 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Chatbot Text: A Sequence-to-Sequence Approach
Jun 15, 2025Due to advances in Large Language Models (LLMs) such as ChatGPT, the boundary between human-written text and AI-generated text has become blurred. Nevertheless, recent work has demonstrated that it is possible to reliably detect GPT-generated text. In this paper, we adopt a novel strategy to adversarially transform GPT-generated text using sequence-to-sequence (Seq2Seq) models, with the goal of making the text more human-like. We experiment with the Seq2Seq models T5-small and BART which serve to modify GPT-generated sentences to include linguistic, structural, and semantic components that may be more typical of human-authored text. Experiments show that classification models trained to distinguish GPT-generated text are significantly less accurate when tested on text that has been modified by these Seq2Seq models. However, after retraining classification models on data generated by our Seq2Seq technique, the models are able to distinguish the transformed GPT-generated text from human-generated text with high accuracy. This work adds to the accumulating knowledge of text transformation as a tool for both attack -- in the sense of defeating classification models -- and defense -- in the sense of improved classifiers -- thereby advancing our understanding of AI-generated text.
Using Psuedolabels for training Sentiment Classifiers makes the model generalize better across datasets
Oct 05, 2021
The problem statement addressed in this work is : For a public sentiment classification API, how can we set up a classifier that works well on different types of data, having limited ability to annotate data from across domains. We show that given a large amount of unannotated data from across different domains and pseudolabels on this dataset generated by a classifier trained on a small annotated dataset from one domain, we can train a sentiment classifier that generalizes better across different datasets.
Does BERT Understand Sentiment? Leveraging Comparisons Between Contextual and Non-Contextual Embeddings to Improve Aspect-Based Sentiment Models
Nov 23, 2020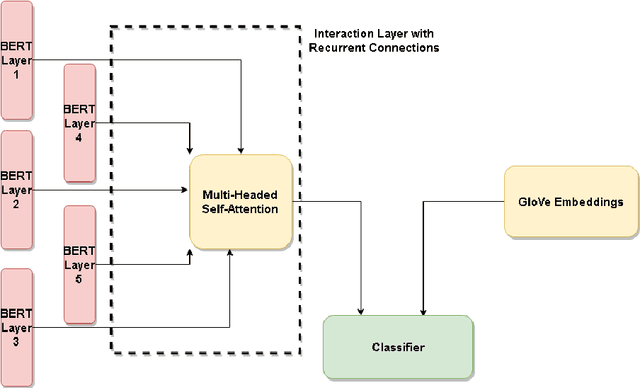
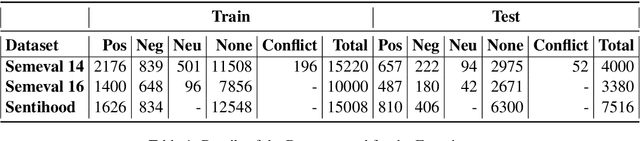

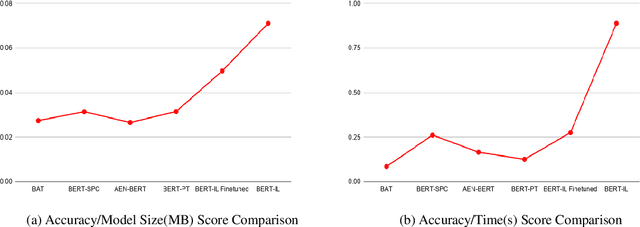
When performing Polarity Detection for different words in a sentence, we need to look at the words around to understand the sentiment. Massively pretrained language models like BERT can encode not only just the words in a document but also the context around the words along with them. This begs the questions, "Does a pretrain language model also automatically encode sentiment information about each word?" and "Can it be used to infer polarity towards different aspects?". In this work we try to answer this question by showing that training a comparison of a contextual embedding from BERT and a generic word embedding can be used to infer sentiment. We also show that if we finetune a subset of weights the model built on comparison of BERT and generic word embedding, it can get state of the art results for Polarity Detection in Aspect Based Sentiment Classification datasets.