 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoronary Artery Segmentation from Intravascular Optical Coherence Tomography Using Deep Capsules
Mar 13, 2020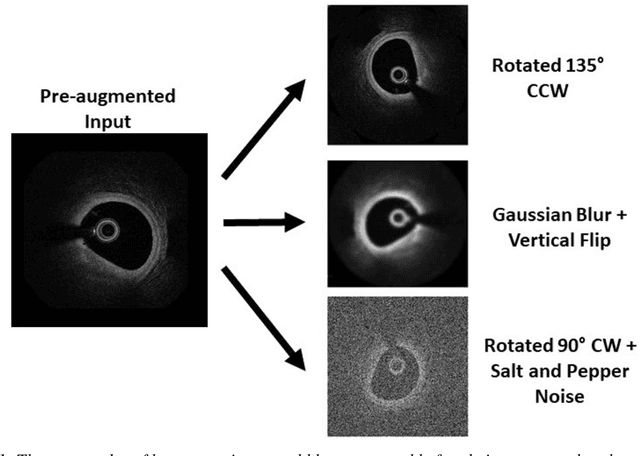

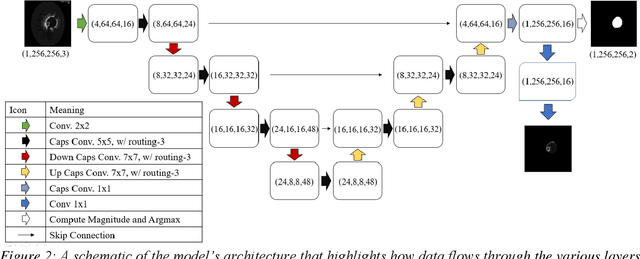
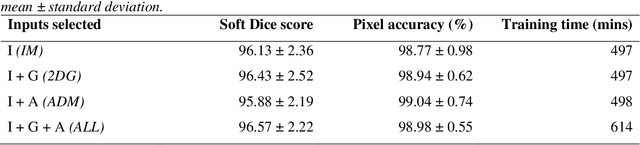
The segmentation and analysis of coronary arteries from intravascular optical coherence tomography (IVOCT) is an important aspect of diagnosing and managing coronary artery disease. However, automated, robust IVOCT image analysis tools are lacking. Current image processing methods are hindered by the time needed to generate these expert-labelled datasets and also the potential for bias during the analysis. Here we present a new deep learning method based on capsules to automatically produce lumen segmentations, built using a large IVOCT dataset of 12,011 images with ground-truth segmentations. This dataset contains images with both blood and light artefacts (22.8%), as well as noise from metallic (23.1%) and bioresorbable stents (2.5%). We trained our model on a dataset containing 9,608 images. We rigorously investigate design variations with respect to upsampling regimes and input selection and validate our deep learning model using 2,403 images. We show that our fully trained and optimized model achieves a mean Soft Dice Score of 97.11% (median of 98.2%), segments 200 IVOCT images in an acceptable timeframe of 12 seconds and outperforms current algorithms.
Answer Set Programming Modulo `Space-Time'
May 17, 2018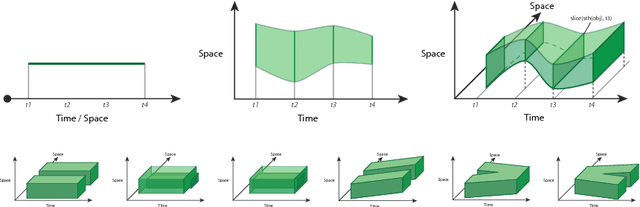

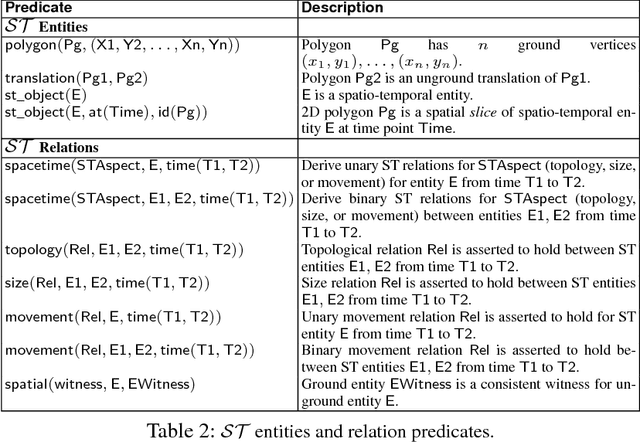
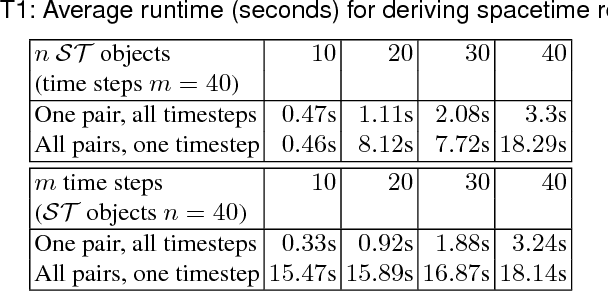
We present ASP Modulo `Space-Time', a declarative representational and computational framework to perform commonsense reasoning about regions with both spatial and temporal components. Supported are capabilities for mixed qualitative-quantitative reasoning, consistency checking, and inferring compositions of space-time relations; these capabilities combine and synergise for applications in a range of AI application areas where the processing and interpretation of spatio-temporal data is crucial. The framework and resulting system is the only general KR-based method for declaratively reasoning about the dynamics of `space-time' regions as first-class objects. We present an empirical evaluation (with scalability and robustness results), and include diverse application examples involving interpretation and control tasks.
Visual Explanation by High-Level Abduction: On Answer-Set Programming Driven Reasoning about Moving Objects
Dec 03, 2017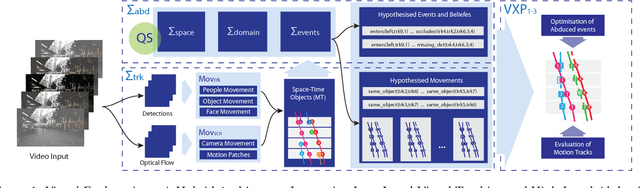
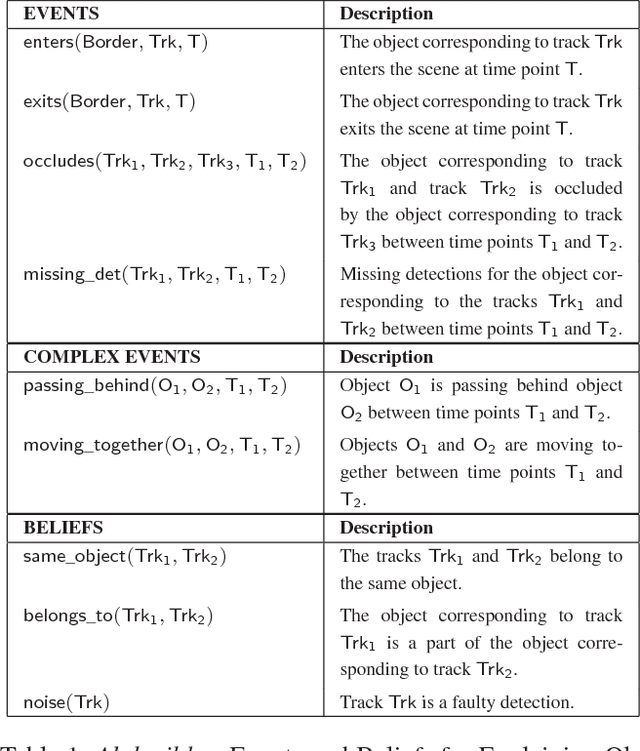


We propose a hybrid architecture for systematically computing robust visual explanation(s) encompassing hypothesis formation, belief revision, and default reasoning with video data. The architecture consists of two tightly integrated synergistic components: (1) (functional) answer set programming based abductive reasoning with space-time tracklets as native entities; and (2) a visual processing pipeline for detection based object tracking and motion analysis. We present the formal framework, its general implementation as a (declarative) method in answer set programming, and an example application and evaluation based on two diverse video datasets: the MOTChallenge benchmark developed by the vision community, and a recently developed Movie Dataset.
Deeply Semantic Inductive Spatio-Temporal Learning
Aug 09, 2016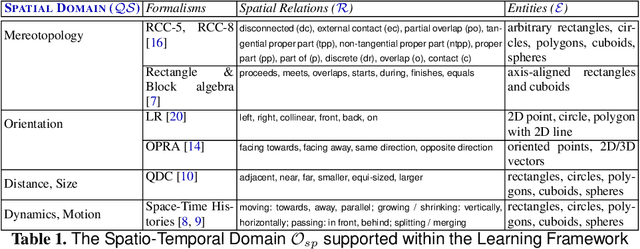
We present an inductive spatio-temporal learning framework rooted in inductive logic programming. With an emphasis on visuo-spatial language, logic, and cognition, the framework supports learning with relational spatio-temporal features identifiable in a range of domains involving the processing and interpretation of dynamic visuo-spatial imagery. We present a prototypical system, and an example application in the domain of computing for visual arts and computational cognitive science.
Non-Monotonic Spatial Reasoning with Answer Set Programming Modulo Theories
Jun 28, 2016
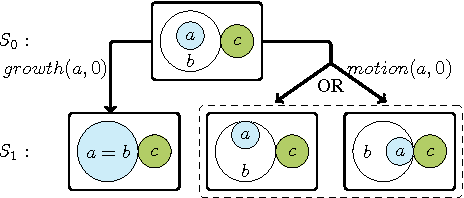
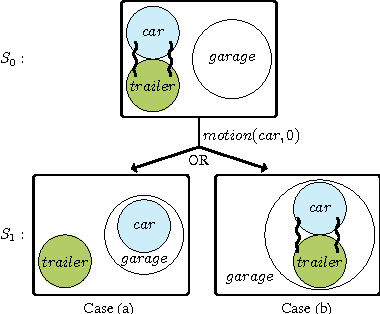
The systematic modelling of dynamic spatial systems is a key requirement in a wide range of application areas such as commonsense cognitive robotics, computer-aided architecture design, and dynamic geographic information systems. We present ASPMT(QS), a novel approach and fully-implemented prototype for non-monotonic spatial reasoning -a crucial requirement within dynamic spatial systems- based on Answer Set Programming Modulo Theories (ASPMT). ASPMT(QS) consists of a (qualitative) spatial representation module (QS) and a method for turning tight ASPMT instances into Satisfiability Modulo Theories (SMT) instances in order to compute stable models by means of SMT solvers. We formalise and implement concepts of default spatial reasoning and spatial frame axioms. Spatial reasoning is performed by encoding spatial relations as systems of polynomial constraints, and solving via SMT with the theory of real nonlinear arithmetic. We empirically evaluate ASPMT(QS) in comparison with other contemporary spatial reasoning systems both within and outside the context of logic programming. ASPMT(QS) is currently the only existing system that is capable of reasoning about indirect spatial effects (i.e., addressing the ramification problem), and integrating geometric and qualitative spatial information within a non-monotonic spatial reasoning context. This paper is under consideration for publication in TPLP.
Spatial Symmetry Driven Pruning Strategies for Efficient Declarative Spatial Reasoning
Jun 16, 2015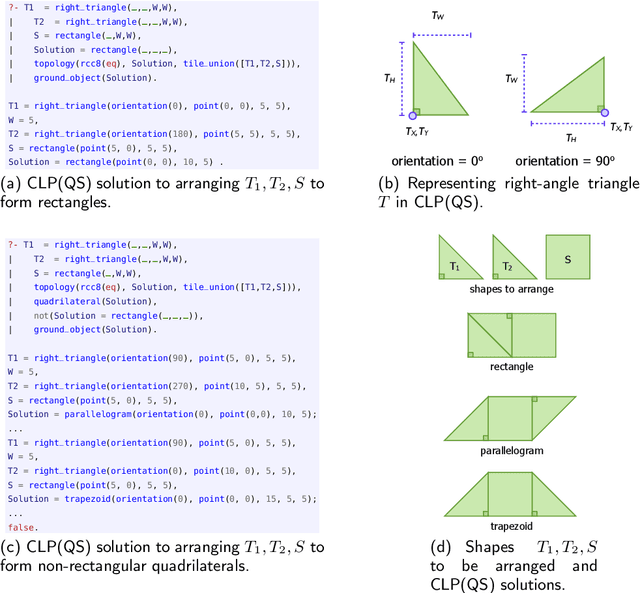
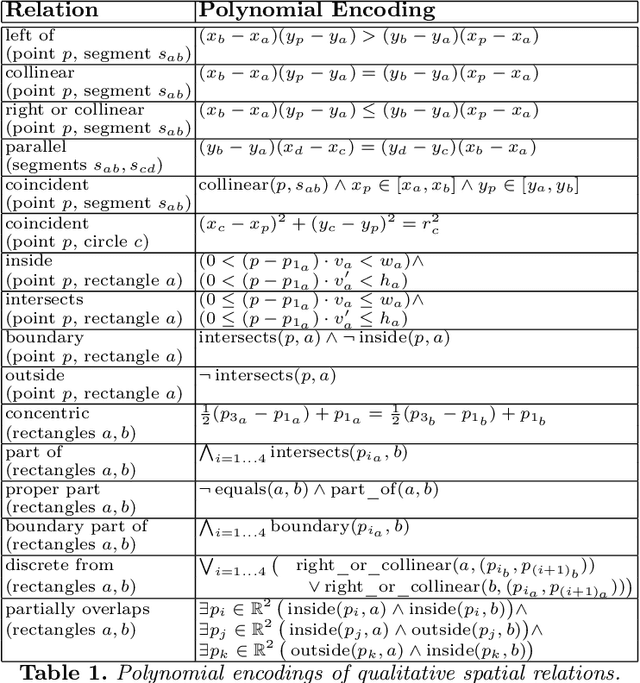


Declarative spatial reasoning denotes the ability to (declaratively) specify and solve real-world problems related to geometric and qualitative spatial representation and reasoning within standard knowledge representation and reasoning (KR) based methods (e.g., logic programming and derivatives). One approach for encoding the semantics of spatial relations within a declarative programming framework is by systems of polynomial constraints. However, solving such constraints is computationally intractable in general (i.e. the theory of real-closed fields). We present a new algorithm, implemented within the declarative spatial reasoning system CLP(QS), that drastically improves the performance of deciding the consistency of spatial constraint graphs over conventional polynomial encodings. We develop pruning strategies founded on spatial symmetries that form equivalence classes (based on affine transformations) at the qualitative spatial level. Moreover, pruning strategies are themselves formalised as knowledge about the properties of space and spatial symmetries. We evaluate our algorithm using a range of benchmarks in the class of contact problems, and proofs in mereology and geometry. The empirical results show that CLP(QS) with knowledge-based spatial pruning outperforms conventional polynomial encodings by orders of magnitude, and can thus be applied to problems that are otherwise unsolvable in practice.
ASPMT(QS): Non-Monotonic Spatial Reasoning with Answer Set Programming Modulo Theories
Jun 16, 2015The systematic modelling of \emph{dynamic spatial systems} [9] is a key requirement in a wide range of application areas such as comonsense cognitive robotics, computer-aided architecture design, dynamic geographic information systems. We present ASPMT(QS), a novel approach and fully-implemented prototype for non-monotonic spatial reasoning ---a crucial requirement within dynamic spatial systems-- based on Answer Set Programming Modulo Theories (ASPMT). ASPMT(QS) consists of a (qualitative) spatial representation module (QS) and a method for turning tight ASPMT instances into Sat Modulo Theories (SMT) instances in order to compute stable models by means of SMT solvers. We formalise and implement concepts of default spatial reasoning and spatial frame axioms using choice formulas. Spatial reasoning is performed by encoding spatial relations as systems of polynomial constraints, and solving via SMT with the theory of real nonlinear arithmetic. We empirically evaluate ASPMT(QS) in comparison with other prominent contemporary spatial reasoning systems. Our results show that ASPMT(QS) is the only existing system that is capable of reasoning about indirect spatial effects (i.e. addressing the ramification problem), and integrating geometric and qualitative spatial information within a non-monotonic spatial reasoning context.
Cognitive Interpretation of Everyday Activities: Toward Perceptual Narrative Based Visuo-Spatial Scene Interpretation
Jun 22, 2013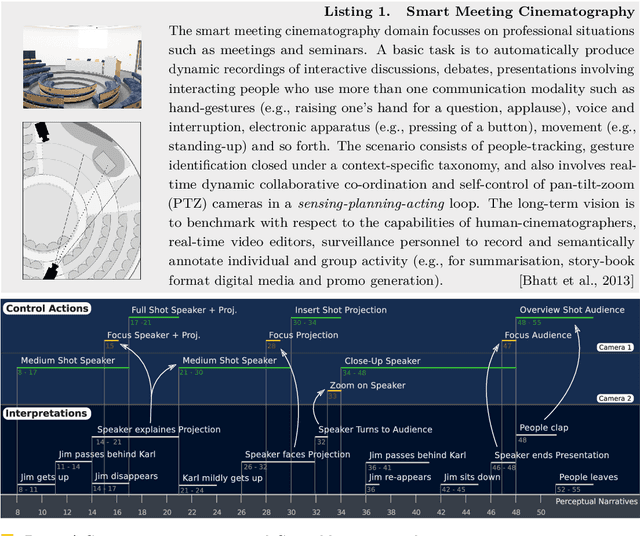
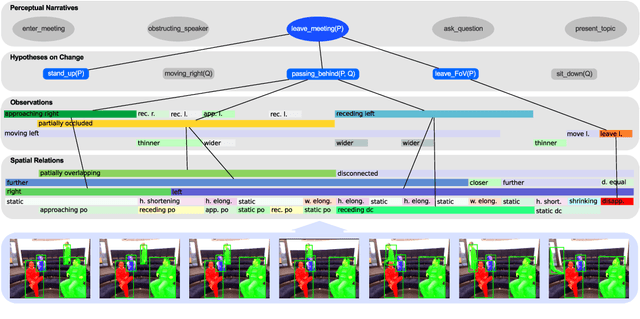
We position a narrative-centred computational model for high-level knowledge representation and reasoning in the context of a range of assistive technologies concerned with "visuo-spatial perception and cognition" tasks. Our proposed narrative model encompasses aspects such as \emph{space, events, actions, change, and interaction} from the viewpoint of commonsense reasoning and learning in large-scale cognitive systems. The broad focus of this paper is on the domain of "human-activity interpretation" in smart environments, ambient intelligence etc. In the backdrop of a "smart meeting cinematography" domain, we position the proposed narrative model, preliminary work on perceptual narrativisation, and the immediate outlook on constructing general-purpose open-source tools for perceptual narrativisation. ACM Classification: I.2 Artificial Intelligence: I.2.0 General -- Cognitive Simulation, I.2.4 Knowledge Representation Formalisms and Methods, I.2.10 Vision and Scene Understanding: Architecture and control structures, Motion, Perceptual reasoning, Shape, Video analysis General keywords: cognitive systems; human-computer interaction; spatial cognition and computation; commonsense reasoning; spatial and temporal reasoning; assistive technologies