 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiecewise Dynamic Diffusion Regularization for Reconstruction of Cardiac Cine MRI
Jul 03, 2026Real-time cardiac cine MRI enables visualization of the beating heart during free breathing, but severe undersampling and motion make reconstruction highly challenging. A central challenge for reconstruction is incorporating powerful priors of cardiac anatomy while remaining computationally efficient. We propose Piecewise Dynamic Diffusion Regularization (PDDR), a reconstruction method that integrates a spatiotemporal diffusion model as a generative prior within a variational reconstruction framework for cine MRI. The model employs dedicated spatial layers to encode anatomical structure and temporal layers to capture cardiac motion learned from gated cine data. PDDR leverages the dynamic prior in a piecewise manner, enabling the efficient use of spatiotemporal diffusion models for processing of long real-time sequences. Experiments on retrospectively accelerated and prospective real-time cine MRI demonstrate that PDDR outperforms classical, unsupervised, and diffusion-based methods, delivering high-quality reconstructions with substantially reduced computation time compared to state-of-the-art baselines. These results highlight PDDR as a practical and scalable solution for free-breathing, real-time cardiac MRI. Code is available at https://github.com/MLI-lab/pddr.
OpenThoughts-Agent: Data Recipes for Agentic Models
Jun 23, 2026Agentic language models dramatically expand the applications of AI yet little is publicly known about how to curate training data for broadly capable agents. Existing open efforts such as SWE-Smith, SERA, and Nemotron-Terminal typically target a single benchmark, leaving open the question of how to train models that generalize across diverse agentic tasks. The OpenThoughts-Agent (OT-Agent) project addresses this gap with a fully open data curation pipeline for training agentic models. We conduct more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline, yielding insights on the importance of task sources and diversity. We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks and a 3.9 percentage point improvement over the strongest existing open data agentic model (Nemotron-Terminal-32B, 40.9%). Moreover, our training data exhibits strong scaling properties, outperforming alternative open datasets at every training set size in compute-controlled comparisons. We publicly release our training sets, data pipeline, experimental data, and models at openthoughts.ai to support future open research on agentic model training.
Test-time RL alignment exposes task familiarity artifacts in LLM benchmarks
Mar 13, 2026Direct evaluation of LLMs on benchmarks can be misleading because comparatively strong performance may reflect task familiarity rather than capability. The train-before-test approach controls for task familiarity by giving each model task-relevant training before evaluation, originally through supervised finetuning. However, suitable training data is often hard to come by, and evaluation results vary with the data chosen. In this paper, we propose a two-stage test-time reinforcement learning (RL) alignment method for train-before-test. First, RL with a single sample provides a first alignment of the model to the task format, and second, test-time RL with majority-voting reward aligns the model to the benchmark distribution. Our test-time RL alignment method aligns similarly well as SFT-based train-before test, but without requiring a task-specific training set. On a domain-specific benchmark without training data, we show that direct evaluation underestimates base models which perform substantially better once aligned, yielding a more faithful evaluation of their capabilities. Moreover, for reasoning tasks, the performance gap between fine-tuned models and their base models largely disappears after alignment, suggesting that many gains from RLVR/SFT reported in the literature are not a difference in reasoning capability, but rather artifacts of task familiarity.
Asymmetric Prompt Weighting for Reinforcement Learning with Verifiable Rewards
Feb 11, 2026Reinforcement learning with verifiable rewards has driven recent advances in LLM post-training, in particular for reasoning. Policy optimization algorithms generate a number of responses for a given prompt and then effectively weight the corresponding gradients depending on the rewards. The most popular algorithms including GRPO, DAPO, and RLOO focus on ambiguous prompts, i.e., prompts with intermediate success probability, while downgrading gradients with very easy and very hard prompts. In this paper, we consider asymmetric prompt weightings that assign higher weights to prompts with low, or even zero, empirical success probability. We find that asymmetric weighting particularly benefits from-scratch RL (as in R1-Zero), where training traverses a wide accuracy range, and less so in post-SFT RL where the model already starts at high accuracy. We also provide theory that characterizes prompt weights which minimize the time needed to raise success probability from an initial level to a target accuracy under a fixed update budget. In low-success regimes, where informative responses are rare and response cost dominates, these optimal weights become asymmetric, upweighting low success probabilities and thereby accelerating effective-time convergence.
Reliable Evaluation of MRI Motion Correction: Dataset and Insights
Jun 06, 2025Correcting motion artifacts in MRI is important, as they can hinder accurate diagnosis. However, evaluating deep learning-based and classical motion correction methods remains fundamentally difficult due to the lack of accessible ground-truth target data. To address this challenge, we study three evaluation approaches: real-world evaluation based on reference scans, simulated motion, and reference-free evaluation, each with its merits and shortcomings. To enable evaluation with real-world motion artifacts, we release PMoC3D, a dataset consisting of unprocessed Paired Motion-Corrupted 3D brain MRI data. To advance evaluation quality, we introduce MoMRISim, a feature-space metric trained for evaluating motion reconstructions. We assess each evaluation approach and find real-world evaluation together with MoMRISim, while not perfect, to be most reliable. Evaluation based on simulated motion systematically exaggerates algorithm performance, and reference-free evaluation overrates oversmoothed deep learning outputs.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Efficient Noise Calculation in Deep Learning-based MRI Reconstructions
May 04, 2025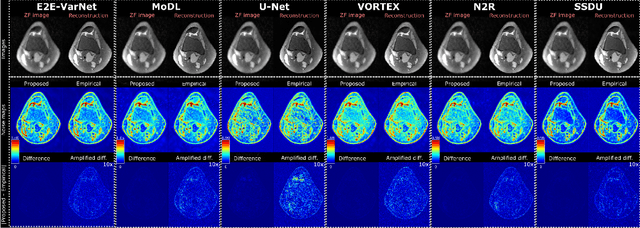
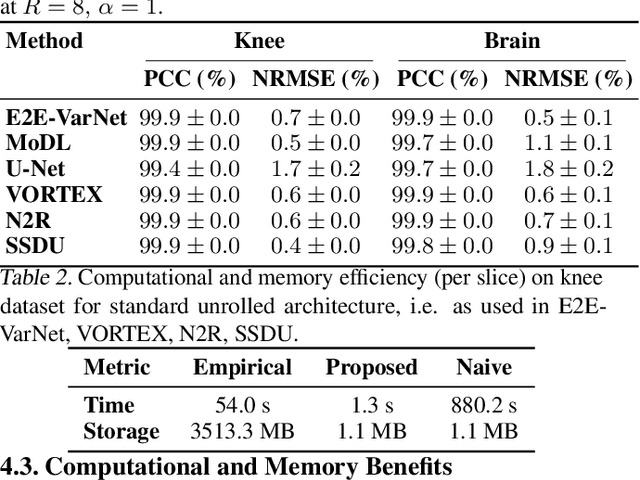
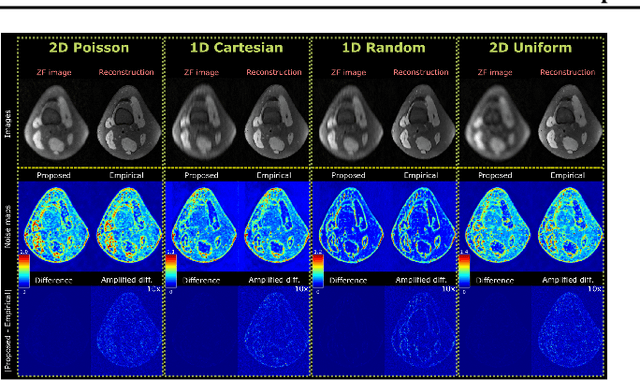
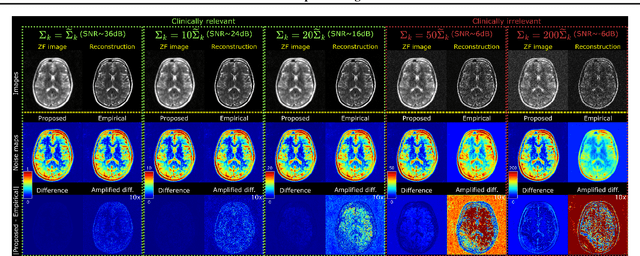
Accelerated MRI reconstruction involves solving an ill-posed inverse problem where noise in acquired data propagates to the reconstructed images. Noise analyses are central to MRI reconstruction for providing an explicit measure of solution fidelity and for guiding the design and deployment of novel reconstruction methods. However, deep learning (DL)-based reconstruction methods have often overlooked noise propagation due to inherent analytical and computational challenges, despite its critical importance. This work proposes a theoretically grounded, memory-efficient technique to calculate voxel-wise variance for quantifying uncertainty due to acquisition noise in accelerated MRI reconstructions. Our approach approximates noise covariance using the DL network's Jacobian, which is intractable to calculate. To circumvent this, we derive an unbiased estimator for the diagonal of this covariance matrix (voxel-wise variance) and introduce a Jacobian sketching technique to efficiently implement it. We evaluate our method on knee and brain MRI datasets for both data- and physics-driven networks trained in supervised and unsupervised manners. Compared to empirical references obtained via Monte Carlo simulations, our technique achieves near-equivalent performance while reducing computational and memory demands by an order of magnitude or more. Furthermore, our method is robust across varying input noise levels, acceleration factors, and diverse undersampling schemes, highlighting its broad applicability. Our work reintroduces accurate and efficient noise analysis as a central tenet of reconstruction algorithms, holding promise to reshape how we evaluate and deploy DL-based MRI. Our code will be made publicly available upon acceptance.
LLM-Guided Search for Deletion-Correcting Codes
Apr 01, 2025Finding deletion-correcting codes of maximum size has been an open problem for over 70 years, even for a single deletion. In this paper, we propose a novel approach for constructing deletion-correcting codes. A code is a set of sequences satisfying certain constraints, and we construct it by greedily adding the highest-priority sequence according to a priority function. To find good priority functions, we leverage FunSearch, a large language model (LLM)-guided evolutionary search proposed by Romera et al., 2024. FunSearch iteratively generates, evaluates, and refines priority functions to construct large deletion-correcting codes. For a single deletion, our evolutionary search finds functions that construct codes which match known maximum sizes, reach the size of the largest (conjectured optimal) Varshamov-Tenengolts codes where the maximum is unknown, and independently rediscover them in equivalent form. For two deletions, we find functions that construct codes with new best-known sizes for code lengths \( n = 12, 13 \), and \( 16 \), establishing improved lower bounds. These results demonstrate the potential of LLM-guided search for information theory and code design and represent the first application of such methods for constructing error-correcting codes.
Resolution-Robust 3D MRI Reconstruction with 2D Diffusion Priors: Diverse-Resolution Training Outperforms Interpolation
Dec 24, 2024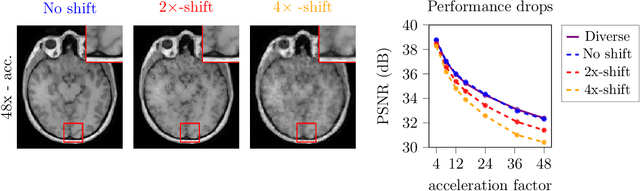

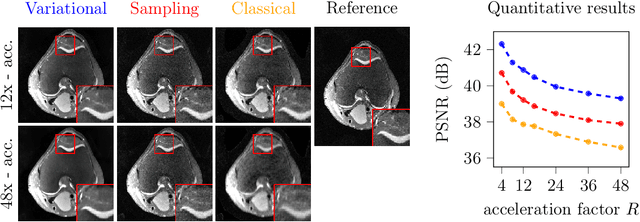
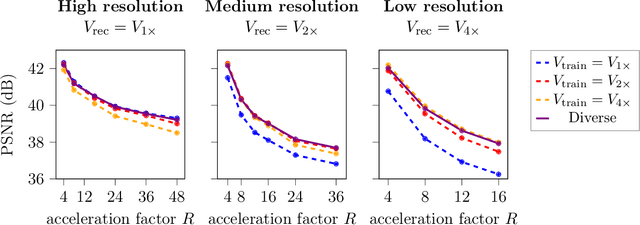
Deep learning-based 3D imaging, in particular magnetic resonance imaging (MRI), is challenging because of limited availability of 3D training data. Therefore, 2D diffusion models trained on 2D slices are starting to be leveraged for 3D MRI reconstruction. However, as we show in this paper, existing methods pertain to a fixed voxel size, and performance degrades when the voxel size is varied, as it is often the case in clinical practice. In this paper, we propose and study several approaches for resolution-robust 3D MRI reconstruction with 2D diffusion priors. As a result of this investigation, we obtain a simple resolution-robust variational 3D reconstruction approach based on diffusion-guided regularization of randomly sampled 2D slices. This method provides competitive reconstruction quality compared to posterior sampling baselines. Towards resolving the sensitivity to resolution-shifts, we investigate state-of-the-art model-based approaches including Gaussian splatting, neural representations, and infinite-dimensional diffusion models, as well as a simple data-centric approach of training the diffusion model on several resolutions. Our experiments demonstrate that the model-based approaches fail to close the performance gap in 3D MRI. In contrast, the data-centric approach of training the diffusion model on various resolutions effectively provides a resolution-robust method without compromising accuracy.
Measuring Bias of Web-filtered Text Datasets and Bias Propagation Through Training
Dec 03, 2024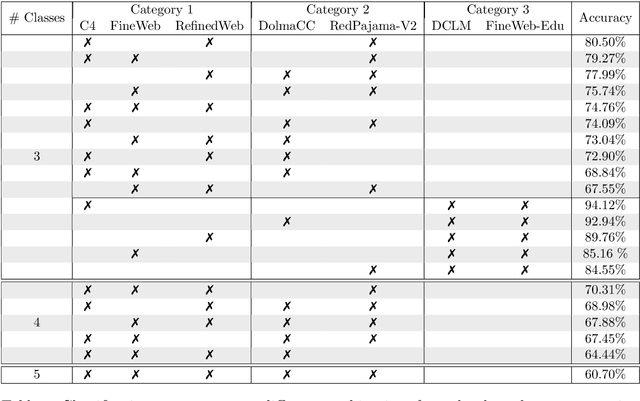


We investigate biases in pretraining datasets for large language models (LLMs) through dataset classification experiments. Building on prior work demonstrating the existence of biases in popular computer vision datasets, we analyze popular open-source pretraining datasets for LLMs derived from CommonCrawl including C4, RefinedWeb, DolmaCC, RedPajama-V2, FineWeb, and DCLM-Baseline. Despite those datasets being obtained with similar filtering and deduplication steps, neural networks can classify surprisingly well which dataset a single text sequence belongs to, significantly better than a human can. This indicates that popular pretraining datasets have their own unique biases or fingerprints. Those biases remain even when the text is rewritten with LLMs. Moreover, these biases propagate through training: Random sequences generated by models trained on those datasets can be classified well by a classifier trained on the original datasets.