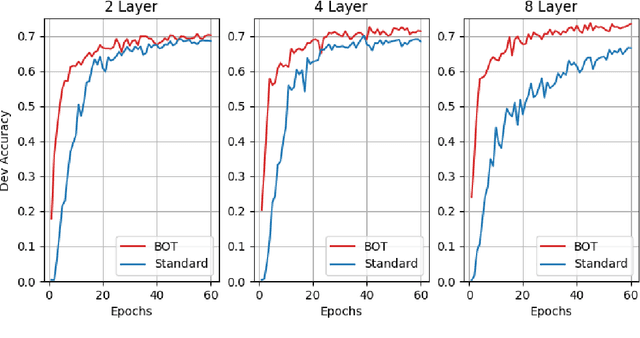
Due to the common belief that training deep transformers from scratch requires large datasets, people usually only use shallow and simple additional layers on top of pre-trained models during fine-tuning on small datasets. We provide evidence that this does not always need to be the case: with proper initialization and training techniques, the benefits of very deep transformers are shown to carry over to hard structural prediction tasks, even using small datasets. In particular, we successfully train 48 layers of transformers for a semantic parsing task. These comprise 24 fine-tuned transformer layers from pre-trained RoBERTa and 24 relation-aware transformer layers trained from scratch. With fewer training steps and no task-specific pre-training, we obtain the state of the art performance on the challenging cross-domain Text-to-SQL semantic parsing benchmark Spider. We achieve this by deriving a novel Data dependent Transformer Fixed-update initialization scheme (DT-Fixup), inspired by the prior T-Fixup work. Further error analysis demonstrates that increasing the depth of the transformer model can help improve generalization on the cases requiring reasoning and structural understanding.