 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexApp Distillation: AI-based Conflict Mitigation in B5G O-RAN
Jul 03, 2024The advancements of machine learning-based (ML) decision-making algorithms created various research and industrial opportunities. One of these areas is ML-based near-real-time network management applications (xApps) in Open-Radio Access Network (O-RAN). Normally, xApps are designed solely for the desired objectives, and fine-tuned for deployment. However, telecommunication companies can employ multiple xApps and deploy them in overlapping areas. Consider the different design objectives of xApps, the deployment might cause conflicts. To prevent such conflicts, we proposed the xApp distillation method that distills knowledge from multiple xApps, then uses this knowledge to train a single model that has retained the capabilities of Previous xApps. Performance evaluations show that compared conflict mitigation schemes can cause up to six times more network outages than xApp distillation in some cases.
LL-VQ-VAE: Learnable Lattice Vector-Quantization For Efficient Representations
Oct 13, 2023In this paper we introduce learnable lattice vector quantization and demonstrate its effectiveness for learning discrete representations. Our method, termed LL-VQ-VAE, replaces the vector quantization layer in VQ-VAE with lattice-based discretization. The learnable lattice imposes a structure over all discrete embeddings, acting as a deterrent against codebook collapse, leading to high codebook utilization. Compared to VQ-VAE, our method obtains lower reconstruction errors under the same training conditions, trains in a fraction of the time, and with a constant number of parameters (equal to the embedding dimension $D$), making it a very scalable approach. We demonstrate these results on the FFHQ-1024 dataset and include FashionMNIST and Celeb-A.
Federated Meta-Learning for Traffic Steering in O-RAN
Sep 13, 2022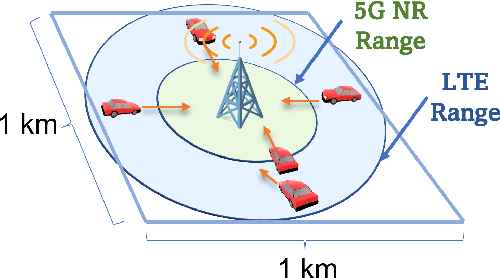
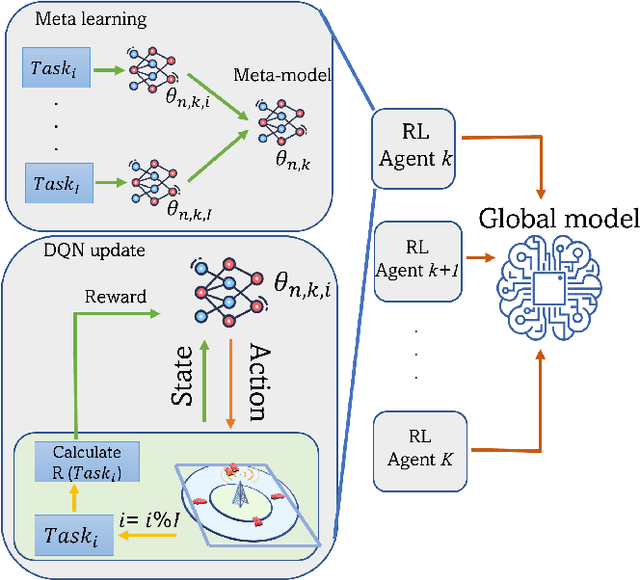
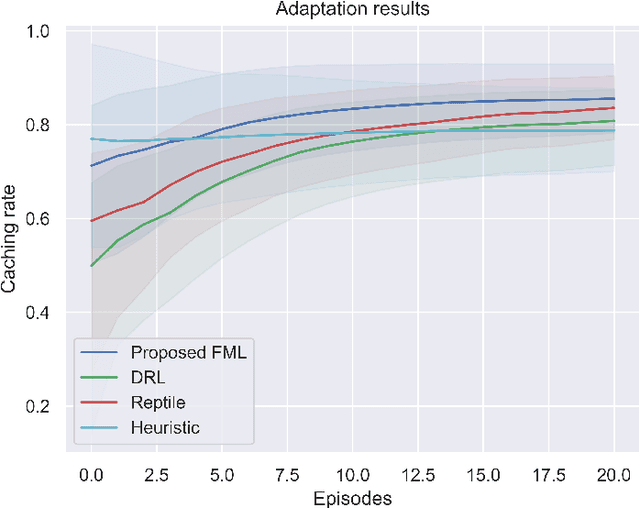
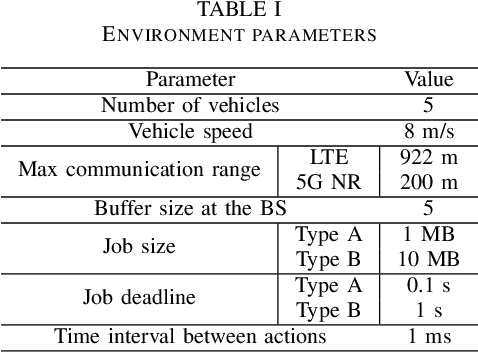
The vision of 5G lies in providing high data rates, low latency (for the aim of near-real-time applications), significantly increased base station capacity, and near-perfect quality of service (QoS) for users, compared to LTE networks. In order to provide such services, 5G systems will support various combinations of access technologies such as LTE, NR, NR-U and Wi-Fi. Each radio access technology (RAT) provides different types of access, and these should be allocated and managed optimally among the users. Besides resource management, 5G systems will also support a dual connectivity service. The orchestration of the network therefore becomes a more difficult problem for system managers with respect to legacy access technologies. In this paper, we propose an algorithm for RAT allocation based on federated meta-learning (FML), which enables RAN intelligent controllers (RICs) to adapt more quickly to dynamically changing environments. We have designed a simulation environment which contains LTE and 5G NR service technologies. In the simulation, our objective is to fulfil UE demands within the deadline of transmission to provide higher QoS values. We compared our proposed algorithm with a single RL agent, the Reptile algorithm and a rule-based heuristic method. Simulation results show that the proposed FML method achieves higher caching rates at first deployment round 21% and 12% respectively. Moreover, proposed approach adapts to new tasks and environments most quickly amongst the compared methods.
Variational Autoencoder Assisted Neural Network Likelihood RSRP Prediction Model
Jun 27, 2022
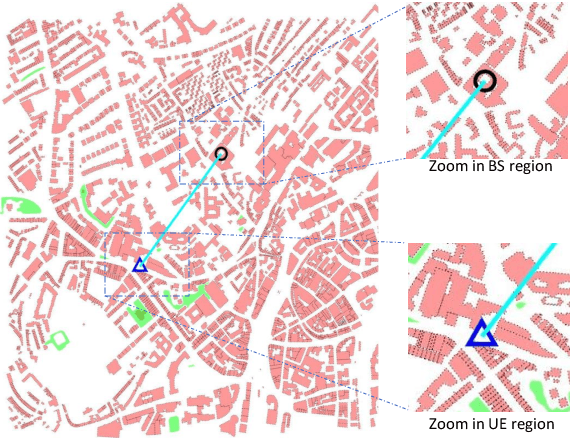
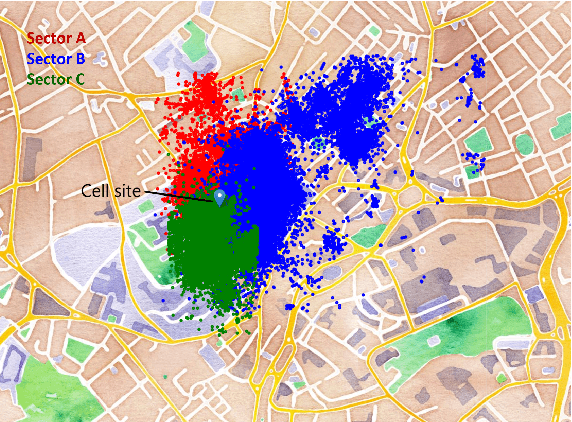
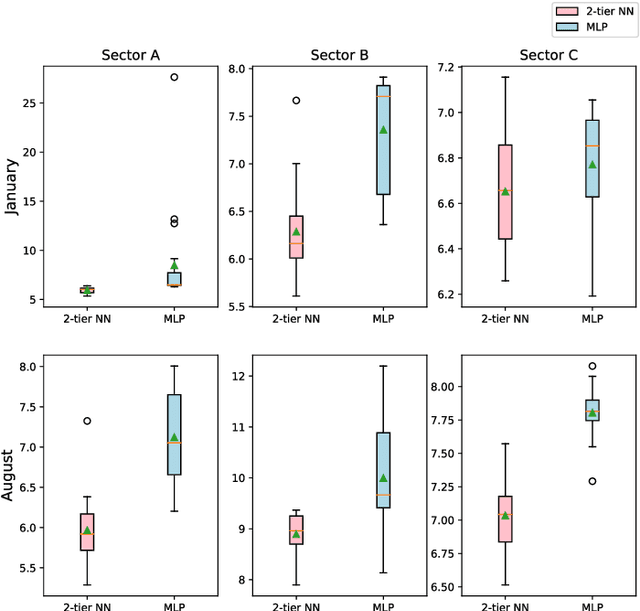
Measuring customer experience on mobile data is of utmost importance for global mobile operators. The reference signal received power (RSRP) is one of the important indicators for current mobile network management, evaluation and monitoring. Radio data gathered through the minimization of drive test (MDT), a 3GPP standard technique, is commonly used for radio network analysis. Collecting MDT data in different geographical areas is inefficient and constrained by the terrain conditions and user presence, hence is not an adequate technique for dynamic radio environments. In this paper, we study a generative model for RSRP prediction, exploiting MDT data and a digital twin (DT), and propose a data-driven, two-tier neural network (NN) model. In the first tier, environmental information related to user equipment (UE), base stations (BS) and network key performance indicators (KPI) are extracted through a variational autoencoder (VAE). The second tier is designed as a likelihood model. Here, the environmental features and real MDT data features are adopted, formulating an integrated training process. On validation, our proposed model that uses real-world data demonstrates an accuracy improvement of about 20% or more compared with the empirical model and about 10% when compared with a fully connected prediction network.
Sim2real for Reinforcement Learning Driven Next Generation Networks
Jun 08, 2022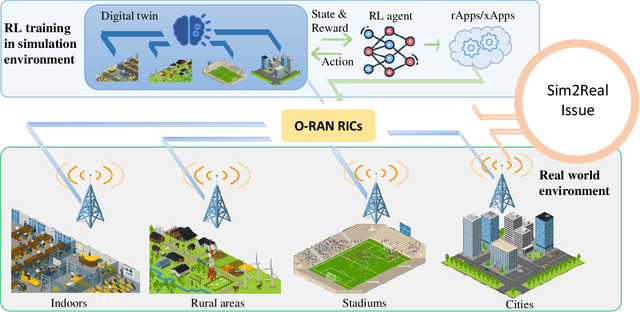
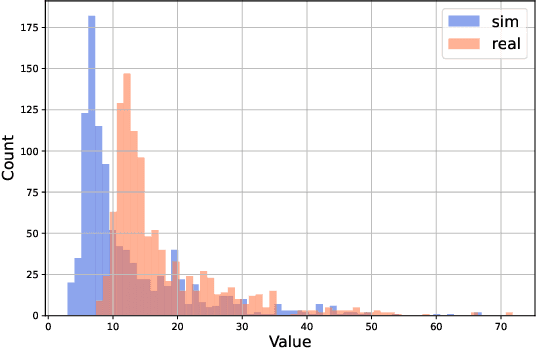
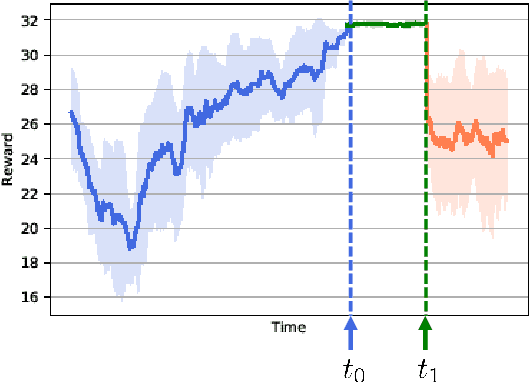

The next generation of networks will actively embrace artificial intelligence (AI) and machine learning (ML) technologies for automation networks and optimal network operation strategies. The emerging network structure represented by Open RAN (O-RAN) conforms to this trend, and the radio intelligent controller (RIC) at the centre of its specification serves as an ML applications host. Various ML models, especially Reinforcement Learning (RL) models, are regarded as the key to solving RAN-related multi-objective optimization problems. However, it should be recognized that most of the current RL successes are confined to abstract and simplified simulation environments, which may not directly translate to high performance in complex real environments. One of the main reasons is the modelling gap between the simulation and the real environment, which could make the RL agent trained by simulation ill-equipped for the real environment. This issue is termed as the sim2real gap. This article brings to the fore the sim2real challenge within the context of O-RAN. Specifically, it emphasizes the characteristics, and benefits that the digital twins (DT) could have as a place for model development and verification. Several use cases are presented to exemplify and demonstrate failure modes of the simulations trained RL model in real environments. The effectiveness of DT in assisting the development of RL algorithms is discussed. Then the current state of the art learning-based methods commonly used to overcome the sim2real challenge are presented. Finally, the development and deployment concerns for the RL applications realisation in O-RAN are discussed from the view of the potential issues like data interaction, environment bottlenecks, and algorithm design.
Wi-Fi Based Passive Human Motion Sensing for In-Home Healthcare Applications
Apr 13, 2022
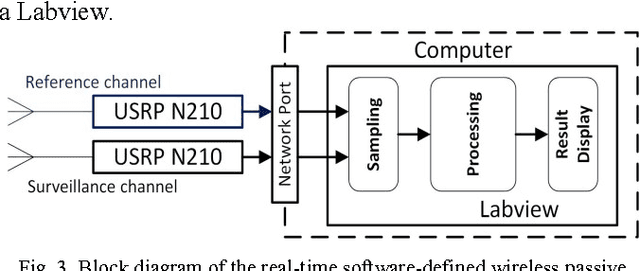
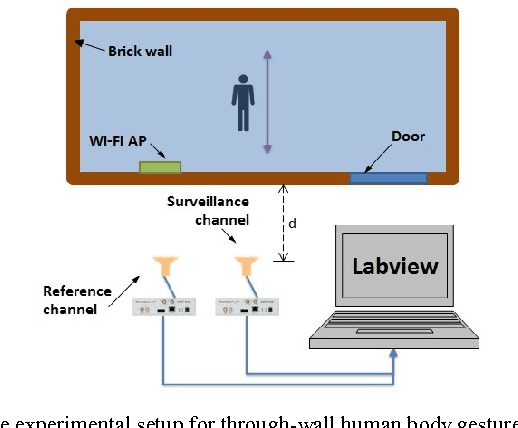
This paper introduces a Wi-Fi signal based passive wireless sensing system that has the capability to detect diverse indoor human movements, from whole body motions to limb movements and including breathing movements of the chest. The real time signal processing used for human body motion sensing and software defined radio demo system are described and verified in practical experiments scenarios, which include detection of through-wall human body movement, hand gesture or tremor, and even respiration. The experiment results offer potential for promising healthcare applications using Wi-Fi passive sensing in the home to monitor daily activities, to gather health data and detect emergency situations.
RLOps: Development Life-cycle of Reinforcement Learning Aided Open RAN
Nov 12, 2021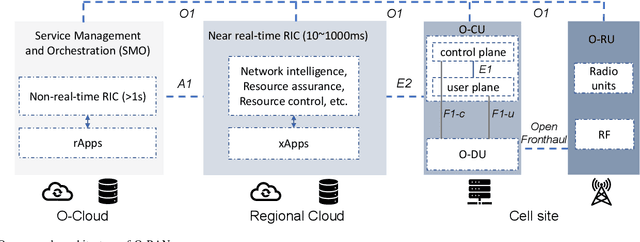
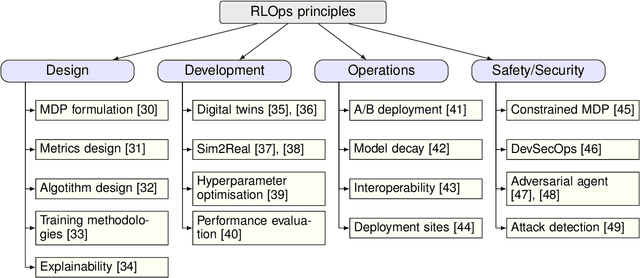
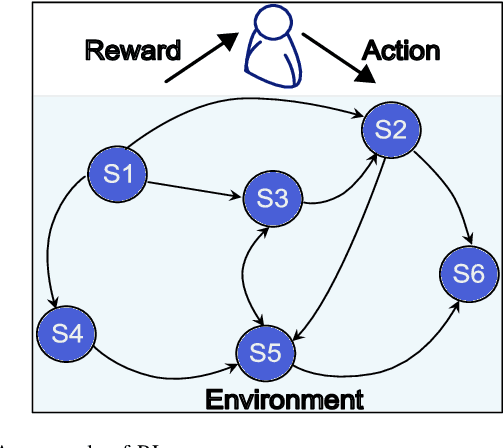
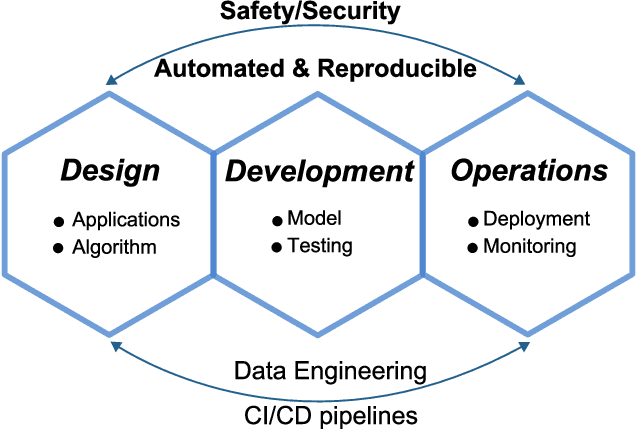
Radio access network (RAN) technologies continue to witness massive growth, with Open RAN gaining the most recent momentum. In the O-RAN specifications, the RAN intelligent controller (RIC) serves as an automation host. This article introduces principles for machine learning (ML), in particular, reinforcement learning (RL) relevant for the O-RAN stack. Furthermore, we review state-of-the-art research in wireless networks and cast it onto the RAN framework and the hierarchy of the O-RAN architecture. We provide a taxonomy of the challenges faced by ML/RL models throughout the development life-cycle: from the system specification to production deployment (data acquisition, model design, testing and management, etc.). To address the challenges, we integrate a set of existing MLOps principles with unique characteristics when RL agents are considered. This paper discusses a systematic life-cycle model development, testing and validation pipeline, termed: RLOps. We discuss all fundamental parts of RLOps, which include: model specification, development and distillation, production environment serving, operations monitoring, safety/security and data engineering platform. Based on these principles, we propose the best practices for RLOps to achieve an automated and reproducible model development process.
OPERAnet: A Multimodal Activity Recognition Dataset Acquired from Radio Frequency and Vision-based Sensors
Oct 08, 2021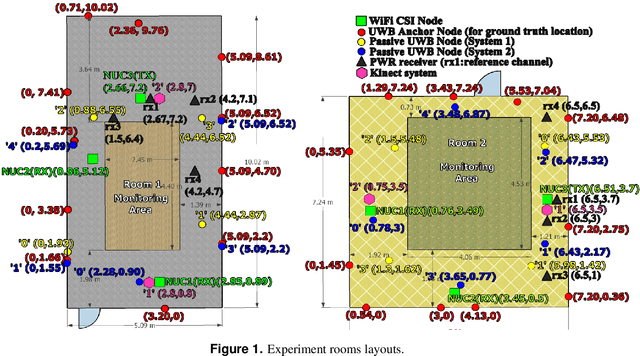
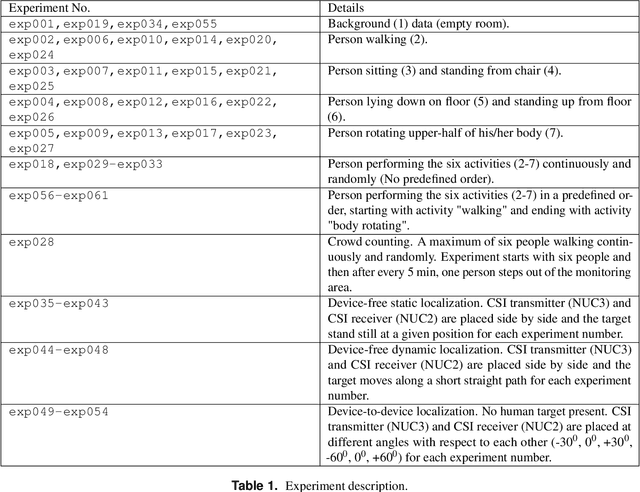
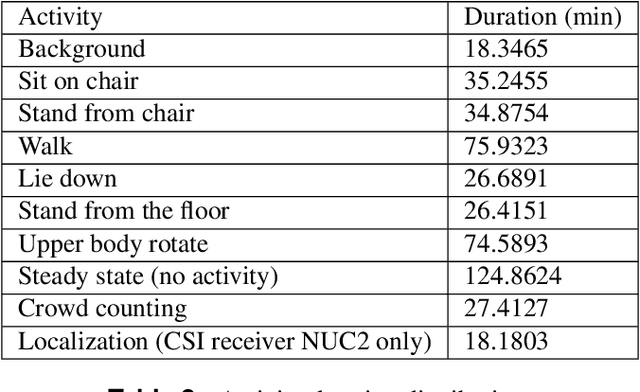
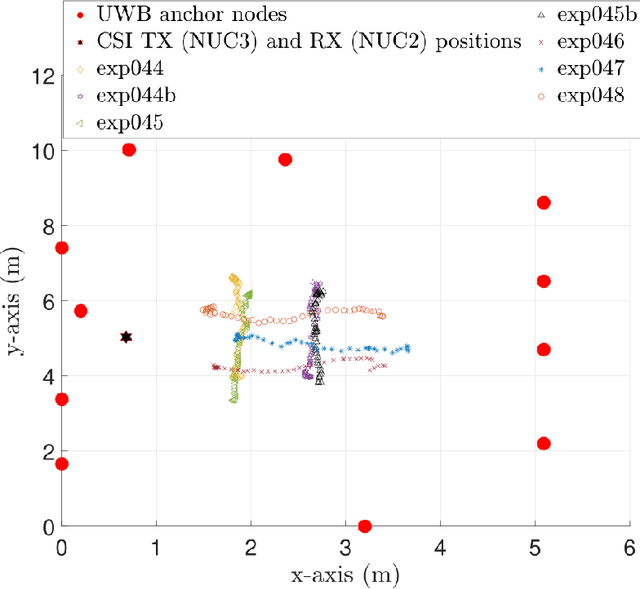
This paper presents a comprehensive dataset intended to evaluate passive Human Activity Recognition (HAR) and localization techniques with measurements obtained from synchronized Radio-Frequency (RF) devices and vision-based sensors. The dataset consists of RF data including Channel State Information (CSI) extracted from a WiFi Network Interface Card (NIC), Passive WiFi Radar (PWR) built upon a Software Defined Radio (SDR) platform, and Ultra-Wideband (UWB) signals acquired via commercial off-the-shelf hardware. It also consists of vision/Infra-red based data acquired from Kinect sensors. Approximately 8 hours of annotated measurements are provided, which are collected across two rooms from 6 participants performing 6 daily activities. This dataset can be exploited to advance WiFi and vision-based HAR, for example, using pattern recognition, skeletal representation, deep learning algorithms or other novel approaches to accurately recognize human activities. Furthermore, it can potentially be used to passively track a human in an indoor environment. Such datasets are key tools required for the development of new algorithms and methods in the context of smart homes, elderly care, and surveillance applications.
Deep Transfer Learning for WiFi Localization
Mar 08, 2021
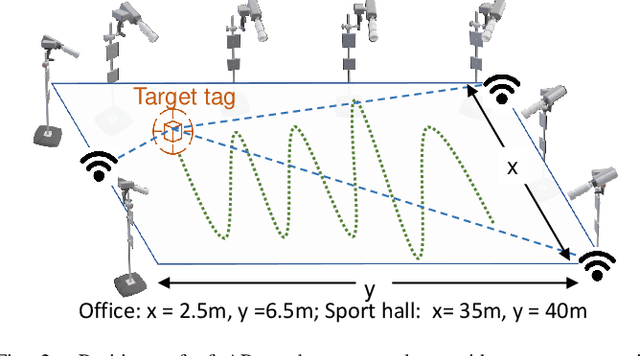
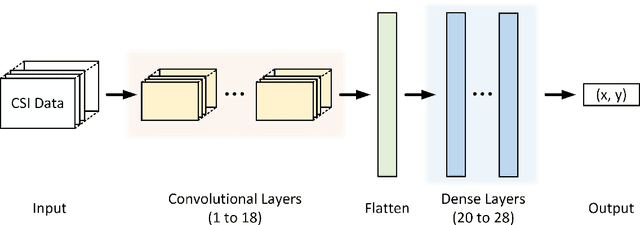
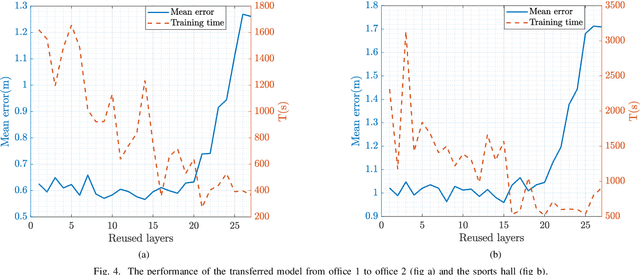
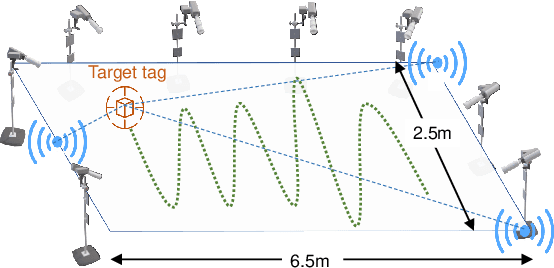
This paper studies a WiFi indoor localisation technique based on using a deep learning model and its transfer strategies. We take CSI packets collected via the WiFi standard channel sounding as the training dataset and verify the CNN model on the subsets collected in three experimental environments. We achieve a localisation accuracy of 46.55 cm in an ideal $(6.5m \times 2.5m)$ office with no obstacles, 58.30 cm in an office with obstacles, and 102.8 cm in a sports hall $(40 \times 35m)$. Then, we evaluate the transfer ability of the proposed model to different environments. The experimental results show that, for a trained localisation model, feature extraction layers can be directly transferred to other models and only the fully connected layers need to be retrained to achieve the same baseline accuracy with non-transferred base models. This can save 60% of the training parameters and reduce the training time by more than half. Finally, an ablation study of the training dataset shows that, in both office and sport hall scenarios, after reusing the feature extraction layers of the base model, only 55% of the training data is required to obtain the models' accuracy similar to the base models.
Wireless Localisation in WiFi using Novel Deep Architectures
Oct 16, 2020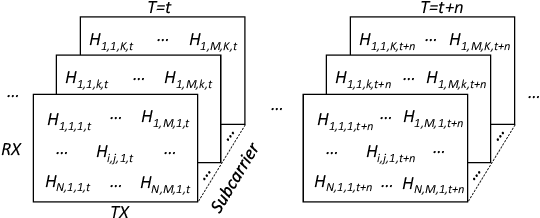
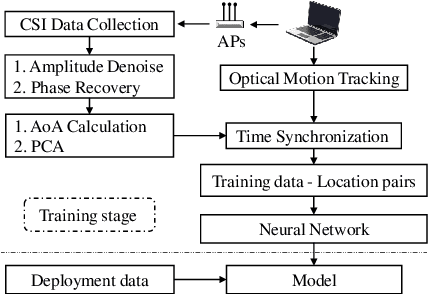
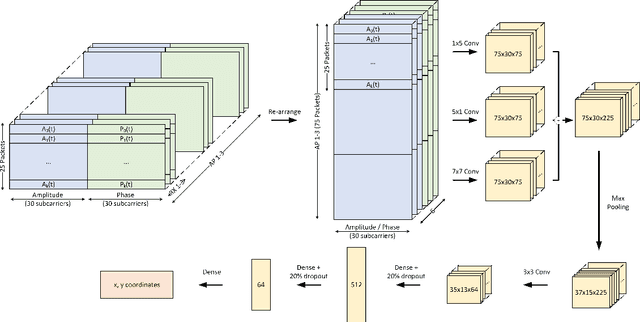
This paper studies the indoor localisation of WiFi devices based on a commodity chipset and standard channel sounding. First, we present a novel shallow neural network (SNN) in which features are extracted from the channel state information (CSI) corresponding to WiFi subcarriers received on different antennas and used to train the model. The single-layer architecture of this localisation neural network makes it lightweight and easy-to-deploy on devices with stringent constraints on computational resources. We further investigate for localisation the use of deep learning models and design novel architectures for convolutional neural network (CNN) and long-short term memory (LSTM). We extensively evaluate these localisation algorithms for continuous tracking in indoor environments. Experimental results prove that even an SNN model, after a careful handcrafted feature extraction, can achieve accurate localisation. Meanwhile, using a well-organised architecture, the neural network models can be trained directly with raw data from the CSI and localisation features can be automatically extracted to achieve accurate position estimates. We also found that the performance of neural network-based methods are directly affected by the number of anchor access points (APs) regardless of their structure. With three APs, all neural network models proposed in this paper can obtain localisation accuracy of around 0.5 metres. In addition the proposed deep NN architecture reduces the data pre-processing time by 6.5 hours compared with a shallow NN using the data collected in our testbed. In the deployment phase, the inference time is also significantly reduced to 0.1 ms per sample. We also demonstrate the generalisation capability of the proposed method by evaluating models using different target movement characteristics to the ones in which they were trained.