 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Free Image Quality Metric for Degradation and Reconstruction Artifacts
May 01, 2024



Image Quality Assessment (IQA) is essential in various Computer Vision tasks such as image deblurring and super-resolution. However, most IQA methods require reference images, which are not always available. While there are some reference-free IQA metrics, they have limitations in simulating human perception and discerning subtle image quality variations. We hypothesize that the JPEG quality factor is representatives of image quality measurement, and a well-trained neural network can learn to accurately evaluate image quality without requiring a clean reference, as it can recognize image degradation artifacts based on prior knowledge. Thus, we developed a reference-free quality evaluation network, dubbed "Quality Factor (QF) Predictor", which does not require any reference. Our QF Predictor is a lightweight, fully convolutional network comprising seven layers. The model is trained in a self-supervised manner: it receives JPEG compressed image patch with a random QF as input, is trained to accurately predict the corresponding QF. We demonstrate the versatility of the model by applying it to various tasks. First, our QF Predictor can generalize to measure the severity of various image artifacts, such as Gaussian Blur and Gaussian noise. Second, we show that the QF Predictor can be trained to predict the undersampling rate of images reconstructed from Magnetic Resonance Imaging (MRI) data.
K-band: Self-supervised MRI Reconstruction via Stochastic Gradient Descent over K-space Subsets
Aug 05, 2023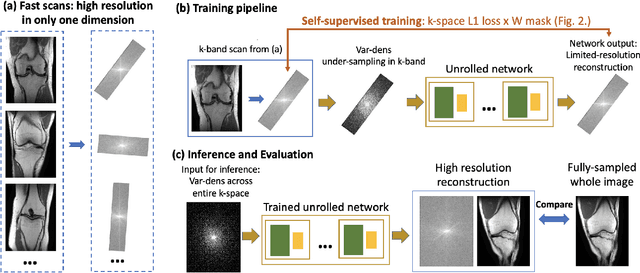
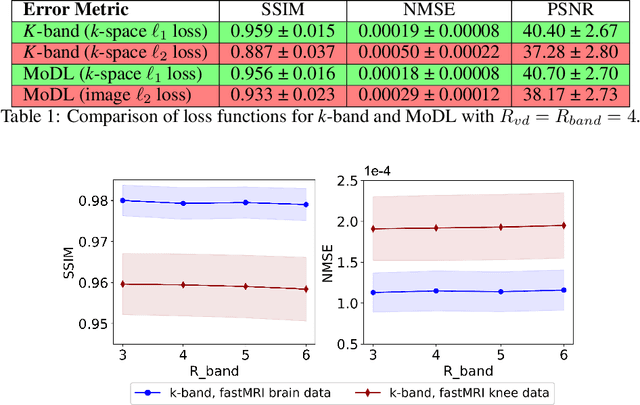
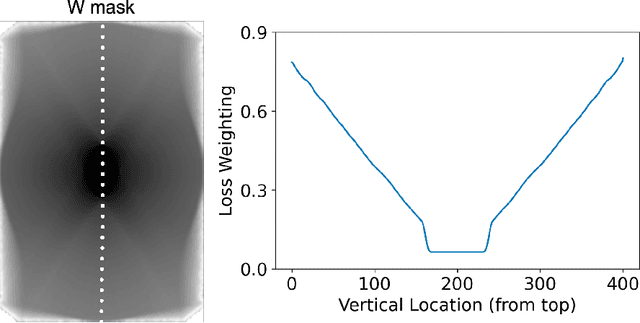

Although deep learning (DL) methods are powerful for solving inverse problems, their reliance on high-quality training data is a major hurdle. This is significant in high-dimensional (dynamic/volumetric) magnetic resonance imaging (MRI), where acquisition of high-resolution fully sampled k-space data is impractical. We introduce a novel mathematical framework, dubbed k-band, that enables training DL models using only partial, limited-resolution k-space data. Specifically, we introduce training with stochastic gradient descent (SGD) over k-space subsets. In each training iteration, rather than using the fully sampled k-space for computing gradients, we use only a small k-space portion. This concept is compatible with different sampling strategies; here we demonstrate the method for k-space "bands", which have limited resolution in one dimension and can hence be acquired rapidly. We prove analytically that our method stochastically approximates the gradients computed in a fully-supervised setup, when two simple conditions are met: (i) the limited-resolution axis is chosen randomly-uniformly for every new scan, hence k-space is fully covered across the entire training set, and (ii) the loss function is weighed with a mask, derived here analytically, which facilitates accurate reconstruction of high-resolution details. Numerical experiments with raw MRI data indicate that k-band outperforms two other methods trained on limited-resolution data and performs comparably to state-of-the-art (SoTA) methods trained on high-resolution data. k-band hence obtains SoTA performance, with the advantage of training using only limited-resolution data. This work hence introduces a practical, easy-to-implement, self-supervised training framework, which involves fast acquisition and self-supervised reconstruction and offers theoretical guarantees.
High Fidelity Deep Learning-based MRI Reconstruction with Instance-wise Discriminative Feature Matching Loss
Aug 27, 2021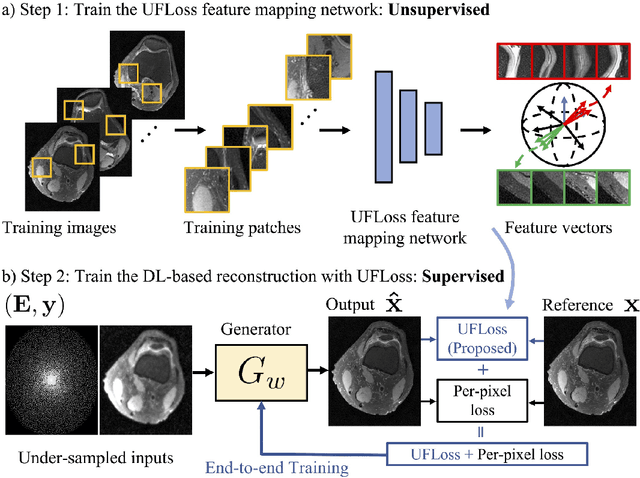
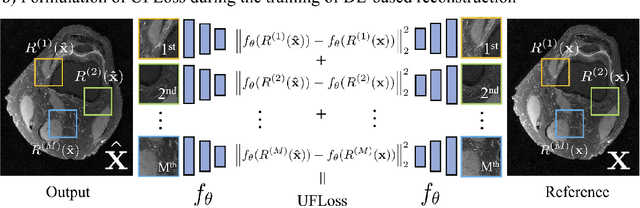
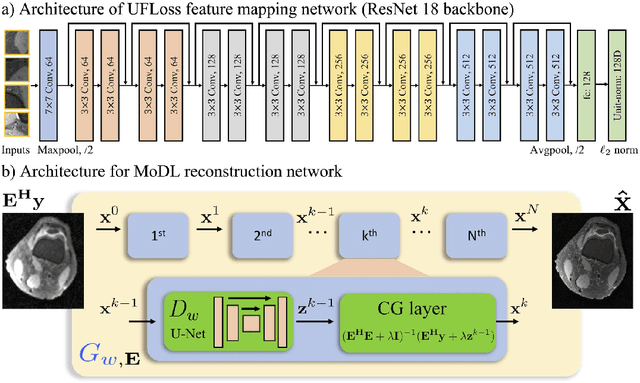
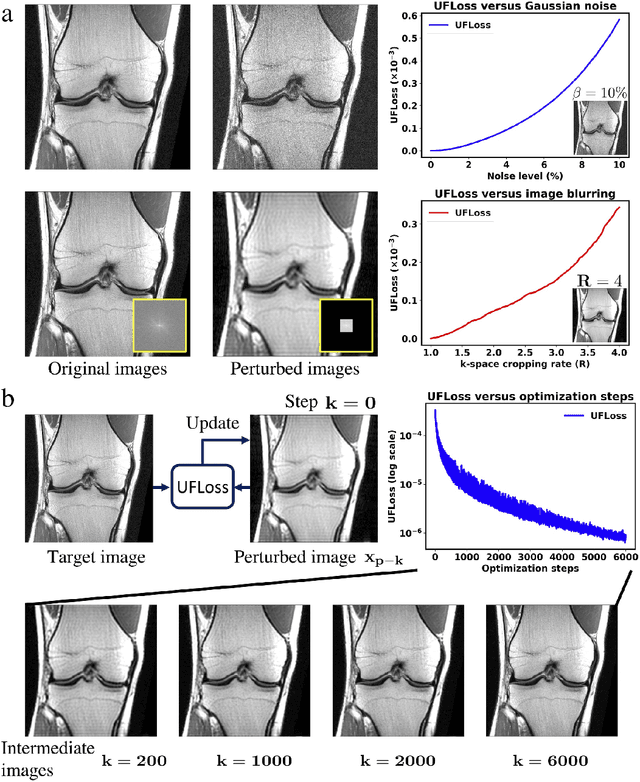
Purpose: To improve reconstruction fidelity of fine structures and textures in deep learning (DL) based reconstructions. Methods: A novel patch-based Unsupervised Feature Loss (UFLoss) is proposed and incorporated into the training of DL-based reconstruction frameworks in order to preserve perceptual similarity and high-order statistics. The UFLoss provides instance-level discrimination by mapping similar instances to similar low-dimensional feature vectors and is trained without any human annotation. By adding an additional loss function on the low-dimensional feature space during training, the reconstruction frameworks from under-sampled or corrupted data can reproduce more realistic images that are closer to the original with finer textures, sharper edges, and improved overall image quality. The performance of the proposed UFLoss is demonstrated on unrolled networks for accelerated 2D and 3D knee MRI reconstruction with retrospective under-sampling. Quantitative metrics including NRMSE, SSIM, and our proposed UFLoss were used to evaluate the performance of the proposed method and compare it with others. Results: In-vivo experiments indicate that adding the UFLoss encourages sharper edges and more faithful contrasts compared to traditional and learning-based methods with pure l2 loss. More detailed textures can be seen in both 2D and 3D knee MR images. Quantitative results indicate that reconstruction with UFLoss can provide comparable NRMSE and a higher SSIM while achieving a much lower UFLoss value. Conclusion: We present UFLoss, a patch-based unsupervised learned feature loss, which allows the training of DL-based reconstruction to obtain more detailed texture, finer features, and sharper edges with higher overall image quality under DL-based reconstruction frameworks.