 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Detection and Mitigation of Concept Drift for Federated Learning based IoT Deployments
May 15, 2023Intelligent, large-scale IoT ecosystems have become possible due to recent advancements in sensing technologies, distributed learning, and low-power inference in embedded devices. In traditional cloud-centric approaches, raw data is transmitted to a central server for training and inference purposes. On the other hand, Federated Learning migrates both tasks closer to the edge nodes and endpoints. This allows for a significant reduction in data exchange while preserving the privacy of users. Trained models, though, may under-perform in dynamic environments due to changes in the data distribution, affecting the model's ability to infer accurately; this is referred to as concept drift. Such drift may also be adversarial in nature. Therefore, it is of paramount importance to detect such behaviours promptly. In order to simultaneously reduce communication traffic and maintain the integrity of inference models, we introduce FLARE, a novel lightweight dual-scheduler FL framework that conditionally transfers training data, and deploys models between edge and sensor endpoints based on observing the model's training behaviour and inference statistics, respectively. We show that FLARE can significantly reduce the amount of data exchanged between edge and sensor nodes compared to fixed-interval scheduling methods (over 5x reduction), is easily scalable to larger systems, and can successfully detect concept drift reactively with at least a 16x reduction in latency.
Deep Transfer Learning for WiFi Localization
Mar 08, 2021
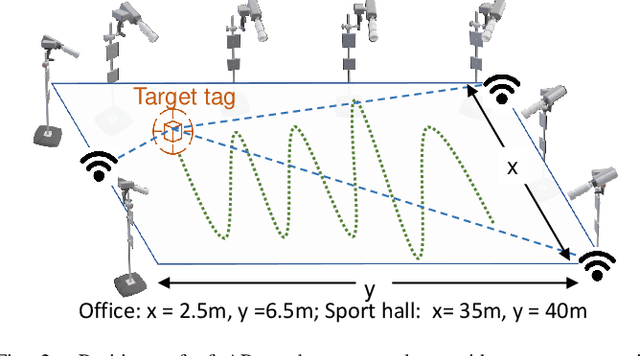
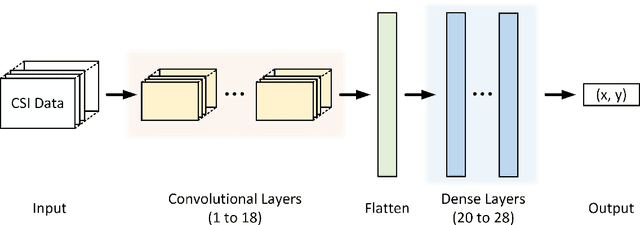
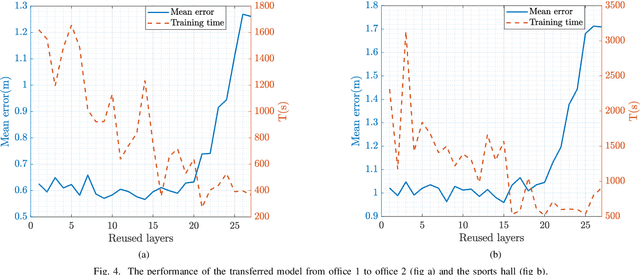
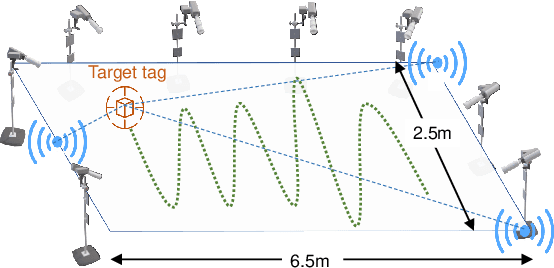
This paper studies a WiFi indoor localisation technique based on using a deep learning model and its transfer strategies. We take CSI packets collected via the WiFi standard channel sounding as the training dataset and verify the CNN model on the subsets collected in three experimental environments. We achieve a localisation accuracy of 46.55 cm in an ideal $(6.5m \times 2.5m)$ office with no obstacles, 58.30 cm in an office with obstacles, and 102.8 cm in a sports hall $(40 \times 35m)$. Then, we evaluate the transfer ability of the proposed model to different environments. The experimental results show that, for a trained localisation model, feature extraction layers can be directly transferred to other models and only the fully connected layers need to be retrained to achieve the same baseline accuracy with non-transferred base models. This can save 60% of the training parameters and reduce the training time by more than half. Finally, an ablation study of the training dataset shows that, in both office and sport hall scenarios, after reusing the feature extraction layers of the base model, only 55% of the training data is required to obtain the models' accuracy similar to the base models.
Wireless Localisation in WiFi using Novel Deep Architectures
Oct 16, 2020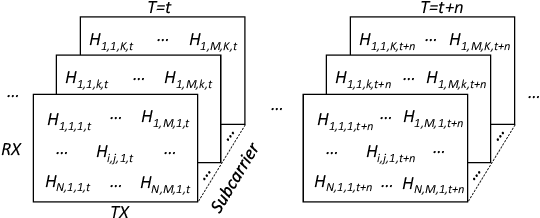
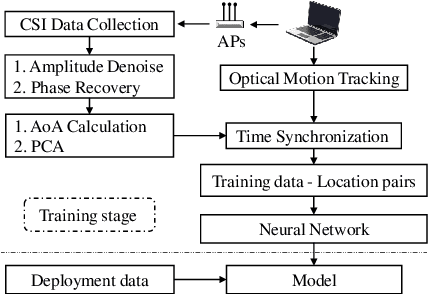
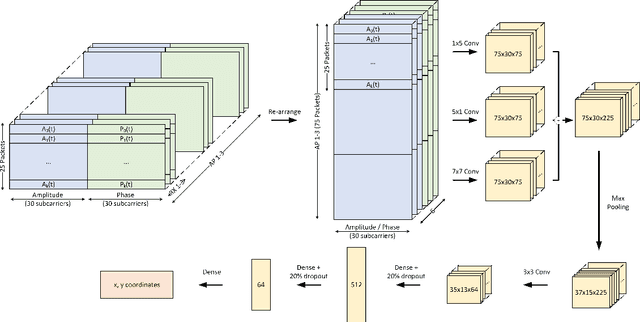
This paper studies the indoor localisation of WiFi devices based on a commodity chipset and standard channel sounding. First, we present a novel shallow neural network (SNN) in which features are extracted from the channel state information (CSI) corresponding to WiFi subcarriers received on different antennas and used to train the model. The single-layer architecture of this localisation neural network makes it lightweight and easy-to-deploy on devices with stringent constraints on computational resources. We further investigate for localisation the use of deep learning models and design novel architectures for convolutional neural network (CNN) and long-short term memory (LSTM). We extensively evaluate these localisation algorithms for continuous tracking in indoor environments. Experimental results prove that even an SNN model, after a careful handcrafted feature extraction, can achieve accurate localisation. Meanwhile, using a well-organised architecture, the neural network models can be trained directly with raw data from the CSI and localisation features can be automatically extracted to achieve accurate position estimates. We also found that the performance of neural network-based methods are directly affected by the number of anchor access points (APs) regardless of their structure. With three APs, all neural network models proposed in this paper can obtain localisation accuracy of around 0.5 metres. In addition the proposed deep NN architecture reduces the data pre-processing time by 6.5 hours compared with a shallow NN using the data collected in our testbed. In the deployment phase, the inference time is also significantly reduced to 0.1 ms per sample. We also demonstrate the generalisation capability of the proposed method by evaluating models using different target movement characteristics to the ones in which they were trained.
Standing on the Shoulders of Giants: AI-driven Calibration of Localisation Technologies
May 30, 2019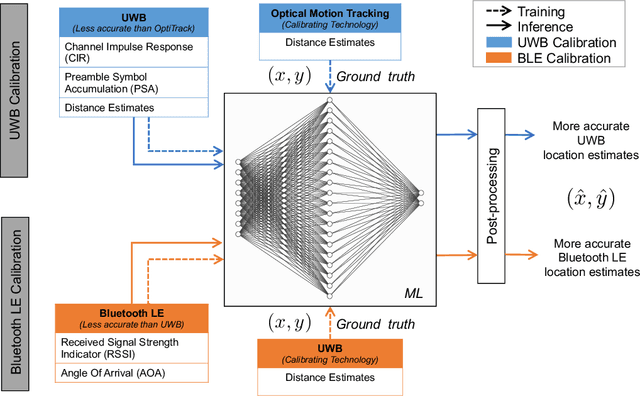
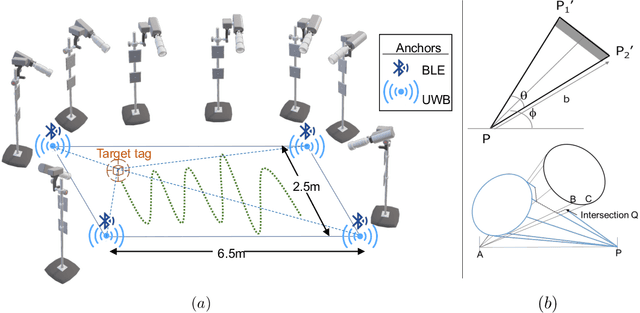
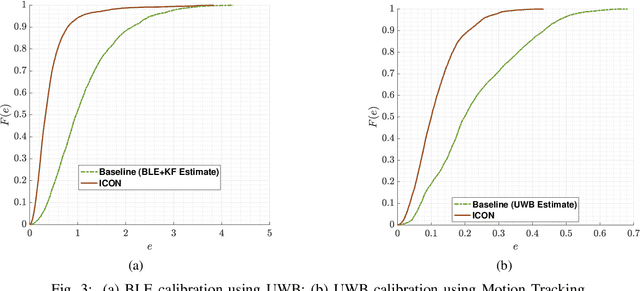
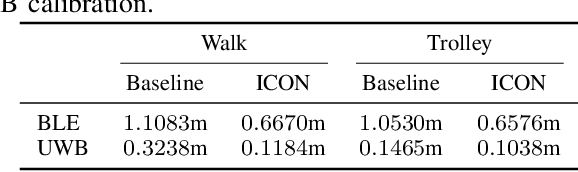
High accuracy localisation technologies exist but are prohibitively expensive to deploy for large indoor spaces such as warehouses, factories, and supermarkets to track assets and people. However, these technologies can be used to lend their highly accurate localisation capabilities to low-cost, commodity, and less-accurate technologies. In this paper, we bridge this link by proposing a technology-agnostic calibration framework based on artificial intelligence to assist such low-cost technologies through highly accurate localisation systems. A single-layer neural network is used to calibrate less accurate technology using more accurate one such as BLE using UWB and UWB using a professional motion tracking system. On a real indoor testbed, we demonstrate an increase in accuracy of approximately 70% for BLE and 50% for UWB. Not only the proposed approach requires a very short measurement campaign, the low complexity of the single-layer neural network also makes it ideal for deployment on constrained devices typically for localisation purposes.