 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative Language Identification with Big Bird Embeddings
Sep 13, 2023

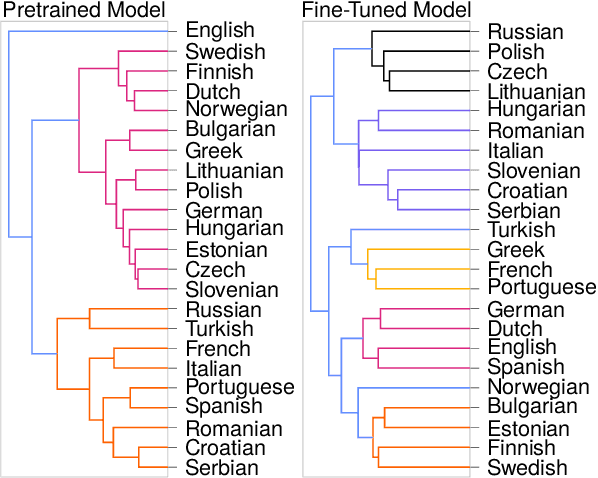

Native Language Identification (NLI) intends to classify an author's native language based on their writing in another language. Historically, the task has heavily relied on time-consuming linguistic feature engineering, and transformer-based NLI models have thus far failed to offer effective, practical alternatives. The current work investigates if input size is a limiting factor, and shows that classifiers trained using Big Bird embeddings outperform linguistic feature engineering models by a large margin on the Reddit-L2 dataset. Additionally, we provide further insight into input length dependencies, show consistent out-of-sample performance, and qualitatively analyze the embedding space. Given the effectiveness and computational efficiency of this method, we believe it offers a promising avenue for future NLI work.
Tailoring Domain Adaptation for Machine Translation Quality Estimation
Apr 18, 2023While quality estimation (QE) can play an important role in the translation process, its effectiveness relies on the availability and quality of training data. For QE in particular, high-quality labeled data is often lacking due to the high-cost and effort associated with labeling such data. Aside from the data scarcity challenge, QE models should also be generalizable, i.e., they should be able to handle data from different domains, both generic and specific. To alleviate these two main issues -- data scarcity and domain mismatch -- this paper combines domain adaptation and data augmentation within a robust QE system. Our method is to first train a generic QE model and then fine-tune it on a specific domain while retaining generic knowledge. Our results show a significant improvement for all the language pairs investigated, better cross-lingual inference, and a superior performance in zero-shot learning scenarios as compared to state-of-the-art baselines.
User-Centered Security in Natural Language Processing
Jan 10, 2023
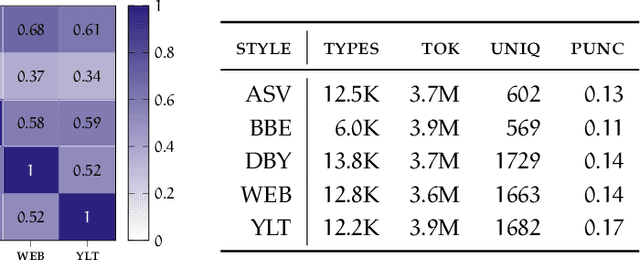


This dissertation proposes a framework of user-centered security in Natural Language Processing (NLP), and demonstrates how it can improve the accessibility of related research. Accordingly, it focuses on two security domains within NLP with great public interest. First, that of author profiling, which can be employed to compromise online privacy through invasive inferences. Without access and detailed insight into these models' predictions, there is no reasonable heuristic by which Internet users might defend themselves from such inferences. Secondly, that of cyberbullying detection, which by default presupposes a centralized implementation; i.e., content moderation across social platforms. As access to appropriate data is restricted, and the nature of the task rapidly evolves (both through lexical variation, and cultural shifts), the effectiveness of its classifiers is greatly diminished and thereby often misrepresented. Under the proposed framework, we predominantly investigate the use of adversarial attacks on language; i.e., changing a given input (generating adversarial samples) such that a given model does not function as intended. These attacks form a common thread between our user-centered security problems; they are highly relevant for privacy-preserving obfuscation methods against author profiling, and adversarial samples might also prove useful to assess the influence of lexical variation and augmentation on cyberbullying detection.
Neural Data-to-Text Generation Based on Small Datasets: Comparing the Added Value of Two Semi-Supervised Learning Approaches on Top of a Large Language Model
Jul 14, 2022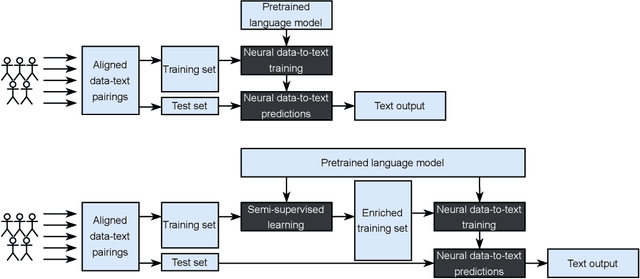
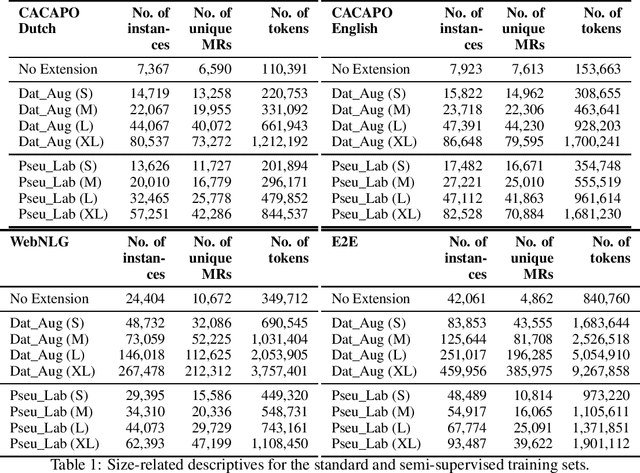
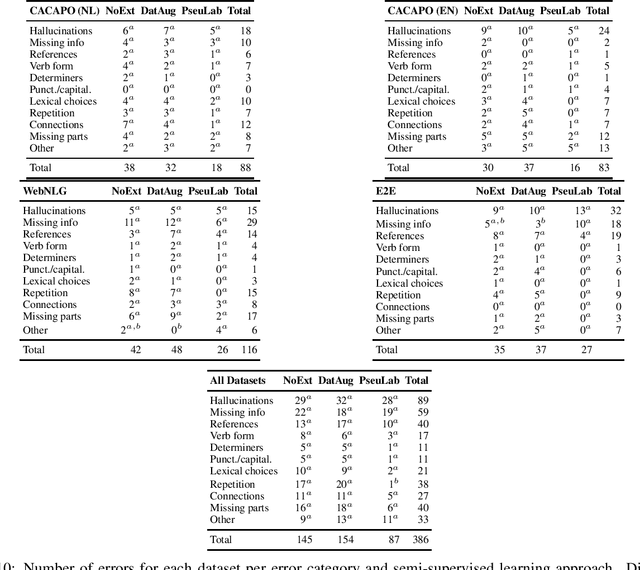
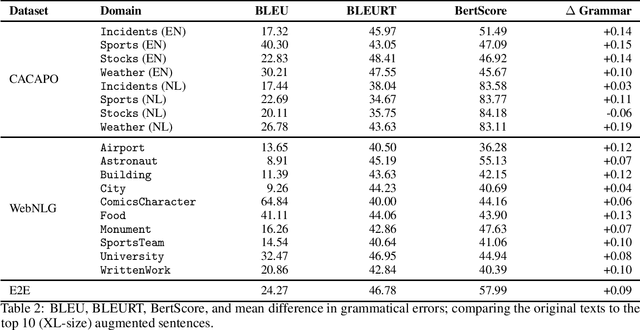
This study discusses the effect of semi-supervised learning in combination with pretrained language models for data-to-text generation. It is not known whether semi-supervised learning is still helpful when a large-scale language model is also supplemented. This study aims to answer this question by comparing a data-to-text system only supplemented with a language model, to two data-to-text systems that are additionally enriched by a data augmentation or a pseudo-labeling semi-supervised learning approach. Results show that semi-supervised learning results in higher scores on diversity metrics. In terms of output quality, extending the training set of a data-to-text system with a language model using the pseudo-labeling approach did increase text quality scores, but the data augmentation approach yielded similar scores to the system without training set extension. These results indicate that semi-supervised learning approaches can bolster output quality and diversity, even when a language model is also present.
Cyberbullying Classifiers are Sensitive to Model-Agnostic Perturbations
Jan 17, 2022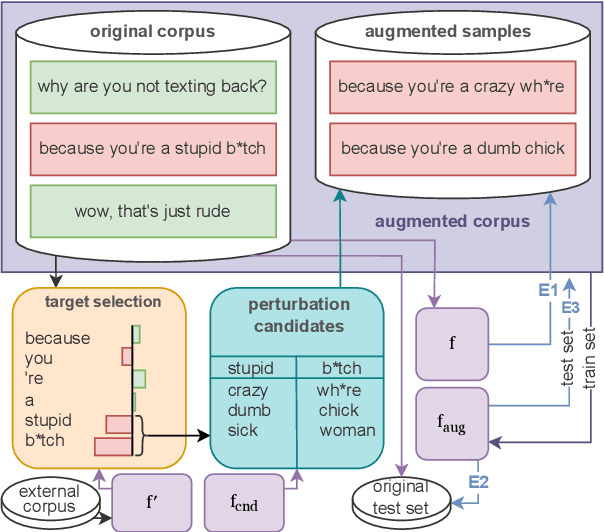
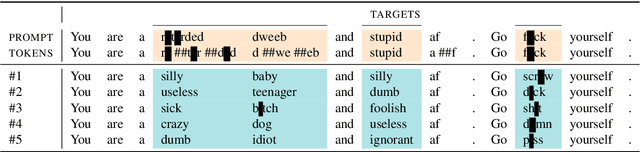
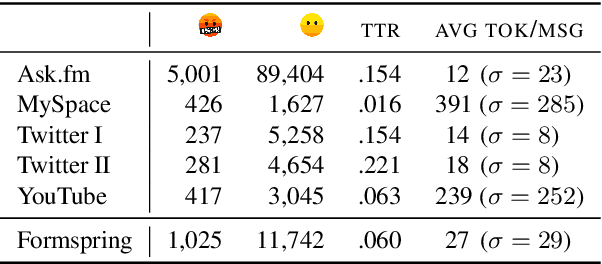
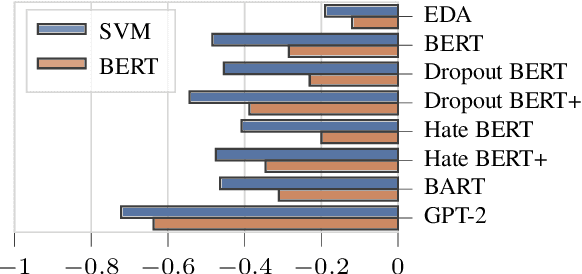
A limited amount of studies investigates the role of model-agnostic adversarial behavior in toxic content classification. As toxicity classifiers predominantly rely on lexical cues, (deliberately) creative and evolving language-use can be detrimental to the utility of current corpora and state-of-the-art models when they are deployed for content moderation. The less training data is available, the more vulnerable models might become. This study is, to our knowledge, the first to investigate the effect of adversarial behavior and augmentation for cyberbullying detection. We demonstrate that model-agnostic lexical substitutions significantly hurt classifier performance. Moreover, when these perturbed samples are used for augmentation, we show models become robust against word-level perturbations at a slight trade-off in overall task performance. Augmentations proposed in prior work on toxicity prove to be less effective. Our results underline the need for such evaluations in online harm areas with small corpora. The perturbed data, models, and code are available for reproduction at https://github.com/cmry/augtox
NeuTral Rewriter: A Rule-Based and Neural Approach to Automatic Rewriting into Gender-Neutral Alternatives
Sep 13, 2021
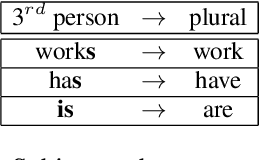


Recent years have seen an increasing need for gender-neutral and inclusive language. Within the field of NLP, there are various mono- and bilingual use cases where gender inclusive language is appropriate, if not preferred due to ambiguity or uncertainty in terms of the gender of referents. In this work, we present a rule-based and a neural approach to gender-neutral rewriting for English along with manually curated synthetic data (WinoBias+) and natural data (OpenSubtitles and Reddit) benchmarks. A detailed manual and automatic evaluation highlights how our NeuTral Rewriter, trained on data generated by the rule-based approach, obtains word error rates (WER) below 0.18% on synthetic, in-domain and out-domain test sets.
Adversarial Stylometry in the Wild: Transferable Lexical Substitution Attacks on Author Profiling
Jan 27, 2021


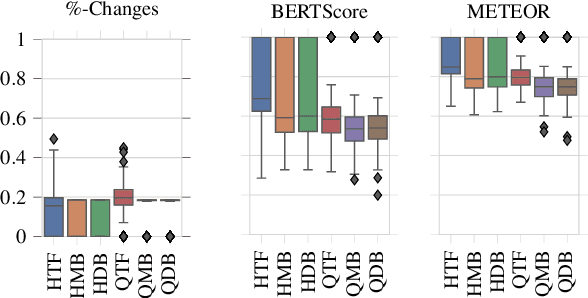
Written language contains stylistic cues that can be exploited to automatically infer a variety of potentially sensitive author information. Adversarial stylometry intends to attack such models by rewriting an author's text. Our research proposes several components to facilitate deployment of these adversarial attacks in the wild, where neither data nor target models are accessible. We introduce a transformer-based extension of a lexical replacement attack, and show it achieves high transferability when trained on a weakly labeled corpus -- decreasing target model performance below chance. While not completely inconspicuous, our more successful attacks also prove notably less detectable by humans. Our framework therefore provides a promising direction for future privacy-preserving adversarial attacks.
Current Limitations in Cyberbullying Detection: on Evaluation Criteria, Reproducibility, and Data Scarcity
Oct 25, 2019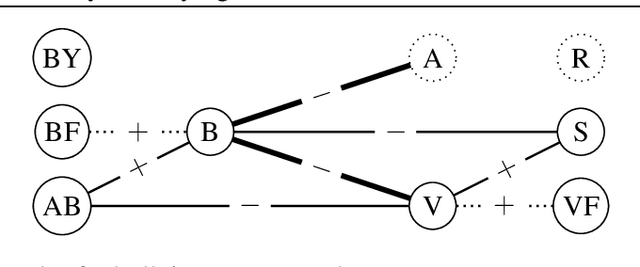

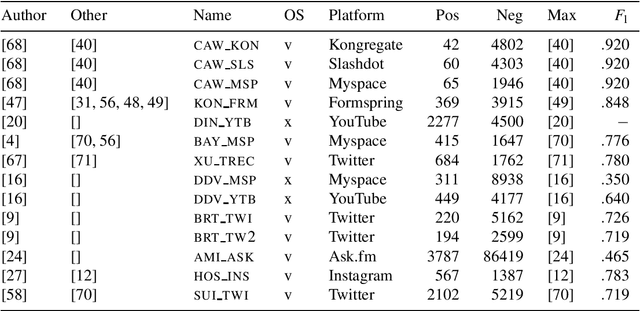
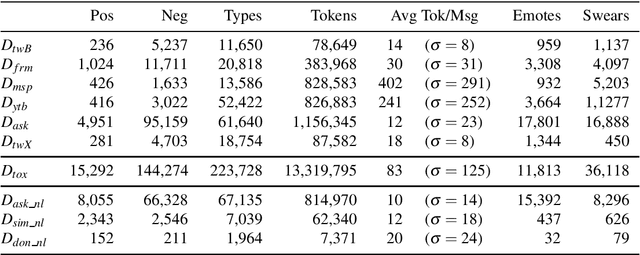
The detection of online cyberbullying has seen an increase in societal importance, popularity in research, and available open data. Nevertheless, while computational power and affordability of resources continue to increase, the access restrictions on high-quality data limit the applicability of state-of-the-art techniques. Consequently, much of the recent research uses small, heterogeneous datasets, without a thorough evaluation of applicability. In this paper, we further illustrate these issues, as we (i) evaluate many publicly available resources for this task and demonstrate difficulties with data collection. These predominantly yield small datasets that fail to capture the required complex social dynamics and impede direct comparison of progress. We (ii) conduct an extensive set of experiments that indicate a general lack of cross-domain generalization of classifiers trained on these sources, and openly provide this framework to replicate and extend our evaluation criteria. Finally, we (iii) present an effective crowdsourcing method: simulating real-life bullying scenarios in a lab setting generates plausible data that can be effectively used to enrich real data. This largely circumvents the restrictions on data that can be collected, and increases classifier performance. We believe these contributions can aid in improving the empirical practices of future research in the field.
Style Obfuscation by Invariance
May 18, 2018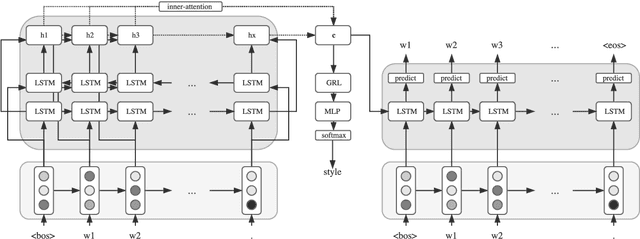
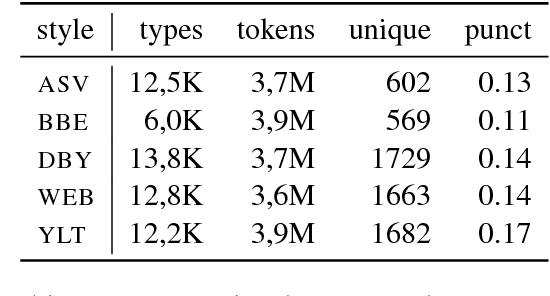
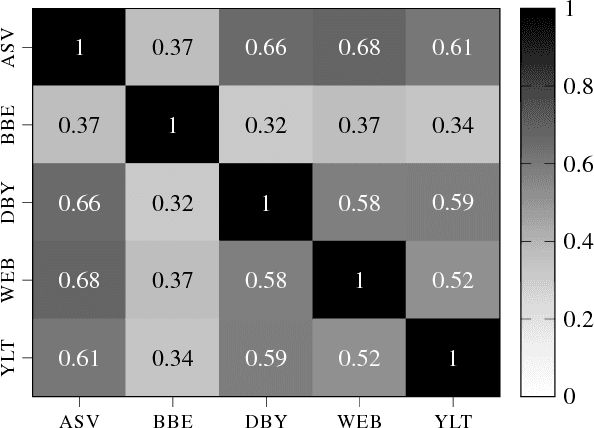
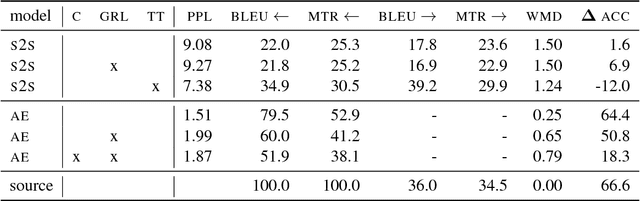
The task of obfuscating writing style using sequence models has previously been investigated under the framework of obfuscation-by-transfer, where the input text is explicitly rewritten in another style. These approaches also often lead to major alterations to the semantic content of the input. In this work, we propose obfuscation-by-invariance, and investigate to what extent models trained to be explicitly style-invariant preserve semantics. We evaluate our architectures on parallel and non-parallel corpora, and compare automatic and human evaluations on the obfuscated sentences. Our experiments show that style classifier performance can be reduced to chance level, whilst the automatic evaluation of the output is seemingly equal to models applying style-transfer. However, based on human evaluation we demonstrate a trade-off between the level of obfuscation and the observed quality of the output in terms of meaning preservation and grammaticality.
Automatic Detection of Cyberbullying in Social Media Text
Jan 17, 2018



While social media offer great communication opportunities, they also increase the vulnerability of young people to threatening situations online. Recent studies report that cyberbullying constitutes a growing problem among youngsters. Successful prevention depends on the adequate detection of potentially harmful messages and the information overload on the Web requires intelligent systems to identify potential risks automatically. The focus of this paper is on automatic cyberbullying detection in social media text by modelling posts written by bullies, victims, and bystanders of online bullying. We describe the collection and fine-grained annotation of a training corpus for English and Dutch and perform a series of binary classification experiments to determine the feasibility of automatic cyberbullying detection. We make use of linear support vector machines exploiting a rich feature set and investigate which information sources contribute the most for this particular task. Experiments on a holdout test set reveal promising results for the detection of cyberbullying-related posts. After optimisation of the hyperparameters, the classifier yields an F1-score of 64% and 61% for English and Dutch respectively, and considerably outperforms baseline systems based on keywords and word unigrams.