 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCO-SNE: Dimensionality Reduction and Visualization for Hyperbolic Data
Nov 30, 2021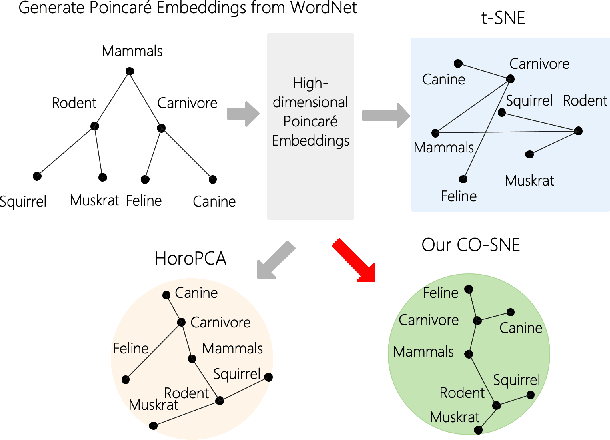

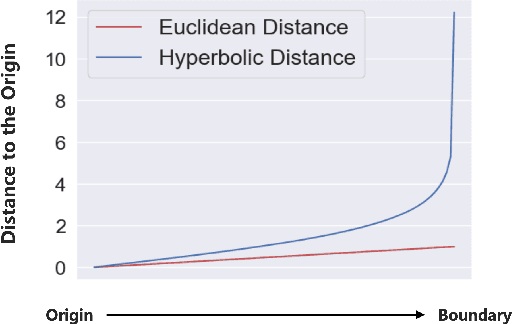
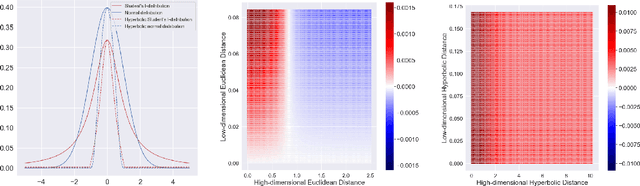
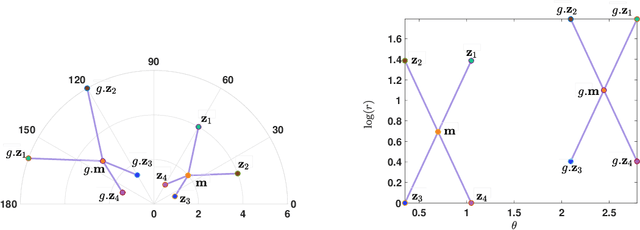
Hyperbolic space can embed tree metric with little distortion, a desirable property for modeling hierarchical structures of real-world data and semantics. While high-dimensional embeddings often lead to better representations, most hyperbolic models utilize low-dimensional embeddings, due to non-trivial optimization as well as the lack of a visualization for high-dimensional hyperbolic data. We propose CO-SNE, extending the Euclidean space visualization tool, t-SNE, to hyperbolic space. Like t-SNE, it converts distances between data points to joint probabilities and tries to minimize the Kullback-Leibler divergence between the joint probabilities of high-dimensional data $X$ and low-dimensional embeddings $Y$. However, unlike Euclidean space, hyperbolic space is inhomogeneous: a volume could contain a lot more points at a location far from the origin. CO-SNE thus uses hyperbolic normal distributions for $X$ and hyberbolic \underline{C}auchy instead of t-SNE's Student's t-distribution for $Y$, and it additionally attempts to preserve $X$'s individual distances to the \underline{O}rigin in $Y$. We apply CO-SNE to high-dimensional hyperbolic biological data as well as unsupervisedly learned hyperbolic representations. Our results demonstrate that CO-SNE deflates high-dimensional hyperbolic data into a low-dimensional space without losing their hyperbolic characteristics, significantly outperforming popular visualization tools such as PCA, t-SNE, UMAP, and HoroPCA, the last of which is specifically designed for hyperbolic data.
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021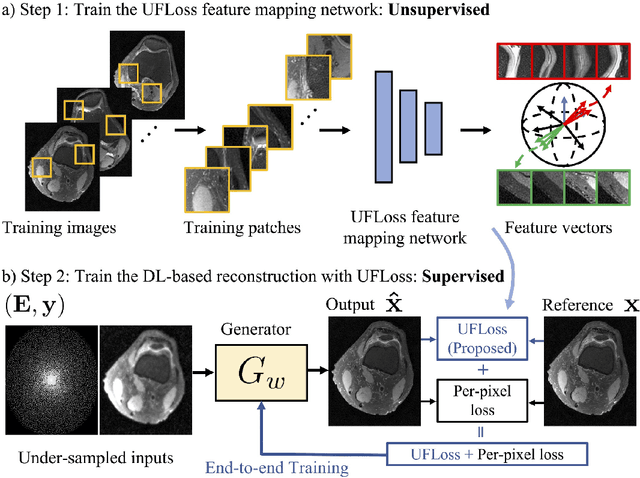
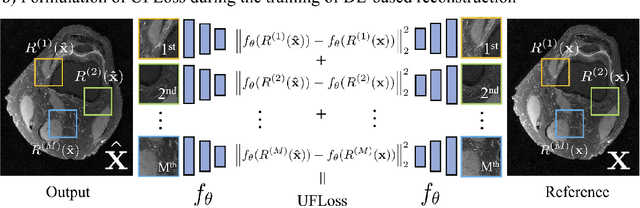
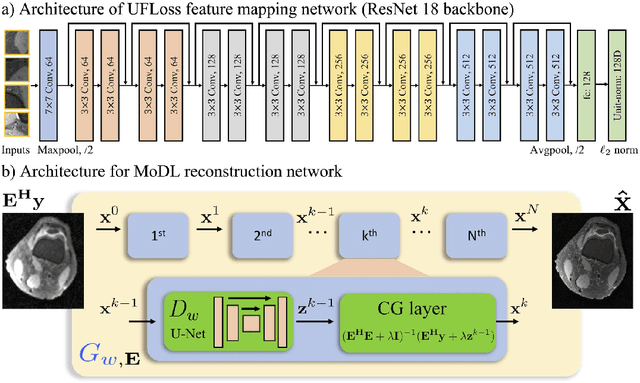
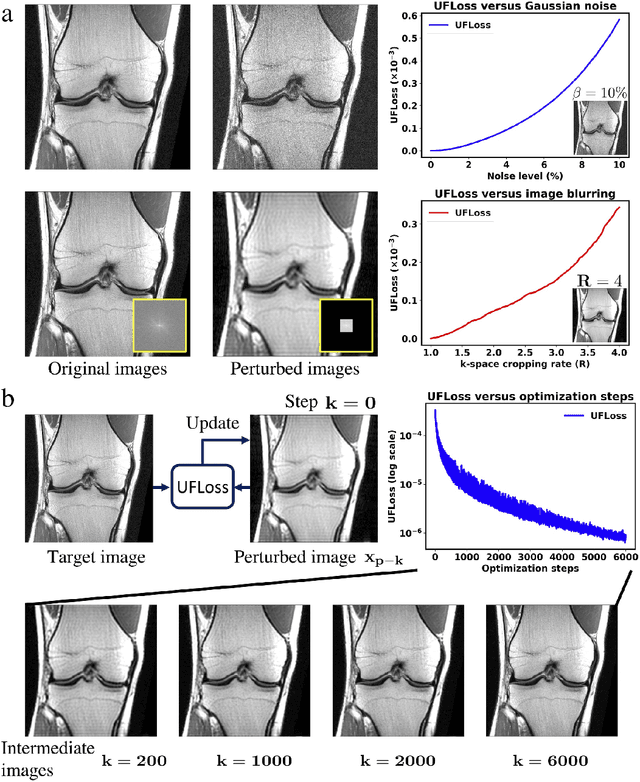
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.
Unsupervised deep learning for grading of age-related macular degeneration using retinal fundus images
Oct 22, 2020Many diseases are classified based on human-defined rubrics that are prone to bias. Supervised neural networks can automate the grading of retinal fundus images, but require labor-intensive annotations and are restricted to the specific trained task. Here, we employed an unsupervised network with Non-Parametric Instance Discrimination (NPID) to grade age-related macular degeneration (AMD) severity using fundus photographs from the Age-Related Eye Disease Study (AREDS). Our unsupervised algorithm demonstrated versatility across different AMD classification schemes without retraining, and achieved unbalanced accuracies comparable to supervised networks and human ophthalmologists in classifying advanced or referable AMD, or on the 4-step AMD severity scale. Exploring the networks behavior revealed disease-related fundus features that drove predictions and unveiled the susceptibility of more granular human-defined AMD severity schemes to misclassification by both ophthalmologists and neural networks. Importantly, unsupervised learning enabled unbiased, data-driven discovery of AMD features such as geographic atrophy, as well as other ocular phenotypes of the choroid, vitreous, and lens, such as visually-impairing cataracts, that were not pre-defined by human labels.
C-SURE: Shrinkage Estimator and Prototype Classifier for Complex-Valued Deep Learning
Jun 22, 2020


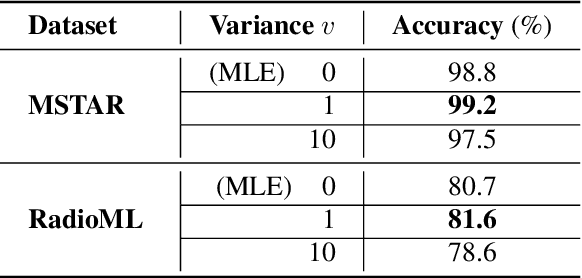
The James-Stein (JS) shrinkage estimator is a biased estimator that captures the mean of Gaussian random vectors.While it has a desirable statistical property of dominance over the maximum likelihood estimator (MLE) in terms of mean squared error (MSE), not much progress has been made on extending the estimator onto manifold-valued data. We propose C-SURE, a novel Stein's unbiased risk estimate (SURE) of the JS estimator on the manifold of complex-valued data with a theoretically proven optimum over MLE. Adapting the architecture of the complex-valued SurReal classifier, we further incorporate C-SURE into a prototype convolutional neural network (CNN) classifier. We compare C-SURE with SurReal and a real-valued baseline on complex-valued MSTAR and RadioML datasets. C-SURE is more accurate and robust than SurReal, and the shrinkage estimator is always better than MLE for the same prototype classifier. Like SurReal, C-SURE is much smaller, outperforming the real-valued baseline on MSTAR (RadioML) with less than 1 percent (3 percent) of the baseline size
BatVision with GCC-PHAT Features for Better Sound to Vision Predictions
Jun 14, 2020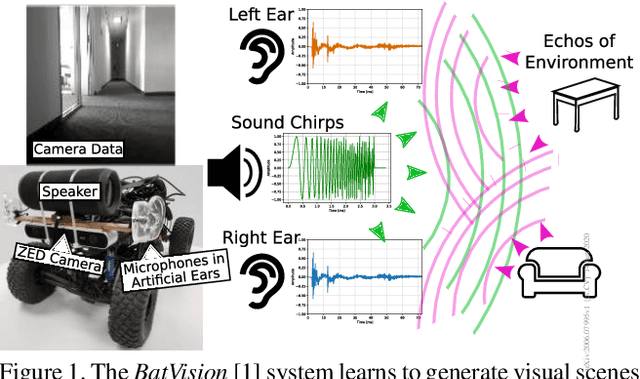
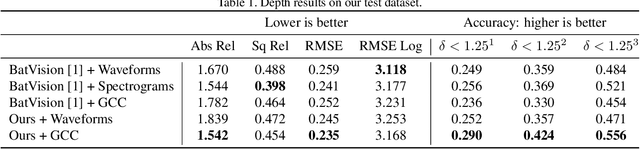


Inspired by sophisticated echolocation abilities found in nature, we train a generative adversarial network to predict plausible depth maps and grayscale layouts from sound. To achieve this, our sound-to-vision model processes binaural echo-returns from chirping sounds. We build upon previous work with BatVision that consists of a sound-to-vision model and a self-collected dataset using our mobile robot and low-cost hardware. We improve on the previous model by introducing several changes to the model, which leads to a better depth and grayscale estimation, and increased perceptual quality. Rather than using raw binaural waveforms as input, we generate generalized cross-correlation (GCC) features and use these as input instead. In addition, we change the model generator and base it on residual learning and use spectral normalization in the discriminator. We compare and present both quantitative and qualitative improvements over our previous BatVision model.
BatVision: Learning to See 3D Spatial Layout with Two Ears
Dec 15, 2019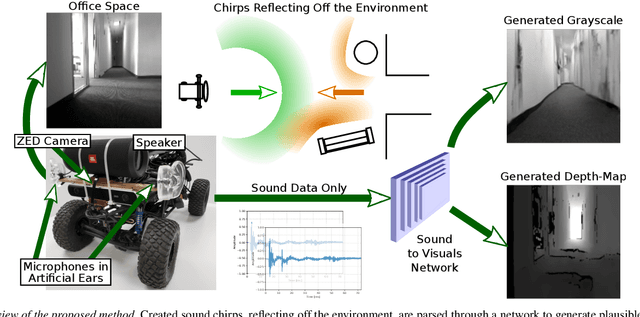
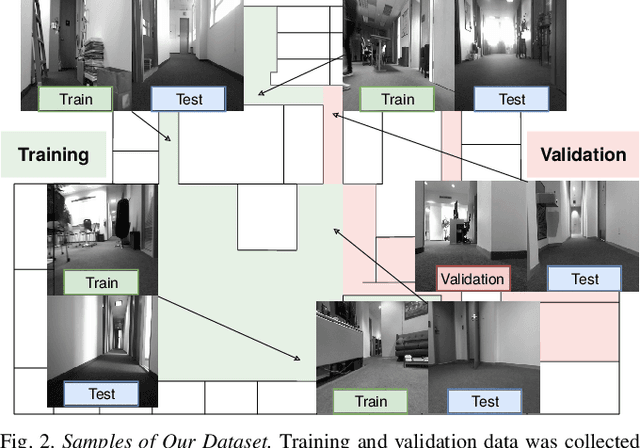
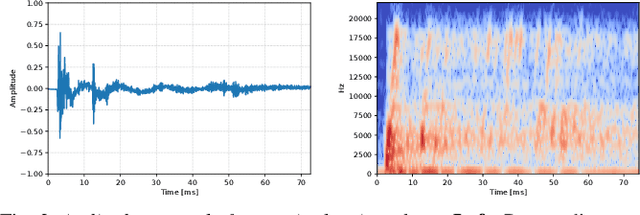
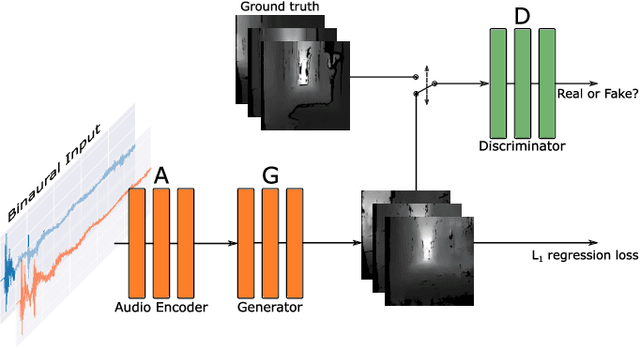
Virtual camera images showing the correct layout of a space ahead can be generated by purely listening to the reflections of chirping sounds. Many species evolved sophisticated non-visual perception while artificial systems fall behind. Radar and ultrasound are used where cameras fail, but provide very limited information or require large, complex and expensive sensors. Yet sound is used effortlessly by dolphins, bats, wales and humans as a sensor modality with many advantages over vision. However, it is challenging to harness useful and detailed information for machine perception. We train a network to generate representations of the world in 2D and 3D only from sounds, sent by one speaker and captured by two microphones. Inspired by examples from nature, we emit short frequency modulated sound chirps and record returning echoes through an artificial human pinnae pair. We then learn to generate disparity-like depth maps and grayscale images from the echoes in an end-to-end fashion. With only low-cost equipment, our models show good reconstruction performance while being robust to errors and even overcoming limitations of our vision-based ground truth. Finally, we introduce a large dataset consisting of binaural sound signals synchronised in time with both RGB images and depth maps.
Surreal: Complex-Valued Deep Learning as Principled Transformations on a Rotational Lie Group
Oct 18, 2019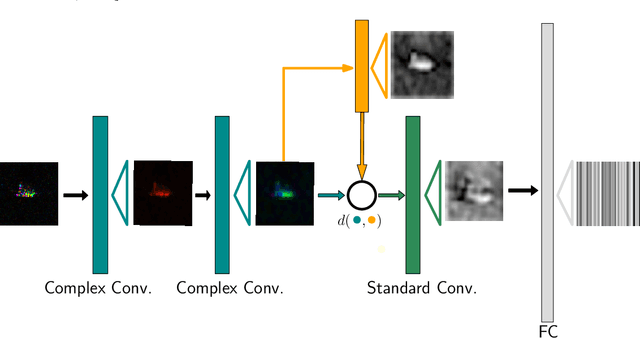
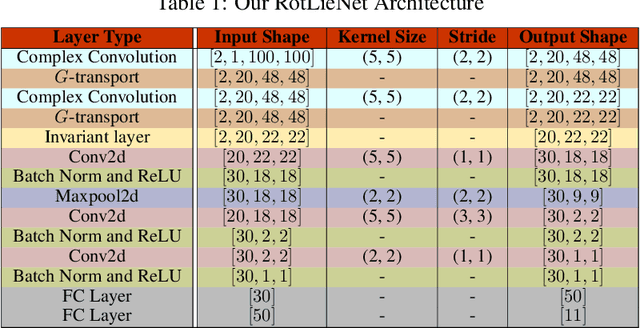
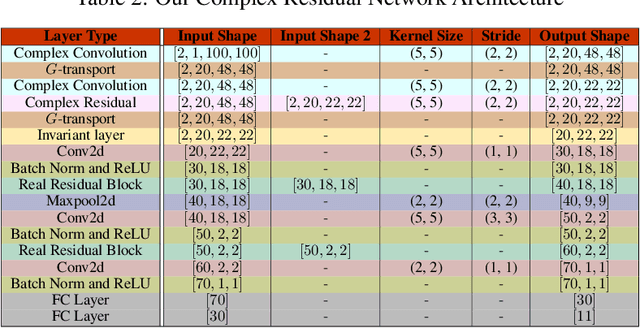
Complex-valued deep learning has attracted increasing attention in recent years, due to its versatility and ability to capture more information. However, the lack of well-defined complex-valued operations remains a bottleneck for further advancement. In this work, we propose a geometric way to define deep neural networks on the space of complex numbers by utilizing weighted Fr\'echet mean. We mathematically prove the viability of our algorithm. We also define basic building blocks such as convolution, non-linearity, and residual connections tailored for the space of complex numbers. To demonstrate the effectiveness of our proposed model, we compare our complex-valued network comprehensively with its real state-of-the-art counterpart on the MSTAR classification task and achieve better performance, while utilizing less than 1% of the parameters.
An Unpaired Sketch-to-Photo Translation Model
Sep 20, 2019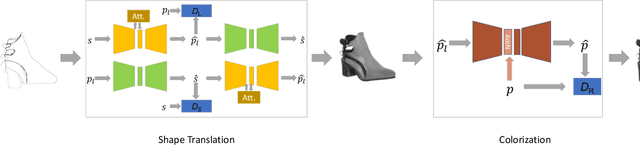
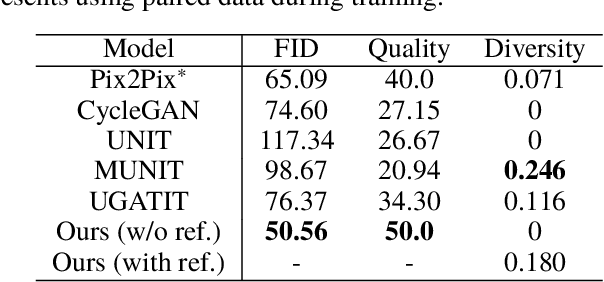
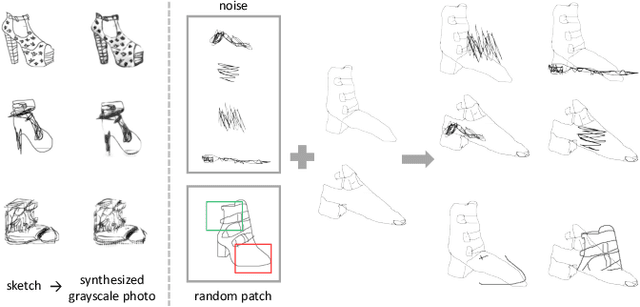

Sketch-based image synthesis aims to generate a photo image given a sketch. It is a challenging task; because sketches are drawn by non-professionals and only consist of strokes, they usually exhibit shape deformation and lack visual cues, i.e., colors and textures. Thus translation from sketch to photo involves two aspects: shape and color (texture). Existing methods cannot handle this task well, as they mostly focus on solving one translation. In this work, we show that the key to this task lies in decomposing the translation into two sub-tasks, shape translation and colorization. Correspondingly, we propose a model consisting of two sub-networks, with each one tackling one sub-task. We also find that, when translating shapes, specific drawing styles affect the generated results significantly and may even lead to failure. To make our model more robust to drawing style variations, we design a data augmentation strategy and re-purpose an attention module, aiming to make our model pay less attention to distracted regions of a sketch. Besides, a conditional module is adapted for color translation to improve diversity and increase users' control over the generated results. Both quantitative and qualitative comparisons are presented to show the superiority of our approach. In addition, as a side benefit, our model can synthesize high-quality sketches from photos inversely. We also demonstrate how these generated photos and sketches can benefit other applications, such as sketch-based image retrieval.
Semantic Analysis of Visual Symmetry: A Human-Centred Computational Model for Declarative Explainability
Sep 14, 2018
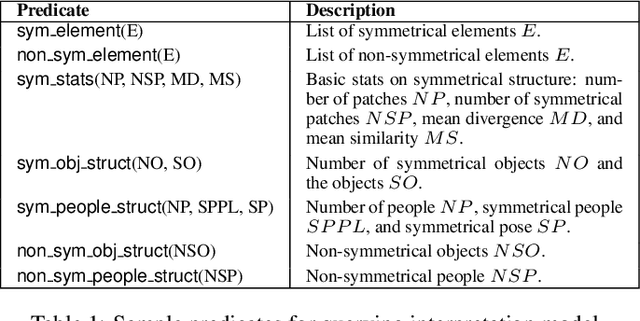

We present a computational model for the semantic interpretation of symmetry in naturalistic scenes. Key features include a human-centred representation, and a declarative, explainable interpretation model supporting deep semantic question-answering founded on an integration of methods in knowledge representation and deep learning based computer vision. In the backdrop of the visual arts, we showcase the framework's capability to generate human-centred, queryable, relational structures, also evaluating the framework with an empirical study on the human perception of visual symmetry. Our framework represents and is driven by the application of foundational, integrated Vision and Knowledge Representation and Reasoning methods for applications in the arts, and the psychological and social sciences.
* Preprint of accepted article / Journal: Advances in Cognitive Systems. ( http://www.cogsys.org/journal )
Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination
May 05, 2018
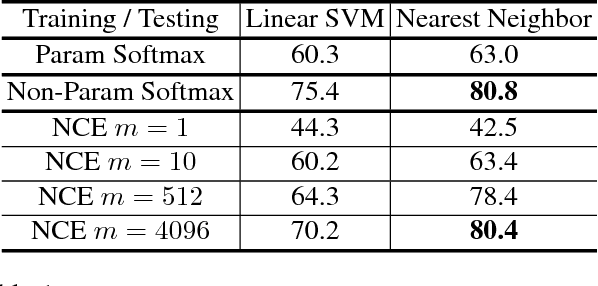

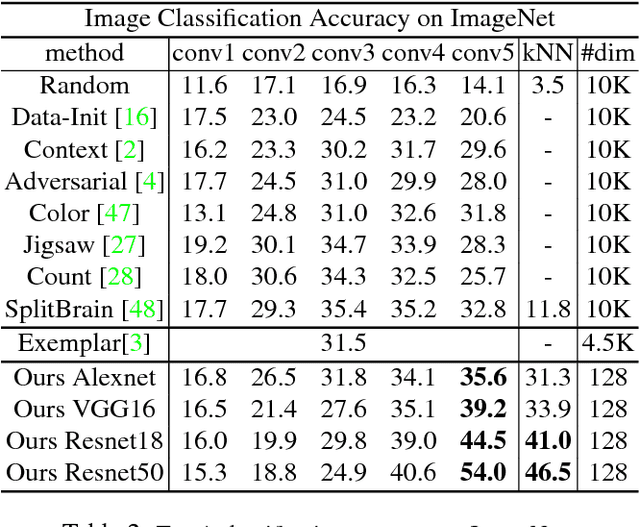
Neural net classifiers trained on data with annotated class labels can also capture apparent visual similarity among categories without being directed to do so. We study whether this observation can be extended beyond the conventional domain of supervised learning: Can we learn a good feature representation that captures apparent similarity among instances, instead of classes, by merely asking the feature to be discriminative of individual instances? We formulate this intuition as a non-parametric classification problem at the instance-level, and use noise-contrastive estimation to tackle the computational challenges imposed by the large number of instance classes. Our experimental results demonstrate that, under unsupervised learning settings, our method surpasses the state-of-the-art on ImageNet classification by a large margin. Our method is also remarkable for consistently improving test performance with more training data and better network architectures. By fine-tuning the learned feature, we further obtain competitive results for semi-supervised learning and object detection tasks. Our non-parametric model is highly compact: With 128 features per image, our method requires only 600MB storage for a million images, enabling fast nearest neighbour retrieval at the run time.