 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAAST: Forward-Only Associative Learning via Closed-Form Fast Weights for Test-Time Supervised Adaptation
May 06, 2026Adapting pretrained models typically involves a trade-off between the high training costs of backpropagation and the heavy inference overhead of memory-based or in-context learning. We propose FAAST, a forward-only associative adaptation method that analytically compiles labeled examples into fast weights in a single pass. By eliminating memory or context dependence, FAAST achieves constant-time inference and decouples task adaptation from pretrained representation. Across image classification and language modeling benchmarks, FAAST matches or exceeds backprop-based adaptation while reducing adaptation time by over 90\% and is competitive to memory/context-based adaptation while saving memory usage by up to 95\%. These results demonstrate FAAST as a highly efficient, scalable solution for supervised task adaptation, particularly for resource-constrained models. We release the code and models at https://github.com/baoguangsheng/faast.
Channel Estimation and LDPC Decoding for Bursty Phase Noise
Apr 08, 2026Time-varying distortions in communication systems can significantly degrade the performance of soft-decision forward error correction. This paper presents a burst-aware (BA) low-density parity-check (LDPC) decoding scheme for channels affected by bursty phase noise. By applying differential coding to a Wiener process with time-varying innovation variance, bursty differential phase noise is obtained. Simulation results demonstrate that, compared to conventional decoding, the BA scheme achieves gains in the signal-to-noise ratio of up to $0.7$~dB at a bit error rate (BER) of $4\cdot10^{-3}$ and more than $1$~dB at a packet error rate (PER) of $1\cdot10^{-2}$. Furthermore, by iterating between channel estimation and \ac{ldpc} decoding, forming the proposed iterative burst-aware (IBA) decoding scheme, the gains increase to $1.4$~dB and more than $3$~dB, respectively. More importantly, the IBA scheme significantly improves robustness to bursty phase noise. Compared with the conventional scheme, the IBA scheme can reduce both \ac{ber} and \ac{per} by up to two orders of magnitude under severe bursty phase noise.
Minimizing Mismatch Risk: A Prototype-Based Routing Framework for Zero-shot LLM-generated Text Detection
Feb 01, 2026Zero-shot methods detect LLM-generated text by computing statistical signatures using a surrogate model. Existing approaches typically employ a fixed surrogate for all inputs regardless of the unknown source. We systematically examine this design and find that detection performance varies substantially depending on surrogate-source alignment. We observe that while no single surrogate achieves optimal performance universally, a well-matched surrogate typically exists within a diverse pool for any given input. This finding transforms robust detection into a routing problem: selecting the most appropriate surrogate for each input. We propose DetectRouter, a prototype-based framework that learns text-detector affinity through two-stage training. The first stage constructs discriminative prototypes from white-box models; the second generalizes to black-box sources by aligning geometric distances with observed detection scores. Experiments on EvoBench and MAGE benchmarks demonstrate consistent improvements across multiple detection criteria and model families.
When AI Settles Down: Late-Stage Stability as a Signature of AI-Generated Text Detection
Jan 08, 2026Zero-shot detection methods for AI-generated text typically aggregate token-level statistics across entire sequences, overlooking the temporal dynamics inherent to autoregressive generation. We analyze over 120k text samples and reveal Late-Stage Volatility Decay: AI-generated text exhibits rapidly stabilizing log probability fluctuations as generation progresses, while human writing maintains higher variability throughout. This divergence peaks in the second half of sequences, where AI-generated text shows 24--32\% lower volatility. Based on this finding, we propose two simple features: Derivative Dispersion and Local Volatility, which computed exclusively from late-stage statistics. Without perturbation sampling or additional model access, our method achieves state-of-the-art performance on EvoBench and MAGE benchmarks and demonstrates strong complementarity with existing global methods.
Direct Value Optimization: Improving Chain-of-Thought Reasoning in LLMs with Refined Values
Feb 19, 2025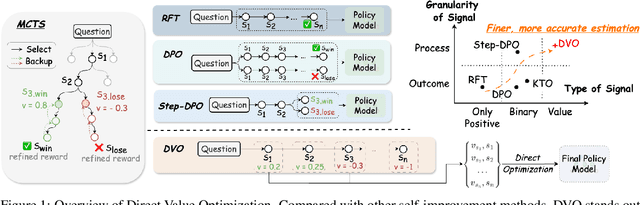
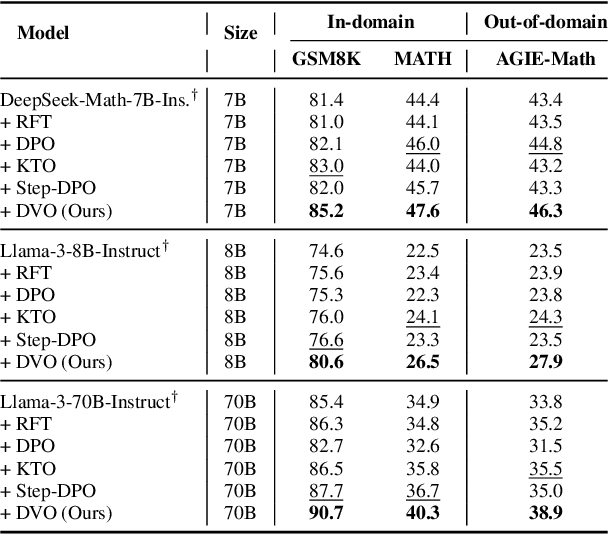
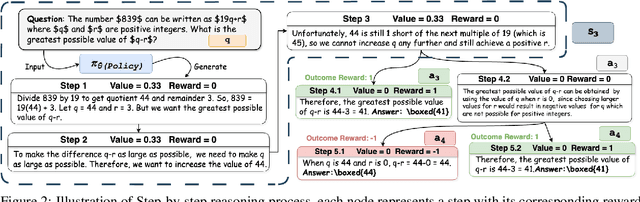
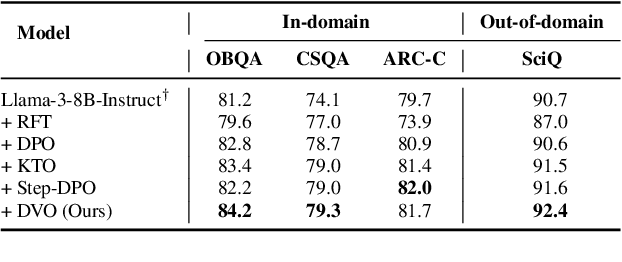
We introduce Direct Value Optimization (DVO), an innovative reinforcement learning framework for enhancing large language models in complex reasoning tasks. Unlike traditional methods relying on preference labels, DVO utilizes value signals at individual reasoning steps, optimizing models via a mean squared error loss. The key benefit of DVO lies in its fine-grained supervision, circumventing the need for labor-intensive human annotations. Target values within the DVO are estimated using either Monte Carlo Tree Search or an outcome value model. Our empirical analysis on both mathematical and commonsense reasoning tasks shows that DVO consistently outperforms existing offline preference optimization techniques, even with fewer training steps. These findings underscore the importance of value signals in advancing reasoning capabilities and highlight DVO as a superior methodology under scenarios lacking explicit human preference information.
Reference-Free Image Quality Metric for Degradation and Reconstruction Artifacts
May 01, 2024



Image Quality Assessment (IQA) is essential in various Computer Vision tasks such as image deblurring and super-resolution. However, most IQA methods require reference images, which are not always available. While there are some reference-free IQA metrics, they have limitations in simulating human perception and discerning subtle image quality variations. We hypothesize that the JPEG quality factor is representatives of image quality measurement, and a well-trained neural network can learn to accurately evaluate image quality without requiring a clean reference, as it can recognize image degradation artifacts based on prior knowledge. Thus, we developed a reference-free quality evaluation network, dubbed "Quality Factor (QF) Predictor", which does not require any reference. Our QF Predictor is a lightweight, fully convolutional network comprising seven layers. The model is trained in a self-supervised manner: it receives JPEG compressed image patch with a random QF as input, is trained to accurately predict the corresponding QF. We demonstrate the versatility of the model by applying it to various tasks. First, our QF Predictor can generalize to measure the severity of various image artifacts, such as Gaussian Blur and Gaussian noise. Second, we show that the QF Predictor can be trained to predict the undersampling rate of images reconstructed from Magnetic Resonance Imaging (MRI) data.
Exploring Hybrid Question Answering via Program-based Prompting
Feb 16, 2024



Question answering over heterogeneous data requires reasoning over diverse sources of data, which is challenging due to the large scale of information and organic coupling of heterogeneous data. Various approaches have been proposed to address these challenges. One approach involves training specialized retrievers to select relevant information, thereby reducing the input length. Another approach is to transform diverse modalities of data into a single modality, simplifying the task difficulty and enabling more straightforward processing. In this paper, we propose HProPro, a novel program-based prompting framework for the hybrid question answering task. HProPro follows the code generation and execution paradigm. In addition, HProPro integrates various functions to tackle the hybrid reasoning scenario. Specifically, HProPro contains function declaration and function implementation to perform hybrid information-seeking over data from various sources and modalities, which enables reasoning over such data without training specialized retrievers or performing modal transformations. Experimental results on two typical hybrid question answering benchmarks HybridQA and MultiModalQA demonstrate the effectiveness of HProPro: it surpasses all baseline systems and achieves the best performances in the few-shot settings on both datasets.
MiliPoint: A Point Cloud Dataset for mmWave Radar
Sep 23, 2023



Millimetre-wave (mmWave) radar has emerged as an attractive and cost-effective alternative for human activity sensing compared to traditional camera-based systems. mmWave radars are also non-intrusive, providing better protection for user privacy. However, as a Radio Frequency (RF) based technology, mmWave radars rely on capturing reflected signals from objects, making them more prone to noise compared to cameras. This raises an intriguing question for the deep learning community: Can we develop more effective point set-based deep learning methods for such attractive sensors? To answer this question, our work, termed MiliPoint, delves into this idea by providing a large-scale, open dataset for the community to explore how mmWave radars can be utilised for human activity recognition. Moreover, MiliPoint stands out as it is larger in size than existing datasets, has more diverse human actions represented, and encompasses all three key tasks in human activity recognition. We have also established a range of point-based deep neural networks such as DGCNN, PointNet++ and PointTransformer, on MiliPoint, which can serve to set the ground baseline for further development.
Explanation Graph Generation via Generative Pre-training over Synthetic Graphs
Jun 01, 2023



The generation of explanation graphs is a significant task that aims to produce explanation graphs in response to user input, revealing the internal reasoning process. This task is challenging due to the significant discrepancy between unstructured user queries and structured explanation graphs. Current research commonly fine-tunes a text-based pre-trained language model on a small downstream dataset that is annotated with labeled graphs. However, due to the limited scale of available datasets, this approach may prove to be insufficient in bridging the gap between natural language text and structured graphs. In this paper, to alleviate the above limitations, we propose a novel pre-trained framework EG3P(for Explanation Graph Generation via Generative Pre-training over synthetic graphs) for the explanation graph generation task. Specifically, we first propose a text-to-graph generative task to pre-train the model with the goal of bridging the text-graph gap. Additionally, we propose an automatic corpus synthesis strategy for synthesizing a large scale of high-quality corpus, reducing the reliance on costly manual annotation methods. Experimental results on ExplaGraphs show the effectiveness of EG3P that our model surpasses all baseline systems with remarkable margins. Besides, further analysis demonstrates that EG3P is able to generate better explanation graphs on actual reasoning tasks such as CommonsenseQA and OpenbookQA.
Millimetre-wave Radar for Low-Cost 3D Imaging: A Performance Study
Jan 31, 2023Millimetre-wave (mmWave) radars can generate 3D point clouds to represent objects in the scene. However, the accuracy and density of the generated point cloud can be lower than a laser sensor. Although researchers have used mmWave radars for various applications, there are few quantitative evaluations on the quality of the point cloud generated by the radar and there is a lack of a standard on how this quality can be assessed. This work aims to fill the gap in the literature. A radar simulator is built to evaluate the most common data processing chains of 3D point cloud construction and to examine the capability of the mmWave radar as a 3D imaging sensor under various factors. It will be shown that the radar detection can be noisy and have an imbalance distribution. To address the problem, a novel super-resolution point cloud construction (SRPC) algorithm is proposed to improve the spatial resolution of the point cloud and is shown to be able to produce a more natural point cloud and reduce outliers.