 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Commonsense Driven Knowledge Refinements for Scene Graph Generation
Jun 04, 2026Learning-driven Scene Graph Generation (SGG) models excel on frequent relation types but degrade sharply under annotation sparsity, failing to capture reliable visual commonsense knowledge. We propose a model-agnostic, semantically-guided knowledge refinement framework that systematically mines commonsense-grounded constraints from training data - capturing spatial, functional, and qualitative relational regularities - and uses general declarative commonsense reasoning to correct and refine ranked SGG predictions at inference time. The framework requires no manual rule authoring, no model retraining, and transfers across datasets and architectures. On three standard benchmarks, we obtain consistent improvements over strong baselines, demonstrating that structured visual commonsense reasoning over deep scene semantics is a practical and effective complement to purely learning-based scene graph generation.
Assessing Drivers' Situation Awareness in Semi-Autonomous Vehicles: ASP based Characterisations of Driving Dynamics for Modelling Scene Interpretation and Projection
Aug 30, 2023Semi-autonomous driving, as it is already available today and will eventually become even more accessible, implies the need for driver and automation system to reliably work together in order to ensure safe driving. A particular challenge in this endeavour are situations in which the vehicle's automation is no longer able to drive and is thus requesting the human to take over. In these situations the driver has to quickly build awareness for the traffic situation to be able to take over control and safely drive the car. Within this context we present a software and hardware framework to asses how aware the driver is about the situation and to provide human-centred assistance to help in building situation awareness. The framework is developed as a modular system within the Robot Operating System (ROS) with modules for sensing the environment and the driver state, modelling the driver's situation awareness, and for guiding the driver's attention using specialized Human Machine Interfaces (HMIs). A particular focus of this paper is on an Answer Set Programming (ASP) based approach for modelling and reasoning about the driver's interpretation and projection of the scene. This is based on scene data, as well as eye-tracking data reflecting the scene elements observed by the driver. We present the overall application and discuss the role of semantic reasoning and modelling cognitive functions based on logic programming in such applications. Furthermore we present the ASP approach for interpretation and projection of the driver's situation awareness and its integration within the overall system in the context of a real-world use-case in simulated as well as in real driving.
* In Proceedings ICLP 2023, arXiv:2308.14898
Commonsense Visual Sensemaking for Autonomous Driving: On Generalised Neurosymbolic Online Abduction Integrating Vision and Semantics
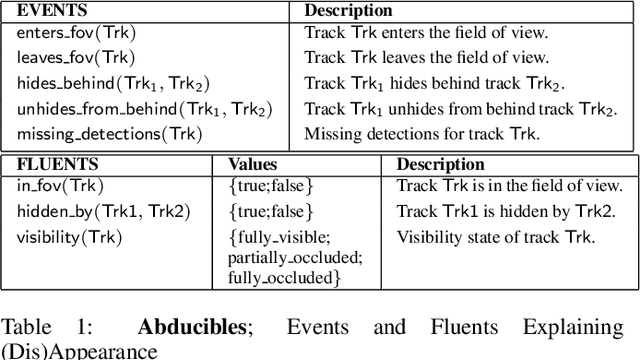
Dec 28, 2020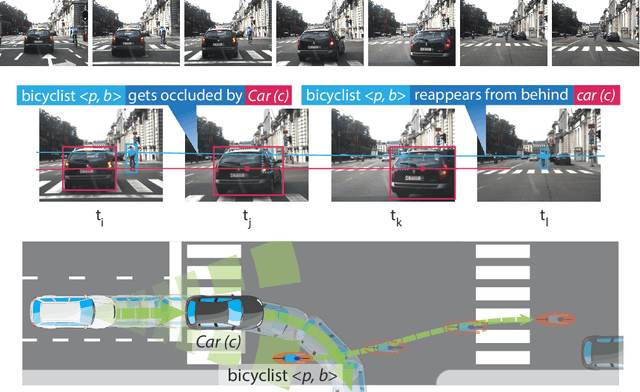


We demonstrate the need and potential of systematically integrated vision and semantics solutions for visual sensemaking in the backdrop of autonomous driving. A general neurosymbolic method for online visual sensemaking using answer set programming (ASP) is systematically formalised and fully implemented. The method integrates state of the art in visual computing, and is developed as a modular framework that is generally usable within hybrid architectures for realtime perception and control. We evaluate and demonstrate with community established benchmarks KITTIMOD, MOT-2017, and MOT-2020. As use-case, we focus on the significance of human-centred visual sensemaking -- e.g., involving semantic representation and explainability, question-answering, commonsense interpolation -- in safety-critical autonomous driving situations. The developed neurosymbolic framework is domain-independent, with the case of autonomous driving designed to serve as an exemplar for online visual sensemaking in diverse cognitive interaction settings in the backdrop of select human-centred AI technology design considerations. Keywords: Cognitive Vision, Deep Semantics, Declarative Spatial Reasoning, Knowledge Representation and Reasoning, Commonsense Reasoning, Visual Abduction, Answer Set Programming, Autonomous Driving, Human-Centred Computing and Design, Standardisation in Driving Technology, Spatial Cognition and AI.
Towards a Human-Centred Cognitive Model of Visuospatial Complexity in Everyday Driving
Jun 02, 2020



We develop a human-centred, cognitive model of visuospatial complexity in everyday, naturalistic driving conditions. With a focus on visual perception, the model incorporates quantitative, structural, and dynamic attributes identifiable in the chosen context; the human-centred basis of the model lies in its behavioural evaluation with human subjects with respect to psychophysical measures pertaining to embodied visuoauditory attention. We report preliminary steps to apply the developed cognitive model of visuospatial complexity for human-factors guided dataset creation and benchmarking, and for its use as a semantic template for the (explainable) computational analysis of visuospatial complexity.
Out of Sight But Not Out of Mind: An Answer Set Programming Based Online Abduction Framework for Visual Sensemaking in Autonomous Driving
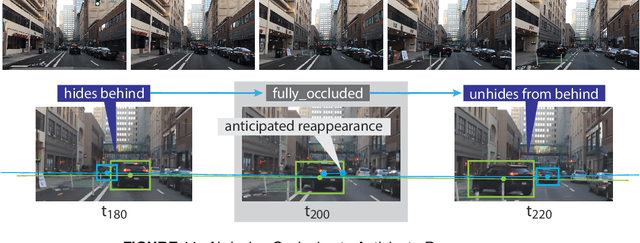
May 31, 2019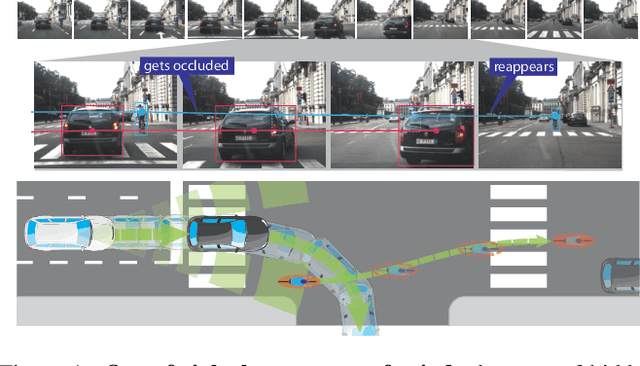

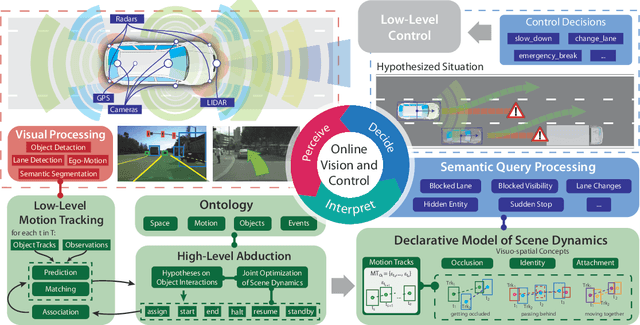
We demonstrate the need and potential of systematically integrated vision and semantics} solutions for visual sensemaking (in the backdrop of autonomous driving). A general method for online visual sensemaking using answer set programming is systematically formalised and fully implemented. The method integrates state of the art in (deep learning based) visual computing, and is developed as a modular framework usable within hybrid architectures for perception & control. We evaluate and demo with community established benchmarks KITTIMOD and MOT. As use-case, we focus on the significance of human-centred visual sensemaking ---e.g., semantic representation and explainability, question-answering, commonsense interpolation--- in safety-critical autonomous driving situations.
Semantic Analysis of Visual Symmetry: A Human-Centred Computational Model for Declarative Explainability
Sep 14, 2018
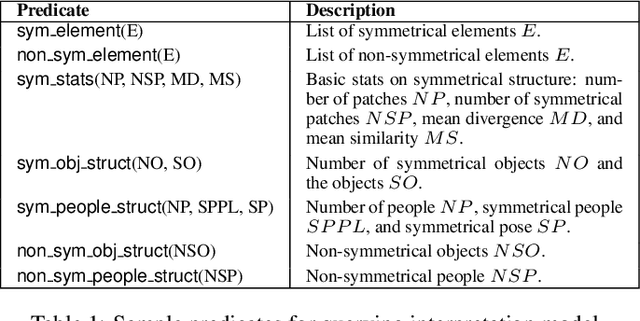

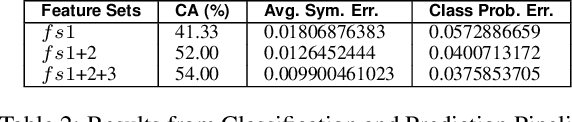
We present a computational model for the semantic interpretation of symmetry in naturalistic scenes. Key features include a human-centred representation, and a declarative, explainable interpretation model supporting deep semantic question-answering founded on an integration of methods in knowledge representation and deep learning based computer vision. In the backdrop of the visual arts, we showcase the framework's capability to generate human-centred, queryable, relational structures, also evaluating the framework with an empirical study on the human perception of visual symmetry. Our framework represents and is driven by the application of foundational, integrated Vision and Knowledge Representation and Reasoning methods for applications in the arts, and the psychological and social sciences.
* Preprint of accepted article / Journal: Advances in Cognitive Systems. ( http://www.cogsys.org/journal )
Answer Set Programming Modulo `Space-Time'
May 17, 2018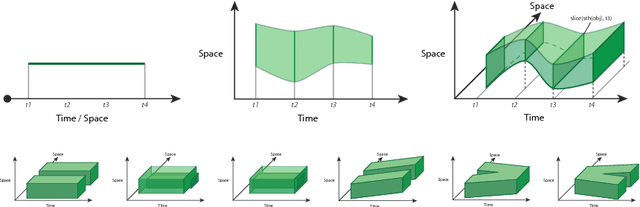

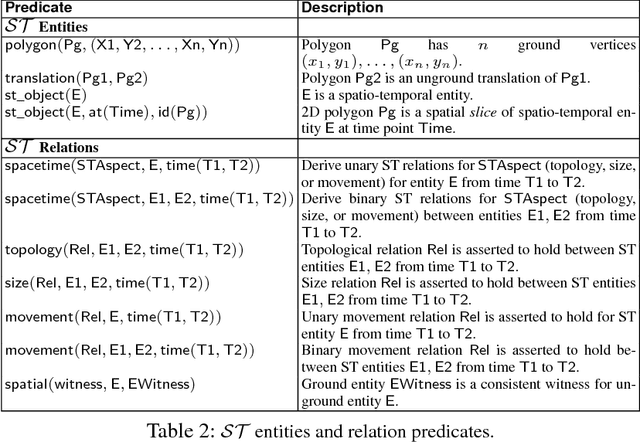
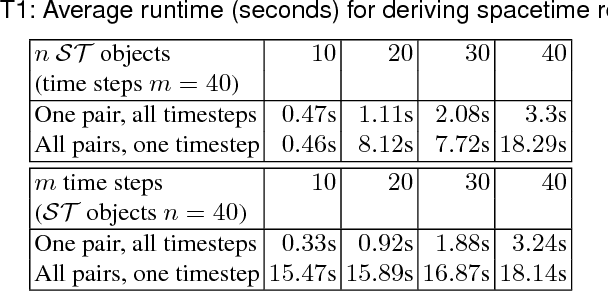
We present ASP Modulo `Space-Time', a declarative representational and computational framework to perform commonsense reasoning about regions with both spatial and temporal components. Supported are capabilities for mixed qualitative-quantitative reasoning, consistency checking, and inferring compositions of space-time relations; these capabilities combine and synergise for applications in a range of AI application areas where the processing and interpretation of spatio-temporal data is crucial. The framework and resulting system is the only general KR-based method for declaratively reasoning about the dynamics of `space-time' regions as first-class objects. We present an empirical evaluation (with scalability and robustness results), and include diverse application examples involving interpretation and control tasks.
Visual Explanation by High-Level Abduction: On Answer-Set Programming Driven Reasoning about Moving Objects
Dec 03, 2017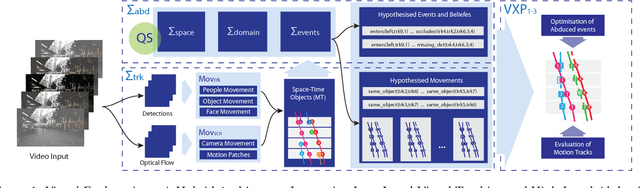
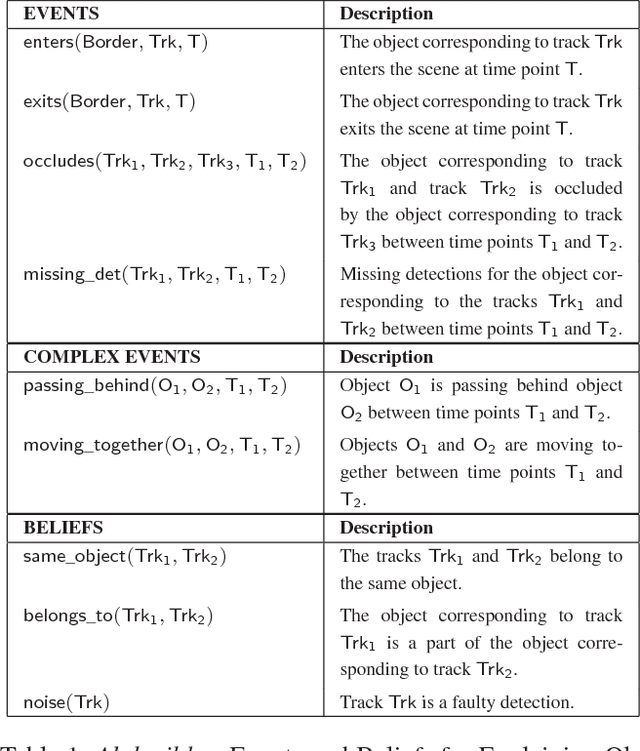


We propose a hybrid architecture for systematically computing robust visual explanation(s) encompassing hypothesis formation, belief revision, and default reasoning with video data. The architecture consists of two tightly integrated synergistic components: (1) (functional) answer set programming based abductive reasoning with space-time tracklets as native entities; and (2) a visual processing pipeline for detection based object tracking and motion analysis. We present the formal framework, its general implementation as a (declarative) method in answer set programming, and an example application and evaluation based on two diverse video datasets: the MOTChallenge benchmark developed by the vision community, and a recently developed Movie Dataset.
Deep Semantic Abstractions of Everyday Human Activities: On Commonsense Representations of Human Interactions
Oct 10, 2017

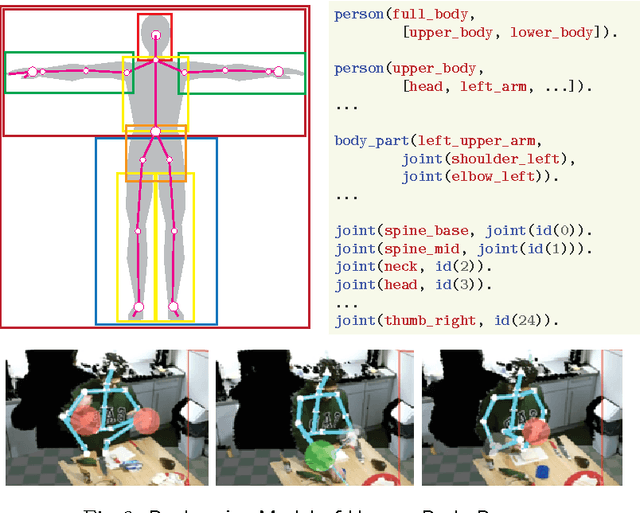

We propose a deep semantic characterization of space and motion categorically from the viewpoint of grounding embodied human-object interactions. Our key focus is on an ontological model that would be adept to formalisation from the viewpoint of commonsense knowledge representation, relational learning, and qualitative reasoning about space and motion in cognitive robotics settings. We demonstrate key aspects of the space & motion ontology and its formalization as a representational framework in the backdrop of select examples from a dataset of everyday activities. Furthermore, focussing on human-object interaction data obtained from RGBD sensors, we also illustrate how declarative (spatio-temporal) reasoning in the (constraint) logic programming family may be performed with the developed deep semantic abstractions.
Commonsense Scene Semantics for Cognitive Robotics: Towards Grounding Embodied Visuo-Locomotive Interactions
Sep 15, 2017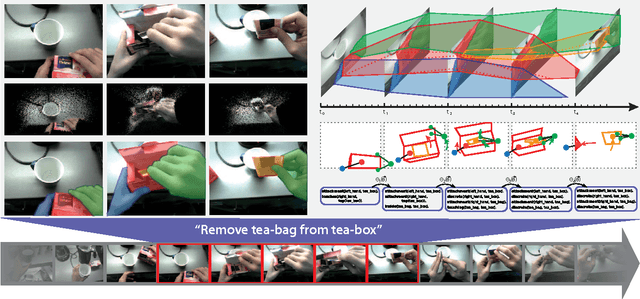



We present a commonsense, qualitative model for the semantic grounding of embodied visuo-spatial and locomotive interactions. The key contribution is an integrative methodology combining low-level visual processing with high-level, human-centred representations of space and motion rooted in artificial intelligence. We demonstrate practical applicability with examples involving object interactions, and indoor movement.