 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning of personalized priors from past MRI scans enables fast, quality-enhanced point-of-care MRI with low-cost systems
May 05, 2025Magnetic resonance imaging (MRI) offers superb-quality images, but its accessibility is limited by high costs, posing challenges for patients requiring longitudinal care. Low-field MRI provides affordable imaging with low-cost devices but is hindered by long scans and degraded image quality, including low signal-to-noise ratio (SNR) and tissue contrast. We propose a novel healthcare paradigm: using deep learning to extract personalized features from past standard high-field MRI scans and harnessing them to enable accelerated, enhanced-quality follow-up scans with low-cost systems. To overcome the SNR and contrast differences, we introduce ViT-Fuser, a feature-fusion vision transformer that learns features from past scans, e.g. those stored in standard DICOM CDs. We show that \textit{a single prior scan is sufficient}, and this scan can come from various MRI vendors, field strengths, and pulse sequences. Experiments with four datasets, including glioblastoma data, low-field ($50mT$), and ultra-low-field ($6.5mT$) data, demonstrate that ViT-Fuser outperforms state-of-the-art methods, providing enhanced-quality images from accelerated low-field scans, with robustness to out-of-distribution data. Our freely available framework thus enables rapid, diagnostic-quality, low-cost imaging for wide healthcare applications.
Reference-Free Image Quality Metric for Degradation and Reconstruction Artifacts
May 01, 2024



Image Quality Assessment (IQA) is essential in various Computer Vision tasks such as image deblurring and super-resolution. However, most IQA methods require reference images, which are not always available. While there are some reference-free IQA metrics, they have limitations in simulating human perception and discerning subtle image quality variations. We hypothesize that the JPEG quality factor is representatives of image quality measurement, and a well-trained neural network can learn to accurately evaluate image quality without requiring a clean reference, as it can recognize image degradation artifacts based on prior knowledge. Thus, we developed a reference-free quality evaluation network, dubbed "Quality Factor (QF) Predictor", which does not require any reference. Our QF Predictor is a lightweight, fully convolutional network comprising seven layers. The model is trained in a self-supervised manner: it receives JPEG compressed image patch with a random QF as input, is trained to accurately predict the corresponding QF. We demonstrate the versatility of the model by applying it to various tasks. First, our QF Predictor can generalize to measure the severity of various image artifacts, such as Gaussian Blur and Gaussian noise. Second, we show that the QF Predictor can be trained to predict the undersampling rate of images reconstructed from Magnetic Resonance Imaging (MRI) data.
Deep Learning for Accelerated and Robust MRI Reconstruction: a Review
Apr 24, 2024



Deep learning (DL) has recently emerged as a pivotal technology for enhancing magnetic resonance imaging (MRI), a critical tool in diagnostic radiology. This review paper provides a comprehensive overview of recent advances in DL for MRI reconstruction. It focuses on DL approaches and architectures designed to improve image quality, accelerate scans, and address data-related challenges. These include end-to-end neural networks, pre-trained networks, generative models, and self-supervised methods. The paper also discusses the role of DL in optimizing acquisition protocols, enhancing robustness against distribution shifts, and tackling subtle bias. Drawing on the extensive literature and practical insights, it outlines current successes, limitations, and future directions for leveraging DL in MRI reconstruction, while emphasizing the potential of DL to significantly impact clinical imaging practices.
K-band: Self-supervised MRI Reconstruction via Stochastic Gradient Descent over K-space Subsets
Aug 05, 2023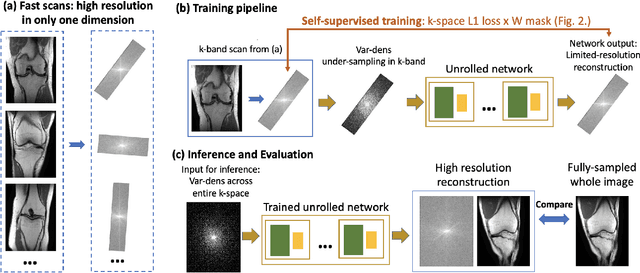
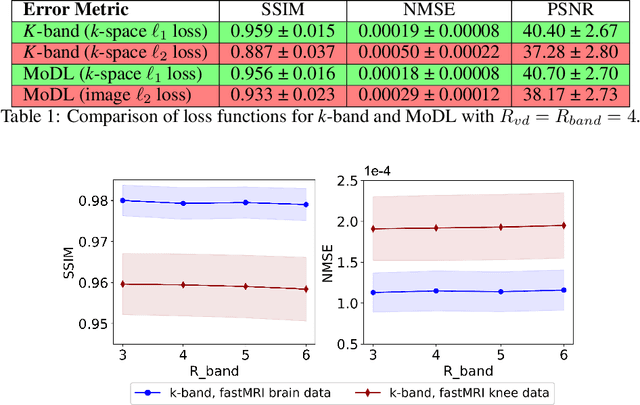
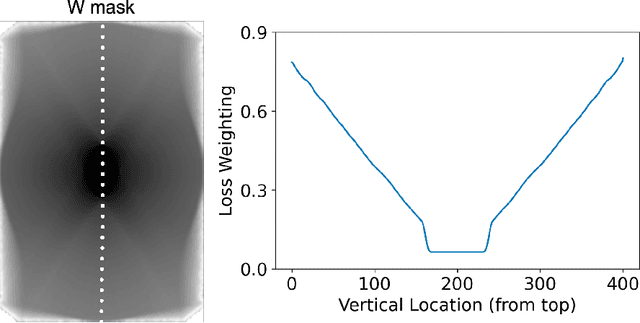

Although deep learning (DL) methods are powerful for solving inverse problems, their reliance on high-quality training data is a major hurdle. This is significant in high-dimensional (dynamic/volumetric) magnetic resonance imaging (MRI), where acquisition of high-resolution fully sampled k-space data is impractical. We introduce a novel mathematical framework, dubbed k-band, that enables training DL models using only partial, limited-resolution k-space data. Specifically, we introduce training with stochastic gradient descent (SGD) over k-space subsets. In each training iteration, rather than using the fully sampled k-space for computing gradients, we use only a small k-space portion. This concept is compatible with different sampling strategies; here we demonstrate the method for k-space "bands", which have limited resolution in one dimension and can hence be acquired rapidly. We prove analytically that our method stochastically approximates the gradients computed in a fully-supervised setup, when two simple conditions are met: (i) the limited-resolution axis is chosen randomly-uniformly for every new scan, hence k-space is fully covered across the entire training set, and (ii) the loss function is weighed with a mask, derived here analytically, which facilitates accurate reconstruction of high-resolution details. Numerical experiments with raw MRI data indicate that k-band outperforms two other methods trained on limited-resolution data and performs comparably to state-of-the-art (SoTA) methods trained on high-resolution data. k-band hence obtains SoTA performance, with the advantage of training using only limited-resolution data. This work hence introduces a practical, easy-to-implement, self-supervised training framework, which involves fast acquisition and self-supervised reconstruction and offers theoretical guarantees.
Subtle Inverse Crimes: Naïvely training machine learning algorithms could lead to overly-optimistic results
Sep 24, 2021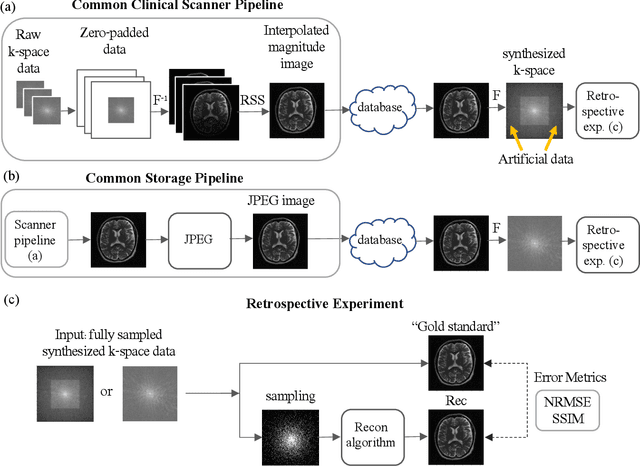
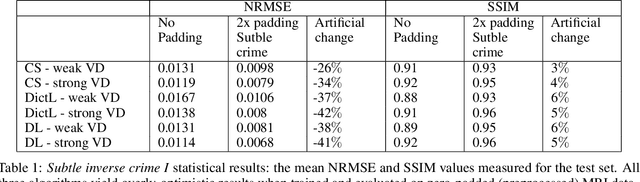
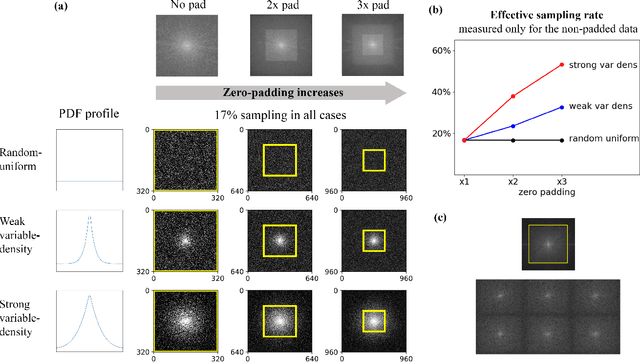
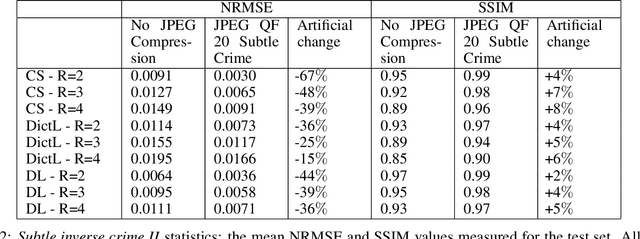
While open databases are an important resource in the Deep Learning (DL) era, they are sometimes used "off-label": data published for one task are used for training algorithms for a different one. This work aims to highlight that in some cases, this common practice may lead to biased, overly-optimistic results. We demonstrate this phenomenon for inverse problem solvers and show how their biased performance stems from hidden data preprocessing pipelines. We describe two preprocessing pipelines typical of open-access databases and study their effects on three well-established algorithms developed for Magnetic Resonance Imaging (MRI) reconstruction: Compressed Sensing (CS), Dictionary Learning (DictL), and DL. In this large-scale study we performed extensive computations. Our results demonstrate that the CS, DictL and DL algorithms yield systematically biased results when na\"ively trained on seemingly-appropriate data: the Normalized Root Mean Square Error (NRMSE) improves consistently with the preprocessing extent, showing an artificial increase of 25%-48% in some cases. Since this phenomenon is generally unknown, biased results are sometimes published as state-of-the-art; we refer to that as subtle inverse crimes. This work hence raises a red flag regarding na\"ive off-label usage of Big Data and reveals the vulnerability of modern inverse problem solvers to the resulting bias.