 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetailKLIP : Finetuning OpenCLIP backbone using metric learning on a single GPU for Zero-shot retail product image classification
Dec 16, 2023Retail product or packaged grocery goods images need to classified in various computer vision applications like self checkout stores, supply chain automation and retail execution evaluation. Previous works explore ways to finetune deep models for this purpose. But because of the fact that finetuning a large model or even linear layer for a pretrained backbone requires to run at least a few epochs of gradient descent for every new retail product added in classification range, frequent retrainings are needed in a real world scenario. In this work, we propose finetuning the vision encoder of a CLIP model in a way that its embeddings can be easily used for nearest neighbor based classification, while also getting accuracy close to or exceeding full finetuning. A nearest neighbor based classifier needs no incremental training for new products, thus saving resources and wait time.
Machine Learning approaches to do size based reasoning on Retail Shelf objects to classify product variants
Oct 07, 2021

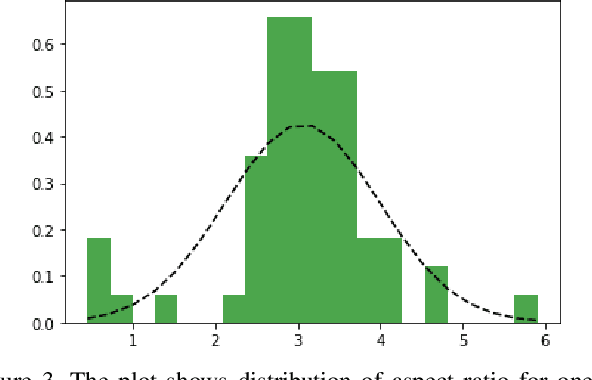

There has been a surge in the number of Machine Learning methods to analyze products kept on retail shelves images. Deep learning based computer vision methods can be used to detect products on retail shelves and then classify them. However, there are different sized variants of products which look exactly the same visually and the method to differentiate them is to look at their relative sizes with other products on shelves. This makes the process of deciphering the sized based variants from each other using computer vision algorithms alone impractical. In this work, we propose methods to ascertain the size variant of the product as a downstream task to an object detector which extracts products from shelf and a classifier which determines product brand. Product variant determination is the task which assigns a product variant to products of a brand based on the size of bounding boxes and brands predicted by classifier. While gradient boosting based methods work well for products whose facings are clear and distinct, a noise accommodating Neural Network method is proposed for cases where the products are stacked irregularly.
Using Keypoint Matching and Interactive Self Attention Network to verify Retail POSMs
Oct 07, 2021
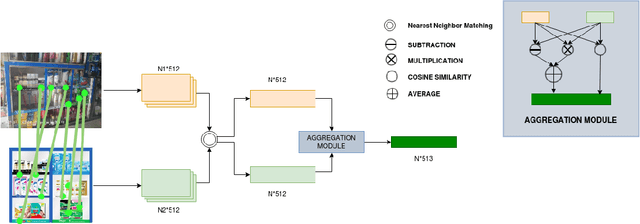
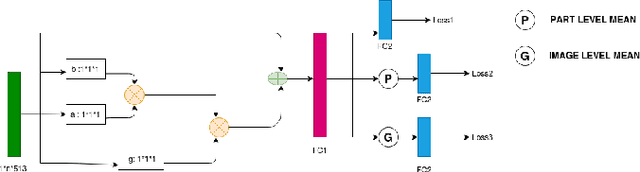
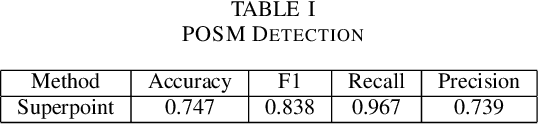
Point of Sale Materials(POSM) are the merchandising and decoration items that are used by companies to communicate product information and offers in retail stores. POSMs are part of companies' retail marketing strategy and are often applied as stylized window displays around retail shelves. In this work, we apply computer vision techniques to the task of verification of POSMs in supermarkets by telling if all desired components of window display are present in a shelf image. We use Convolutional Neural Network based unsupervised keypoint matching as a baseline to verify POSM components and propose a supervised Neural Network based method to enhance the accuracy of baseline by a large margin. We also show that the supervised pipeline is not restricted to the POSM material it is trained on and can generalize. We train and evaluate our model on a private dataset composed of retail shelf images.
Using Contrastive Learning and Pseudolabels to learn representations for Retail Product Image Classification
Oct 07, 2021



Retail product Image classification problems are often few shot classification problems, given retail product classes cannot have the type of variations across images like a cat or dog or tree could have. Previous works have shown different methods to finetune Convolutional Neural Networks to achieve better classification accuracy on such datasets. In this work, we try to address the problem statement : Can we pretrain a Convolutional Neural Network backbone which yields good enough representations for retail product images, so that training a simple logistic regression on these representations gives us good classifiers ? We use contrastive learning and pseudolabel based noisy student training to learn representations that get accuracy in order of finetuning the entire Convnet backbone for retail product image classification.
Using Psuedolabels for training Sentiment Classifiers makes the model generalize better across datasets
Oct 05, 2021
The problem statement addressed in this work is : For a public sentiment classification API, how can we set up a classifier that works well on different types of data, having limited ability to annotate data from across domains. We show that given a large amount of unannotated data from across different domains and pseudolabels on this dataset generated by a classifier trained on a small annotated dataset from one domain, we can train a sentiment classifier that generalizes better across different datasets.
Semi-supervised Learning for Dense Object Detection in Retail Scenes
Jul 05, 2021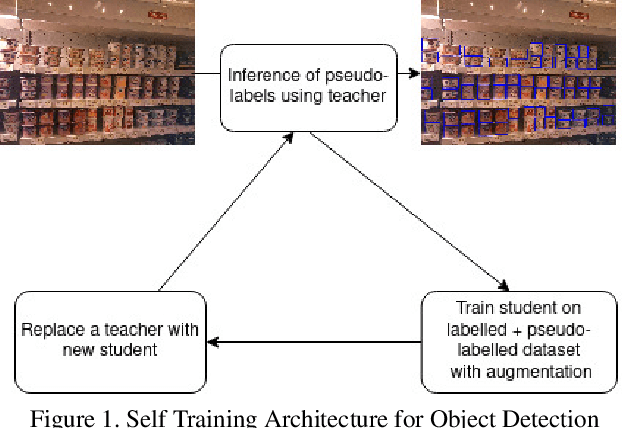
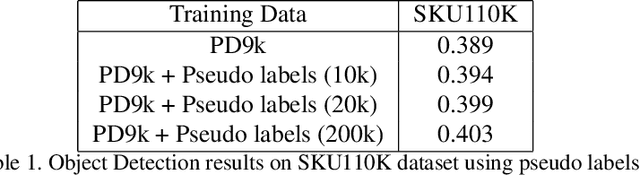
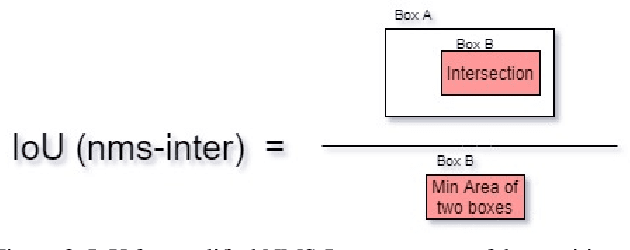
Retail scenes usually contain densely packed high number of objects in each image. Standard object detection techniques use fully supervised training methodology. This is highly costly as annotating a large dense retail object detection dataset involves an order of magnitude more effort compared to standard datasets. Hence, we propose semi-supervised learning to effectively use the large amount of unlabeled data available in the retail domain. We adapt a popular self supervised method called noisy student initially proposed for object classification to the task of dense object detection. We show that using unlabeled data with the noisy student training methodology, we can improve the state of the art on precise detection of objects in densely packed retail scenes. We also show that performance of the model increases as you increase the amount of unlabeled data.
Does BERT Understand Sentiment? Leveraging Comparisons Between Contextual and Non-Contextual Embeddings to Improve Aspect-Based Sentiment Models
Nov 23, 2020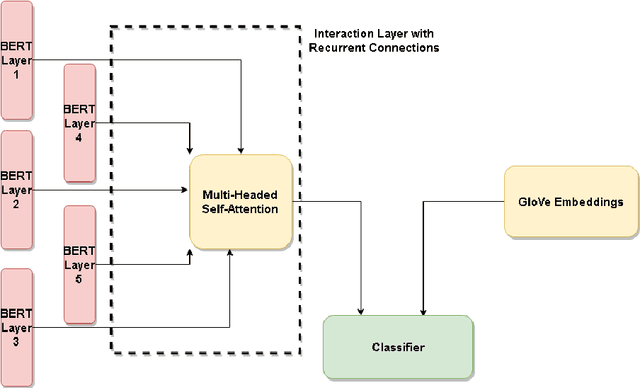

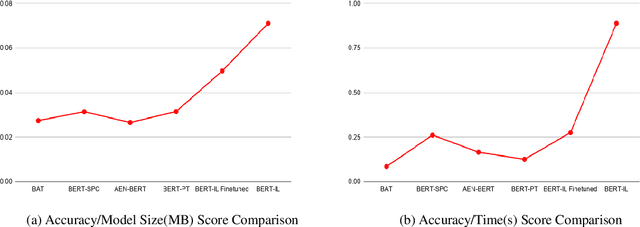
When performing Polarity Detection for different words in a sentence, we need to look at the words around to understand the sentiment. Massively pretrained language models like BERT can encode not only just the words in a document but also the context around the words along with them. This begs the questions, "Does a pretrain language model also automatically encode sentiment information about each word?" and "Can it be used to infer polarity towards different aspects?". In this work we try to answer this question by showing that training a comparison of a contextual embedding from BERT and a generic word embedding can be used to infer sentiment. We also show that if we finetune a subset of weights the model built on comparison of BERT and generic word embedding, it can get state of the art results for Polarity Detection in Aspect Based Sentiment Classification datasets.
Compact retail shelf segmentation for mobile deployment
Apr 27, 2020



The recent surge of automation in the retail industries has rapidly increased demand for applying deep learning models on mobile devices. To make the deep learning models real-time on-device, a compact efficient network becomes inevitable. In this paper, we work on one such common problem in the retail industries - Shelf segmentation. Shelf segmentation can be interpreted as a pixel-wise classification problem, i.e., each pixel is classified as to whether they belong to visible shelf edges or not. The aim is not just to segment shelf edges, but also to deploy the model on mobile devices. As there is no standard solution for such dense classification problem on mobile devices, we look at semantic segmentation architectures which can be deployed on edge. We modify low-footprint semantic segmentation architectures to perform shelf segmentation. In addressing this issue, we modified the famous U-net architecture in certain aspects to make it fit for on-devices without impacting significant drop in accuracy and also with 15X fewer parameters. In this paper, we proposed Light Weight Segmentation Network (LWSNet), a small compact model able to run fast on devices with limited memory and can train with less amount (~ 100 images) of labeled data.
Bag of Tricks for Retail Product Image Classification
Jan 12, 2020



Retail Product Image Classification is an important Computer Vision and Machine Learning problem for building real world systems like self-checkout stores and automated retail execution evaluation. In this work, we present various tricks to increase accuracy of Deep Learning models on different types of retail product image classification datasets. These tricks enable us to increase the accuracy of fine tuned convnets for retail product image classification by a large margin. As the most prominent trick, we introduce a new neural network layer called Local-Concepts-Accumulation (LCA) layer which gives consistent gains across multiple datasets. Two other tricks we find to increase accuracy on retail product identification are using an instagram-pretrained Convnet and using Maximum Entropy as an auxiliary loss for classification.
Benchmark for Generic Product Detection: A Low Data Baseline for Dense Object Detection
Jan 08, 2020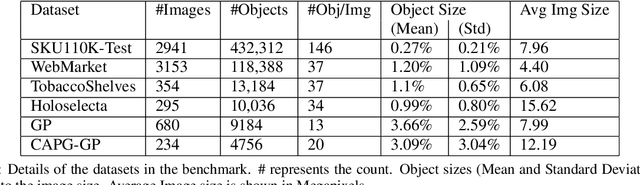

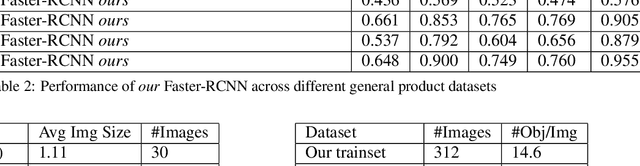

Object detection in densely packed scenes is a new area where standard object detectors fail to train well. Dense object detectors like RetinaNet trained on large and dense datasets show great performance. We train a standard object detector on a small, normally packed dataset with data augmentation techniques. This dataset is 265 times smaller than the standard dataset, in terms of number of annotations. This low data baseline achieves satisfactory results (mAP=0.56) at standard IoU of 0.5. We also create a varied benchmark for generic SKU product detection by providing full annotations for multiple public datasets. It can be accessed at https://github.com/ParallelDots/generic-sku-detection-benchmark. We hope that this benchmark helps in building robust detectors that perform reliably across different settings in the wild.