 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereotype Detection in Natural Language Processing
May 23, 2025Stereotypes influence social perceptions and can escalate into discrimination and violence. While NLP research has extensively addressed gender bias and hate speech, stereotype detection remains an emerging field with significant societal implications. In this work is presented a survey of existing research, analyzing definitions from psychology, sociology, and philosophy. A semi-automatic literature review was performed by using Semantic Scholar. We retrieved and filtered over 6,000 papers (in the year range 2000-2025), identifying key trends, methodologies, challenges and future directions. The findings emphasize stereotype detection as a potential early-monitoring tool to prevent bias escalation and the rise of hate speech. Conclusions highlight the need for a broader, multilingual, and intersectional approach in NLP studies.
LT3 at SemEval-2020 Task 9: Cross-lingual Embeddings for Sentiment Analysis of Hinglish Social Media Text
Oct 21, 2020
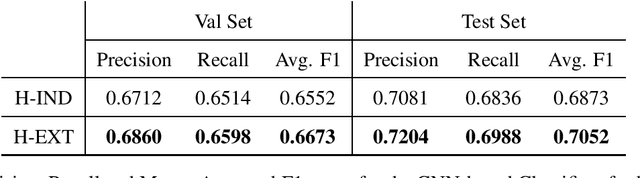
This paper describes our contribution to the SemEval-2020 Task 9 on Sentiment Analysis for Code-mixed Social Media Text. We investigated two approaches to solve the task of Hinglish sentiment analysis. The first approach uses cross-lingual embeddings resulting from projecting Hinglish and pre-trained English FastText word embeddings in the same space. The second approach incorporates pre-trained English embeddings that are incrementally retrained with a set of Hinglish tweets. The results show that the second approach performs best, with an F1-score of 70.52% on the held-out test data.
Current Limitations in Cyberbullying Detection: on Evaluation Criteria, Reproducibility, and Data Scarcity
Oct 25, 2019

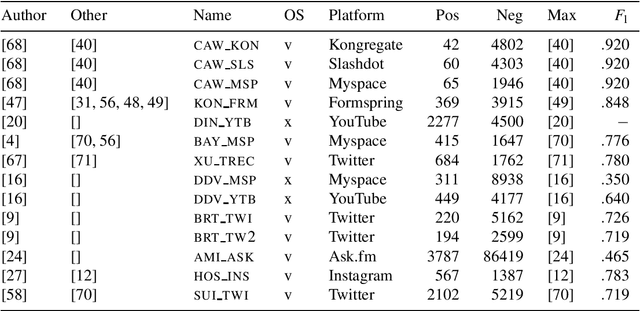
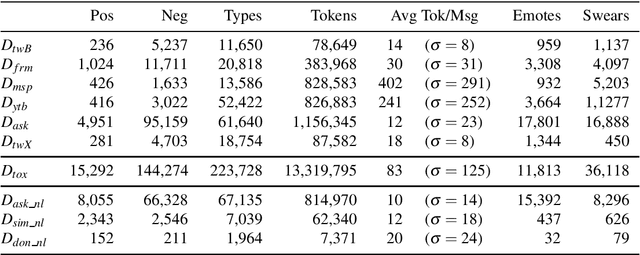
The detection of online cyberbullying has seen an increase in societal importance, popularity in research, and available open data. Nevertheless, while computational power and affordability of resources continue to increase, the access restrictions on high-quality data limit the applicability of state-of-the-art techniques. Consequently, much of the recent research uses small, heterogeneous datasets, without a thorough evaluation of applicability. In this paper, we further illustrate these issues, as we (i) evaluate many publicly available resources for this task and demonstrate difficulties with data collection. These predominantly yield small datasets that fail to capture the required complex social dynamics and impede direct comparison of progress. We (ii) conduct an extensive set of experiments that indicate a general lack of cross-domain generalization of classifiers trained on these sources, and openly provide this framework to replicate and extend our evaluation criteria. Finally, we (iii) present an effective crowdsourcing method: simulating real-life bullying scenarios in a lab setting generates plausible data that can be effectively used to enrich real data. This largely circumvents the restrictions on data that can be collected, and increases classifier performance. We believe these contributions can aid in improving the empirical practices of future research in the field.
Automatic Detection of Cyberbullying in Social Media Text
Jan 17, 2018



While social media offer great communication opportunities, they also increase the vulnerability of young people to threatening situations online. Recent studies report that cyberbullying constitutes a growing problem among youngsters. Successful prevention depends on the adequate detection of potentially harmful messages and the information overload on the Web requires intelligent systems to identify potential risks automatically. The focus of this paper is on automatic cyberbullying detection in social media text by modelling posts written by bullies, victims, and bystanders of online bullying. We describe the collection and fine-grained annotation of a training corpus for English and Dutch and perform a series of binary classification experiments to determine the feasibility of automatic cyberbullying detection. We make use of linear support vector machines exploiting a rich feature set and investigate which information sources contribute the most for this particular task. Experiments on a holdout test set reveal promising results for the detection of cyberbullying-related posts. After optimisation of the hyperparameters, the classifier yields an F1-score of 64% and 61% for English and Dutch respectively, and considerably outperforms baseline systems based on keywords and word unigrams.