 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning for Dense Object Detection in Retail Scenes
Jul 05, 2021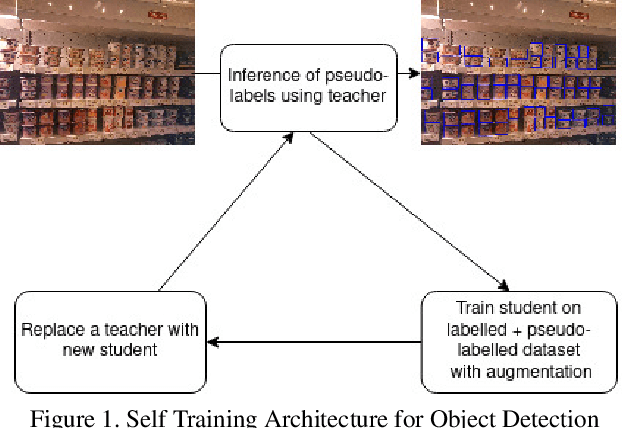
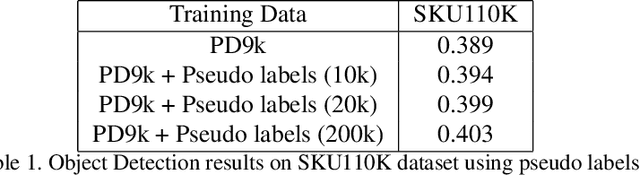
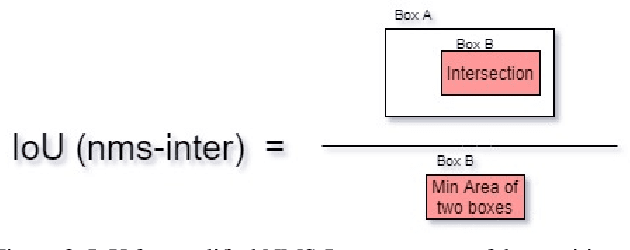
Retail scenes usually contain densely packed high number of objects in each image. Standard object detection techniques use fully supervised training methodology. This is highly costly as annotating a large dense retail object detection dataset involves an order of magnitude more effort compared to standard datasets. Hence, we propose semi-supervised learning to effectively use the large amount of unlabeled data available in the retail domain. We adapt a popular self supervised method called noisy student initially proposed for object classification to the task of dense object detection. We show that using unlabeled data with the noisy student training methodology, we can improve the state of the art on precise detection of objects in densely packed retail scenes. We also show that performance of the model increases as you increase the amount of unlabeled data.
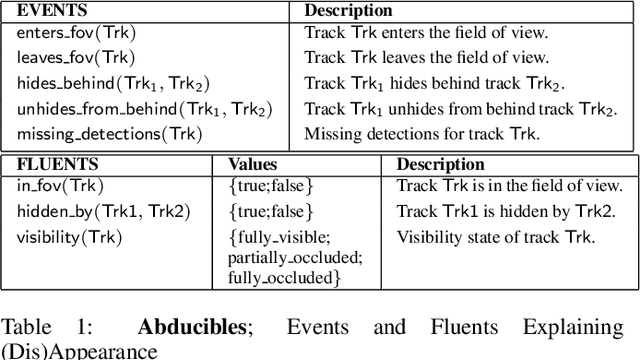
Commonsense Visual Sensemaking for Autonomous Driving: On Generalised Neurosymbolic Online Abduction Integrating Vision and Semantics
Dec 28, 2020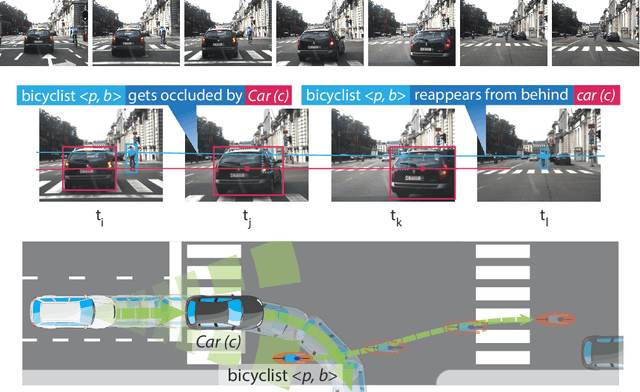


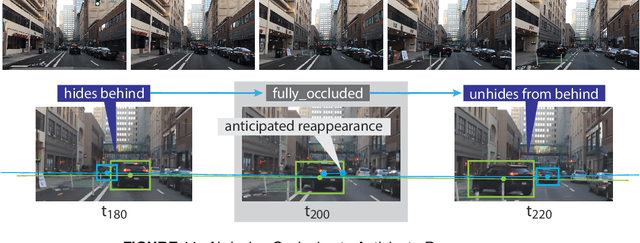
We demonstrate the need and potential of systematically integrated vision and semantics solutions for visual sensemaking in the backdrop of autonomous driving. A general neurosymbolic method for online visual sensemaking using answer set programming (ASP) is systematically formalised and fully implemented. The method integrates state of the art in visual computing, and is developed as a modular framework that is generally usable within hybrid architectures for realtime perception and control. We evaluate and demonstrate with community established benchmarks KITTIMOD, MOT-2017, and MOT-2020. As use-case, we focus on the significance of human-centred visual sensemaking -- e.g., involving semantic representation and explainability, question-answering, commonsense interpolation -- in safety-critical autonomous driving situations. The developed neurosymbolic framework is domain-independent, with the case of autonomous driving designed to serve as an exemplar for online visual sensemaking in diverse cognitive interaction settings in the backdrop of select human-centred AI technology design considerations. Keywords: Cognitive Vision, Deep Semantics, Declarative Spatial Reasoning, Knowledge Representation and Reasoning, Commonsense Reasoning, Visual Abduction, Answer Set Programming, Autonomous Driving, Human-Centred Computing and Design, Standardisation in Driving Technology, Spatial Cognition and AI.
Benchmark for Generic Product Detection: A Low Data Baseline for Dense Object Detection
Jan 08, 2020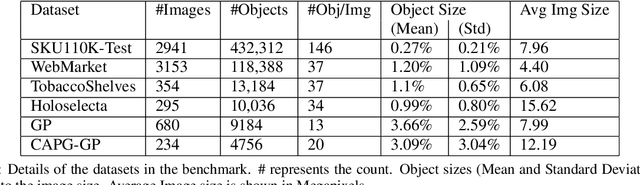

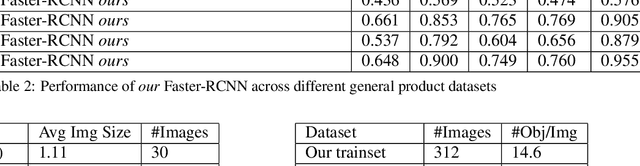

Object detection in densely packed scenes is a new area where standard object detectors fail to train well. Dense object detectors like RetinaNet trained on large and dense datasets show great performance. We train a standard object detector on a small, normally packed dataset with data augmentation techniques. This dataset is 265 times smaller than the standard dataset, in terms of number of annotations. This low data baseline achieves satisfactory results (mAP=0.56) at standard IoU of 0.5. We also create a varied benchmark for generic SKU product detection by providing full annotations for multiple public datasets. It can be accessed at https://github.com/ParallelDots/generic-sku-detection-benchmark. We hope that this benchmark helps in building robust detectors that perform reliably across different settings in the wild.
Out of Sight But Not Out of Mind: An Answer Set Programming Based Online Abduction Framework for Visual Sensemaking in Autonomous Driving
May 31, 2019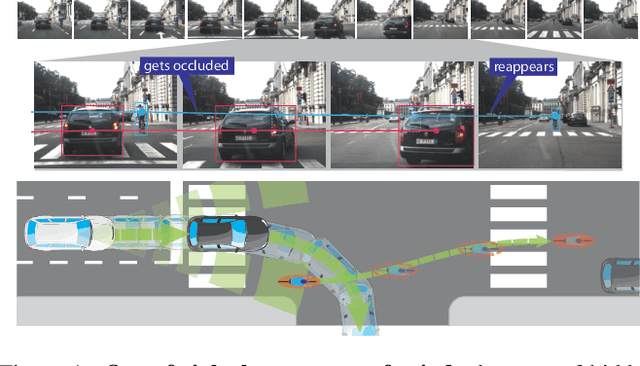

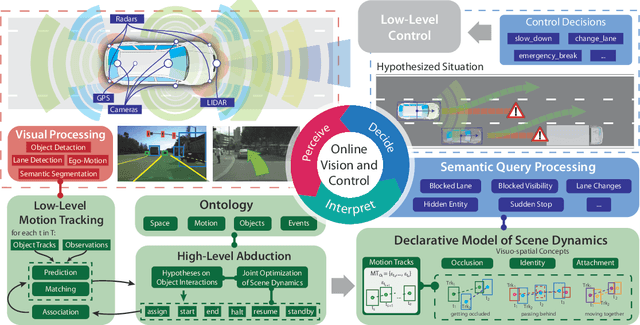
We demonstrate the need and potential of systematically integrated vision and semantics} solutions for visual sensemaking (in the backdrop of autonomous driving). A general method for online visual sensemaking using answer set programming is systematically formalised and fully implemented. The method integrates state of the art in (deep learning based) visual computing, and is developed as a modular framework usable within hybrid architectures for perception & control. We evaluate and demo with community established benchmarks KITTIMOD and MOT. As use-case, we focus on the significance of human-centred visual sensemaking ---e.g., semantic representation and explainability, question-answering, commonsense interpolation--- in safety-critical autonomous driving situations.
Multidomain Document Layout Understanding using Few Shot Object Detection
Aug 22, 2018
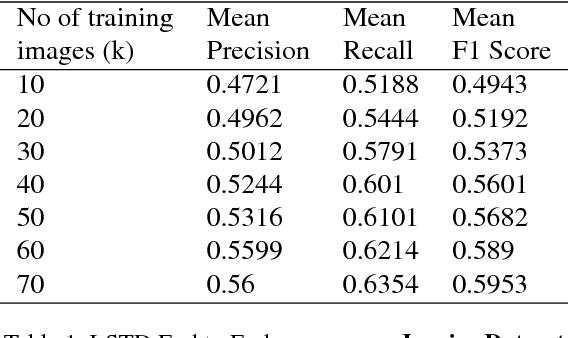
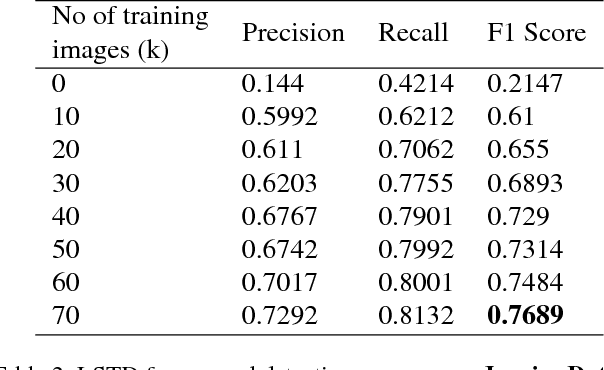
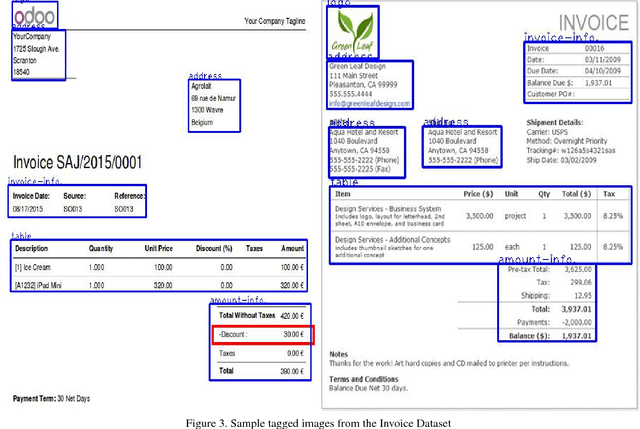
We try to address the problem of document layout understanding using a simple algorithm which generalizes across multiple domains while training on just few examples per domain. We approach this problem via supervised object detection method and propose a methodology to overcome the requirement of large datasets. We use the concept of transfer learning by pre-training our object detector on a simple artificial (source) dataset and fine-tuning it on a tiny domain specific (target) dataset. We show that this methodology works for multiple domains with training samples as less as 10 documents. We demonstrate the effect of each component of the methodology in the end result and show the superiority of this methodology over simple object detectors.
Weakly Supervised Object Localization on grocery shelves using simple FCN and Synthetic Dataset
Mar 19, 2018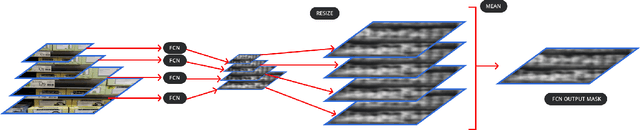



We propose a weakly supervised method using two algorithms to predict object bounding boxes given only an image classification dataset. First algorithm is a simple Fully Convolutional Network (FCN) trained to classify object instances. We use the property of FCN to return a mask for images larger than training images to get a primary output segmentation mask during test time by passing an image pyramid to it. We enhance the FCN output mask into final output bounding boxes by a Convolutional Encoder-Decoder (ConvAE) viz. the second algorithm. ConvAE is trained to localize objects on an artificially generated dataset of output segmentation masks. We demonstrate the effectiveness of this method in localizing objects in grocery shelves where annotating data for object detection is hard due to variety of objects. This method can be extended to any problem domain where collecting images of objects is easy and annotating their coordinates is hard.
Anatomical labeling of brain CT scan anomalies using multi-context nearest neighbor relation networks
Jan 22, 2018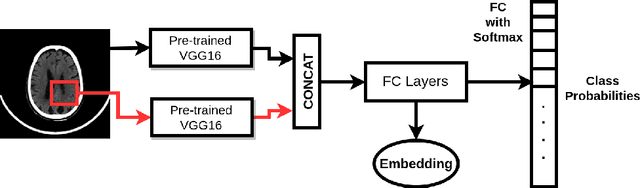
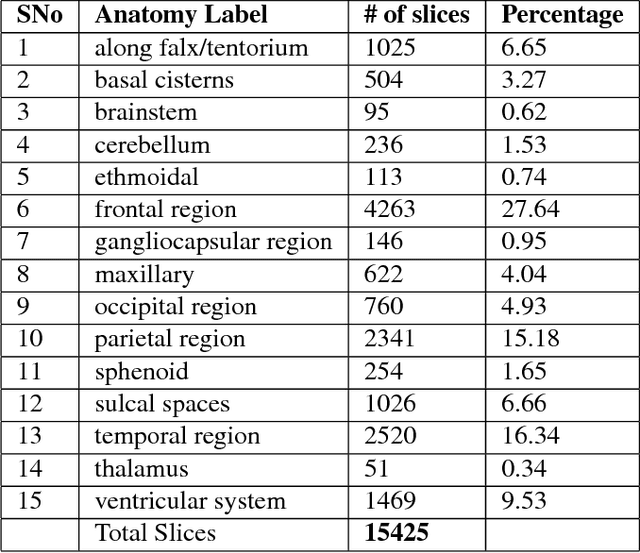
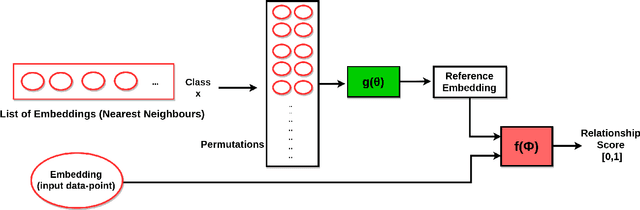
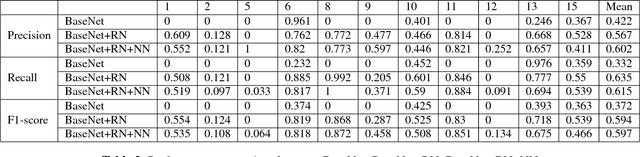
This work is an endeavor to develop a deep learning methodology for automated anatomical labeling of a given region of interest (ROI) in brain computed tomography (CT) scans. We combine both local and global context to obtain a representation of the ROI. We then use Relation Networks (RNs) to predict the corresponding anatomy of the ROI based on its relationship score for each class. Further, we propose a novel strategy employing nearest neighbors approach for training RNs. We train RNs to learn the relationship of the target ROI with the joint representation of its nearest neighbors in each class instead of all data-points in each class. The proposed strategy leads to better training of RNs along with increased performance as compared to training baseline RN network.
RADNET: Radiologist Level Accuracy using Deep Learning for HEMORRHAGE detection in CT Scans
Jan 03, 2018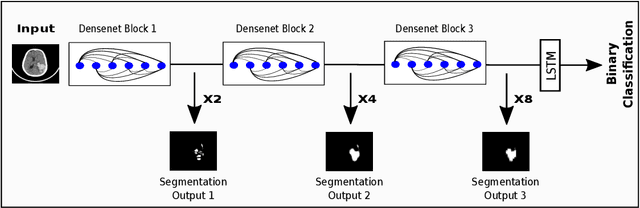
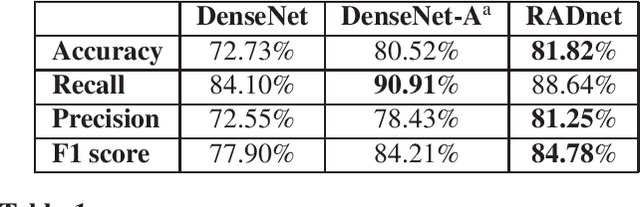
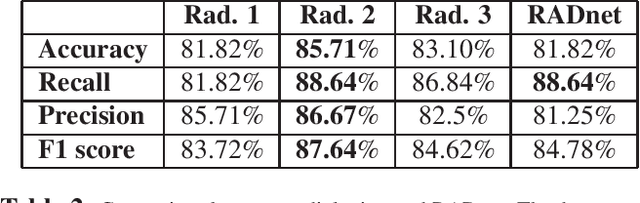
We describe a deep learning approach for automated brain hemorrhage detection from computed tomography (CT) scans. Our model emulates the procedure followed by radiologists to analyse a 3D CT scan in real-world. Similar to radiologists, the model sifts through 2D cross-sectional slices while paying close attention to potential hemorrhagic regions. Further, the model utilizes 3D context from neighboring slices to improve predictions at each slice and subsequently, aggregates the slice-level predictions to provide diagnosis at CT level. We refer to our proposed approach as Recurrent Attention DenseNet (RADnet) as it employs original DenseNet architecture along with adding the components of attention for slice level predictions and recurrent neural network layer for incorporating 3D context. The real-world performance of RADnet has been benchmarked against independent analysis performed by three senior radiologists for 77 brain CTs. RADnet demonstrates 81.82% hemorrhage prediction accuracy at CT level that is comparable to radiologists. Further, RADnet achieves higher recall than two of the three radiologists, which is remarkable.
Detection of Tooth caries in Bitewing Radiographs using Deep Learning
Nov 23, 2017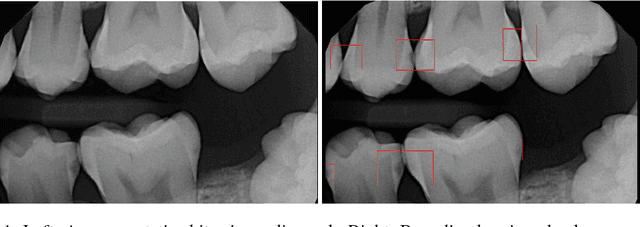
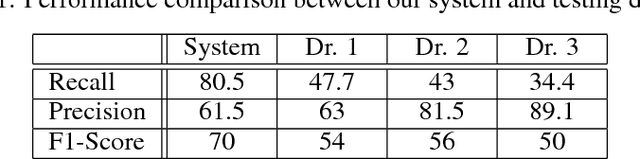
We develop a Computer Aided Diagnosis (CAD) system, which enhances the performance of dentists in detecting wide range of dental caries. The CAD System achieves this by acting as a second opinion for the dentists with way higher sensitivity on the task of detecting cavities than the dentists themselves. We develop annotated dataset of more than 3000 bitewing radiographs and utilize it for developing a system for automated diagnosis of dental caries. Our system consists of a deep fully convolutional neural network (FCNN) consisting 100+ layers, which is trained to mark caries on bitewing radiographs. We have compared the performance of our proposed system with three certified dentists for marking dental caries. We exceed the average performance of the dentists in both recall (sensitivity) and F1-Score (agreement with truth) by a very large margin. Working example of our system is shown in Figure 1.