 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes BERT Understand Sentiment? Leveraging Comparisons Between Contextual and Non-Contextual Embeddings to Improve Aspect-Based Sentiment Models
Nov 23, 2020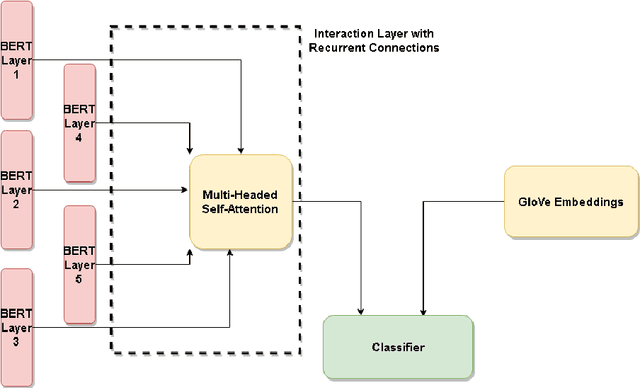
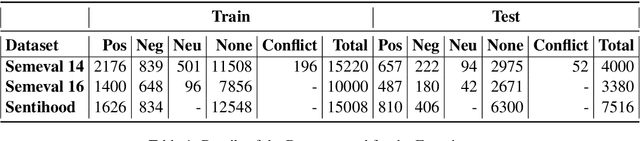

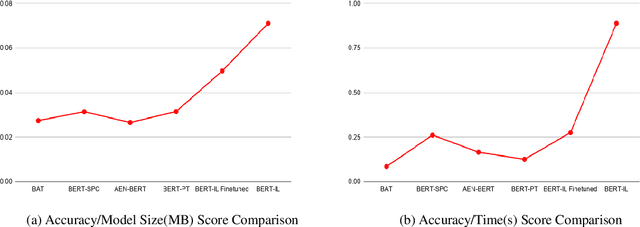
When performing Polarity Detection for different words in a sentence, we need to look at the words around to understand the sentiment. Massively pretrained language models like BERT can encode not only just the words in a document but also the context around the words along with them. This begs the questions, "Does a pretrain language model also automatically encode sentiment information about each word?" and "Can it be used to infer polarity towards different aspects?". In this work we try to answer this question by showing that training a comparison of a contextual embedding from BERT and a generic word embedding can be used to infer sentiment. We also show that if we finetune a subset of weights the model built on comparison of BERT and generic word embedding, it can get state of the art results for Polarity Detection in Aspect Based Sentiment Classification datasets.
LT3 at SemEval-2020 Task 9: Cross-lingual Embeddings for Sentiment Analysis of Hinglish Social Media Text
Oct 21, 2020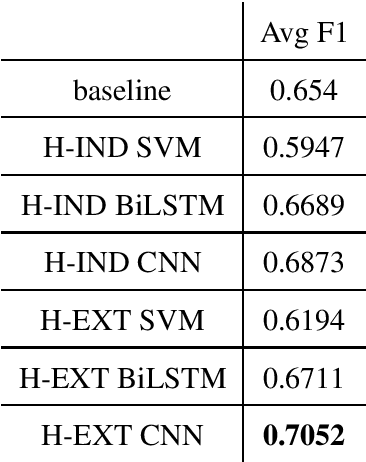
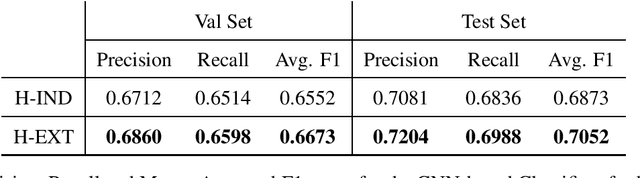
This paper describes our contribution to the SemEval-2020 Task 9 on Sentiment Analysis for Code-mixed Social Media Text. We investigated two approaches to solve the task of Hinglish sentiment analysis. The first approach uses cross-lingual embeddings resulting from projecting Hinglish and pre-trained English FastText word embeddings in the same space. The second approach incorporates pre-trained English embeddings that are incrementally retrained with a set of Hinglish tweets. The results show that the second approach performs best, with an F1-score of 70.52% on the held-out test data.
Multidomain Document Layout Understanding using Few Shot Object Detection
Aug 22, 2018
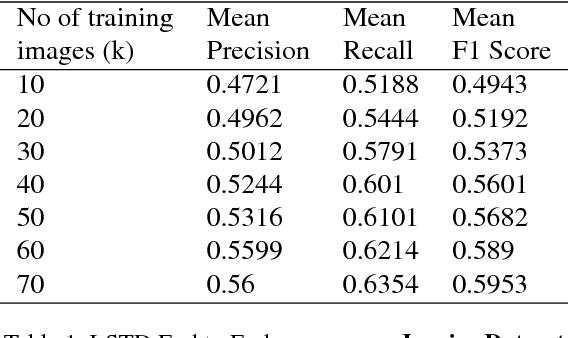
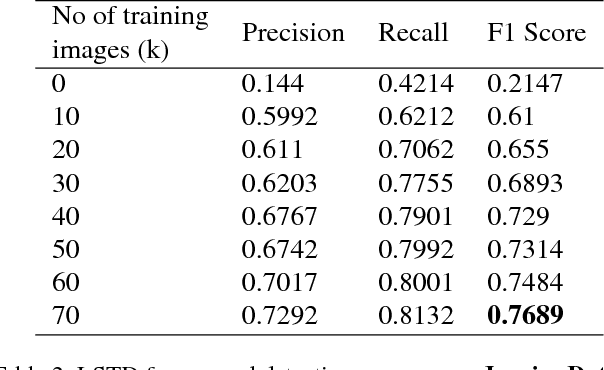
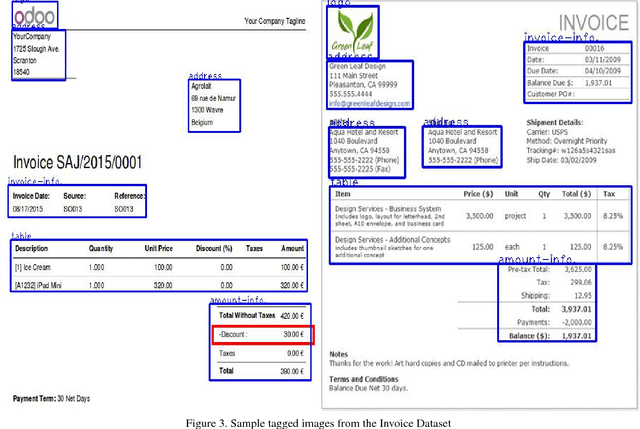
We try to address the problem of document layout understanding using a simple algorithm which generalizes across multiple domains while training on just few examples per domain. We approach this problem via supervised object detection method and propose a methodology to overcome the requirement of large datasets. We use the concept of transfer learning by pre-training our object detector on a simple artificial (source) dataset and fine-tuning it on a tiny domain specific (target) dataset. We show that this methodology works for multiple domains with training samples as less as 10 documents. We demonstrate the effect of each component of the methodology in the end result and show the superiority of this methodology over simple object detectors.