 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Free Image Quality Metric for Degradation and Reconstruction Artifacts
May 01, 2024



Image Quality Assessment (IQA) is essential in various Computer Vision tasks such as image deblurring and super-resolution. However, most IQA methods require reference images, which are not always available. While there are some reference-free IQA metrics, they have limitations in simulating human perception and discerning subtle image quality variations. We hypothesize that the JPEG quality factor is representatives of image quality measurement, and a well-trained neural network can learn to accurately evaluate image quality without requiring a clean reference, as it can recognize image degradation artifacts based on prior knowledge. Thus, we developed a reference-free quality evaluation network, dubbed "Quality Factor (QF) Predictor", which does not require any reference. Our QF Predictor is a lightweight, fully convolutional network comprising seven layers. The model is trained in a self-supervised manner: it receives JPEG compressed image patch with a random QF as input, is trained to accurately predict the corresponding QF. We demonstrate the versatility of the model by applying it to various tasks. First, our QF Predictor can generalize to measure the severity of various image artifacts, such as Gaussian Blur and Gaussian noise. Second, we show that the QF Predictor can be trained to predict the undersampling rate of images reconstructed from Magnetic Resonance Imaging (MRI) data.
K-band: Self-supervised MRI Reconstruction via Stochastic Gradient Descent over K-space Subsets
Aug 05, 2023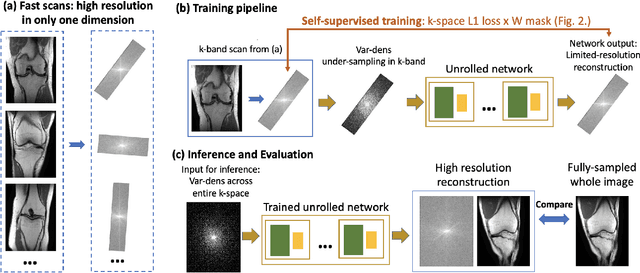
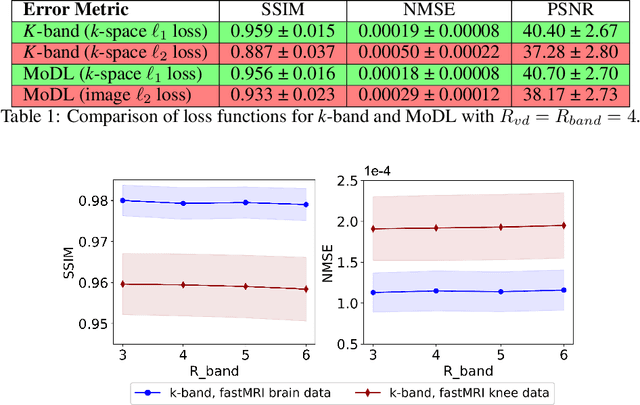
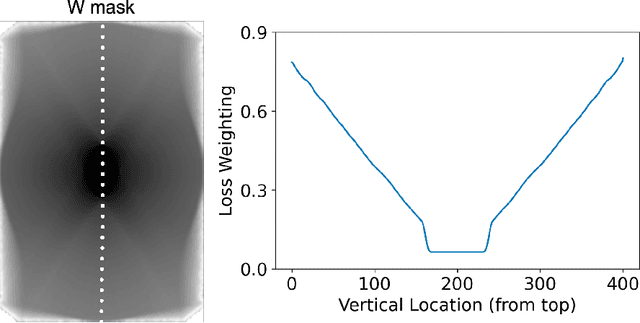

Although deep learning (DL) methods are powerful for solving inverse problems, their reliance on high-quality training data is a major hurdle. This is significant in high-dimensional (dynamic/volumetric) magnetic resonance imaging (MRI), where acquisition of high-resolution fully sampled k-space data is impractical. We introduce a novel mathematical framework, dubbed k-band, that enables training DL models using only partial, limited-resolution k-space data. Specifically, we introduce training with stochastic gradient descent (SGD) over k-space subsets. In each training iteration, rather than using the fully sampled k-space for computing gradients, we use only a small k-space portion. This concept is compatible with different sampling strategies; here we demonstrate the method for k-space "bands", which have limited resolution in one dimension and can hence be acquired rapidly. We prove analytically that our method stochastically approximates the gradients computed in a fully-supervised setup, when two simple conditions are met: (i) the limited-resolution axis is chosen randomly-uniformly for every new scan, hence k-space is fully covered across the entire training set, and (ii) the loss function is weighed with a mask, derived here analytically, which facilitates accurate reconstruction of high-resolution details. Numerical experiments with raw MRI data indicate that k-band outperforms two other methods trained on limited-resolution data and performs comparably to state-of-the-art (SoTA) methods trained on high-resolution data. k-band hence obtains SoTA performance, with the advantage of training using only limited-resolution data. This work hence introduces a practical, easy-to-implement, self-supervised training framework, which involves fast acquisition and self-supervised reconstruction and offers theoretical guarantees.
Beat Pilot Tone: Versatile, Contact-Free Motion Sensing in MRI with Radio Frequency Intermodulation
Jun 17, 2023Motion in Magnetic Resonance Imaging (MRI) scans results in image corruption and remains a barrier to clinical imaging. Motion correction algorithms require accurate sensing, but existing sensors are limited in sensitivity, comfort, or general usability. We propose Beat Pilot Tone (BPT), a radio frequency (RF) motion sensing system that is sensitive, comfortable, versatile, and scalable. BPT operates by a novel mechanism: two or more transmitted RF tones form standing wave patterns that are modulated by motion and sensed by the same receiver coil arrays used for MR imaging. By serendipity, the tones are mixed through nonlinear intermodulation in the receiver chain and digitized simultaneously with the MRI data. We demonstrate BPT's mechanism in simulations and experiments. Furthermore, we show in healthy volunteers that BPT can sense head, bulk, respiratory, and cardiac motion, including small vibrations such as displacement ballistocardiograms. BPT can distinguish between different motion types, achieve greater sensitivity than other methods, and operate as a multiple-input multiple-output (MIMO) system. Thus, BPT can enable motion-robust MRI scans at high spatiotemporal resolution in many applications.
High-fidelity Direct Contrast Synthesis from Magnetic Resonance Fingerprinting
Dec 21, 2022Magnetic Resonance Fingerprinting (MRF) is an efficient quantitative MRI technique that can extract important tissue and system parameters such as T1, T2, B0, and B1 from a single scan. This property also makes it attractive for retrospectively synthesizing contrast-weighted images. In general, contrast-weighted images like T1-weighted, T2-weighted, etc., can be synthesized directly from parameter maps through spin-dynamics simulation (i.e., Bloch or Extended Phase Graph models). However, these approaches often exhibit artifacts due to imperfections in the mapping, the sequence modeling, and the data acquisition. Here we propose a supervised learning-based method that directly synthesizes contrast-weighted images from the MRF data without going through the quantitative mapping and spin-dynamics simulation. To implement our direct contrast synthesis (DCS) method, we deploy a conditional Generative Adversarial Network (GAN) framework and propose a multi-branch U-Net as the generator. The input MRF data are used to directly synthesize T1-weighted, T2-weighted, and fluid-attenuated inversion recovery (FLAIR) images through supervised training on paired MRF and target spin echo-based contrast-weighted scans. In-vivo experiments demonstrate excellent image quality compared to simulation-based contrast synthesis and previous DCS methods, both visually as well as by quantitative metrics. We also demonstrate cases where our trained model is able to mitigate in-flow and spiral off-resonance artifacts that are typically seen in MRF reconstructions and thus more faithfully represent conventional spin echo-based contrast-weighted images.
Subtle Inverse Crimes: Naïvely training machine learning algorithms could lead to overly-optimistic results
Sep 24, 2021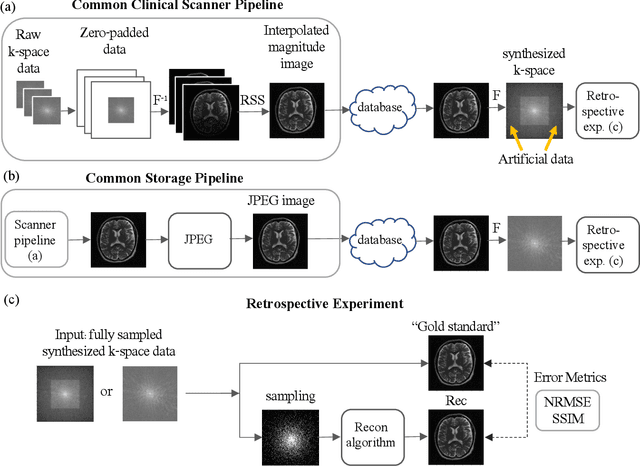
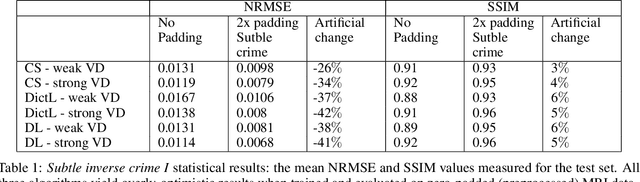
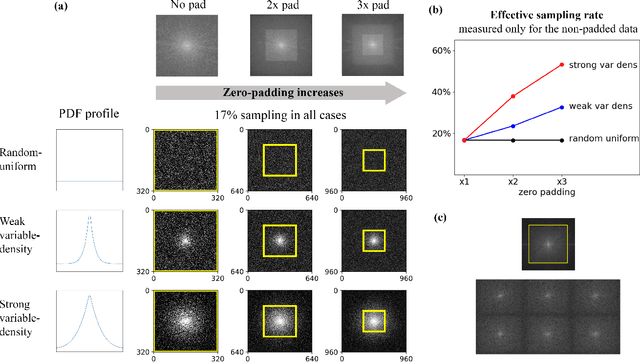
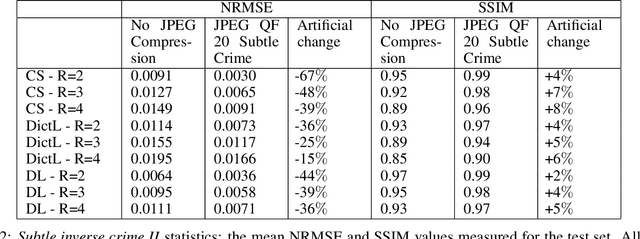
While open databases are an important resource in the Deep Learning (DL) era, they are sometimes used "off-label": data published for one task are used for training algorithms for a different one. This work aims to highlight that in some cases, this common practice may lead to biased, overly-optimistic results. We demonstrate this phenomenon for inverse problem solvers and show how their biased performance stems from hidden data preprocessing pipelines. We describe two preprocessing pipelines typical of open-access databases and study their effects on three well-established algorithms developed for Magnetic Resonance Imaging (MRI) reconstruction: Compressed Sensing (CS), Dictionary Learning (DictL), and DL. In this large-scale study we performed extensive computations. Our results demonstrate that the CS, DictL and DL algorithms yield systematically biased results when na\"ively trained on seemingly-appropriate data: the Normalized Root Mean Square Error (NRMSE) improves consistently with the preprocessing extent, showing an artificial increase of 25%-48% in some cases. Since this phenomenon is generally unknown, biased results are sometimes published as state-of-the-art; we refer to that as subtle inverse crimes. This work hence raises a red flag regarding na\"ive off-label usage of Big Data and reveals the vulnerability of modern inverse problem solvers to the resulting bias.
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021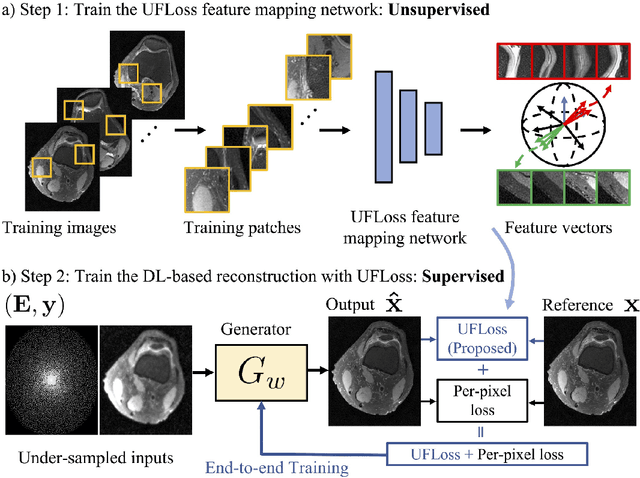
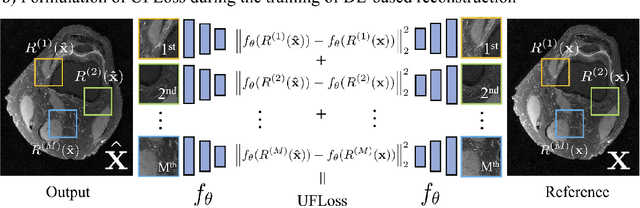
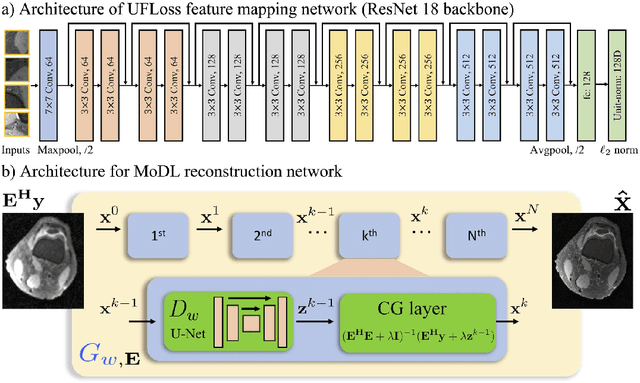
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.
Memory-efficient Learning for High-Dimensional MRI Reconstruction
Mar 06, 2021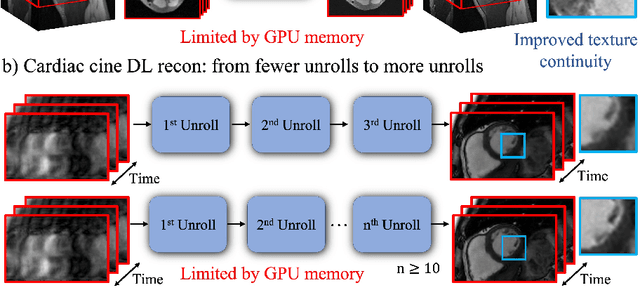



Deep learning (DL) based unrolled reconstructions have shown state-of-the-art performance for under-sampled magnetic resonance imaging (MRI). Similar to compressed sensing, DL can leverage high-dimensional data (e.g. 3D, 2D+time, 3D+time) to further improve performance. However, network size and depth are currently limited by the GPU memory required for backpropagation. Here we use a memory-efficient learning (MEL) framework which favorably trades off storage with a manageable increase in computation during training. Using MEL with multi-dimensional data, we demonstrate improved image reconstruction performance for in-vivo 3D MRI and 2D+time cardiac cine MRI. MEL uses far less GPU memory while marginally increasing the training time, which enables new applications of DL to high-dimensional MRI.
How to do Physics-based Learning
May 28, 2020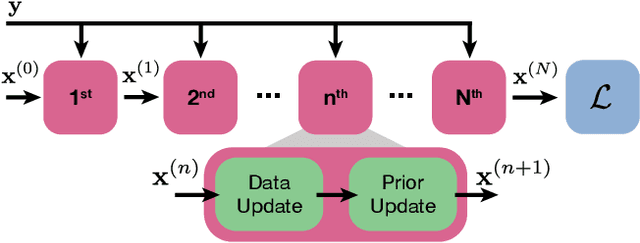

The goal of this tutorial is to explain step-by-step how to implement physics-based learning for the rapid prototyping of a computational imaging system. We provide a basic overview of physics-based learning, the construction of a physics-based network, and its reduction to practice. Specifically, we advocate exploiting the auto-differentiation functionality twice, once to build a physics-based network and again to perform physics-based learning. Thus, the user need only implement the forward model process for their system, speeding up prototyping time. We provide an open-source Pytorch implementation of a physics-based network and training procedure for a generic sparse recovery problem
Memory-efficient Learning for Large-scale Computational Imaging
Mar 11, 2020
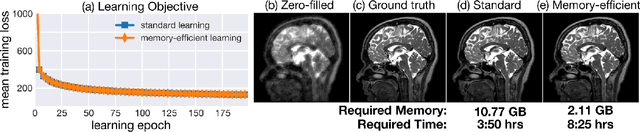
Critical aspects of computational imaging systems, such as experimental design and image priors, can be optimized through deep networks formed by the unrolled iterations of classical model-based reconstructions (termed physics-based networks). However, for real-world large-scale inverse problems, computing gradients via backpropagation is infeasible due to memory limitations of graphics processing units. In this work, we propose a memory-efficient learning procedure that exploits the reversibility of the network's layers to enable data-driven design for large-scale computational imaging systems. We demonstrate our method on a small-scale compressed sensing example, as well as two large-scale real-world systems: multi-channel magnetic resonance imaging and super-resolution optical microscopy.