 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy in Multimodal Federated Human Activity Recognition
May 20, 2023



Human Activity Recognition (HAR) training data is often privacy-sensitive or held by non-cooperative entities. Federated Learning (FL) addresses such concerns by training ML models on edge clients. This work studies the impact of privacy in federated HAR at a user, environment, and sensor level. We show that the performance of FL for HAR depends on the assumed privacy level of the FL system and primarily upon the colocation of data from different sensors. By avoiding data sharing and assuming privacy at the human or environment level, as prior works have done, the accuracy decreases by 5-7%. However, extending this to the modality level and strictly separating sensor data between multiple clients may decrease the accuracy by 19-42%. As this form of privacy is necessary for the ethical utilisation of passive sensing methods in HAR, we implement a system where clients mutually train both a general FL model and a group-level one per modality. Our evaluation shows that this method leads to only a 7-13% decrease in accuracy, making it possible to build HAR systems with diverse hardware.
Streamlining Multimodal Data Fusion in Wireless Communication and Sensor Networks
Feb 24, 2023This paper presents a novel approach for multimodal data fusion based on the Vector-Quantized Variational Autoencoder (VQVAE) architecture. The proposed method is simple yet effective in achieving excellent reconstruction performance on paired MNIST-SVHN data and WiFi spectrogram data. Additionally, the multimodal VQVAE model is extended to the 5G communication scenario, where an end-to-end Channel State Information (CSI) feedback system is implemented to compress data transmitted between the base-station (eNodeB) and User Equipment (UE), without significant loss of performance. The proposed model learns a discriminative compressed feature space for various types of input data (CSI, spectrograms, natural images, etc), making it a suitable solution for applications with limited computational resources.
Multimodal sensor fusion in the latent representation space
Aug 03, 2022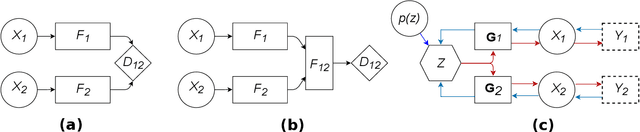
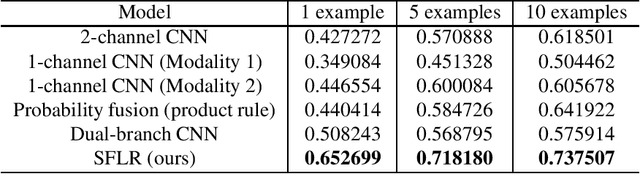
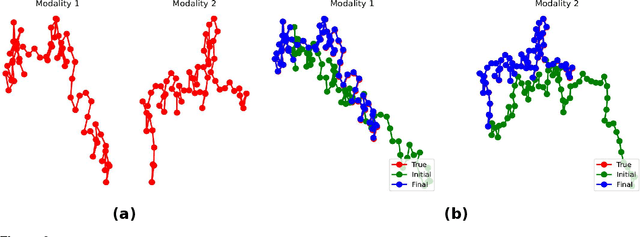
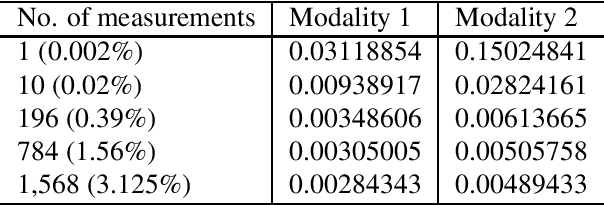
A new method for multimodal sensor fusion is introduced. The technique relies on a two-stage process. In the first stage, a multimodal generative model is constructed from unlabelled training data. In the second stage, the generative model serves as a reconstruction prior and the search manifold for the sensor fusion tasks. The method also handles cases where observations are accessed only via subsampling i.e. compressed sensing. We demonstrate the effectiveness and excellent performance on a range of multimodal fusion experiments such as multisensory classification, denoising, and recovery from subsampled observations.
Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection
Dec 24, 2021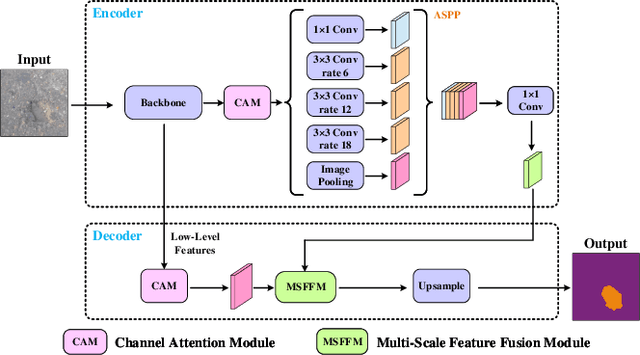
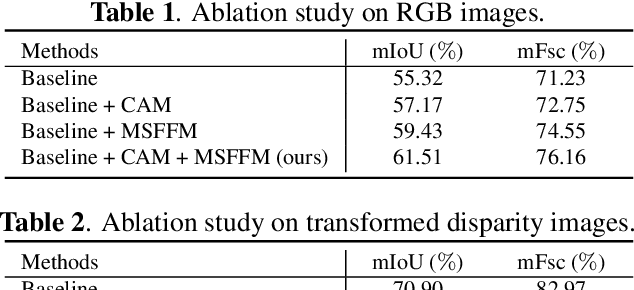
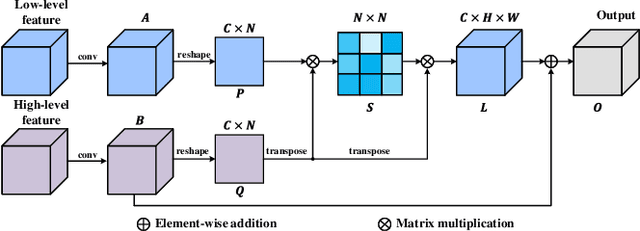
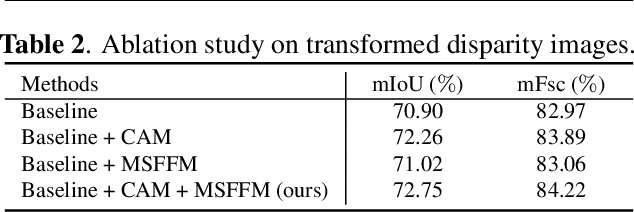
This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.
OPERAnet: A Multimodal Activity Recognition Dataset Acquired from Radio Frequency and Vision-based Sensors
Oct 08, 2021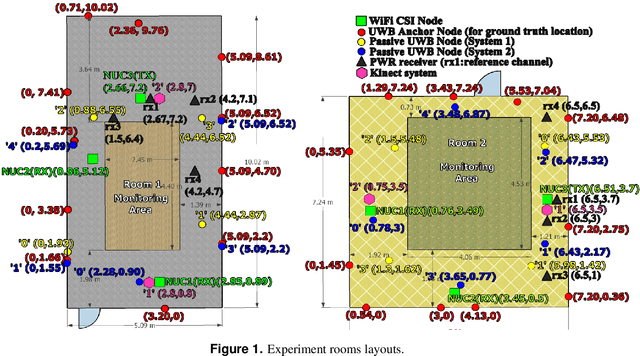
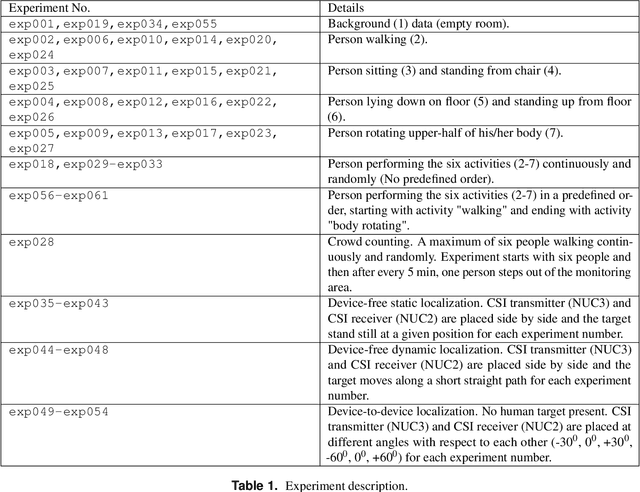
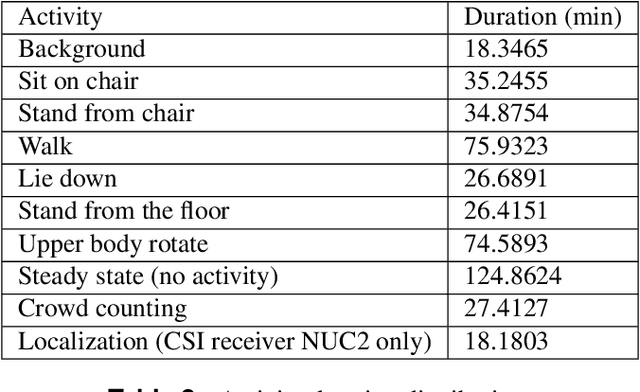
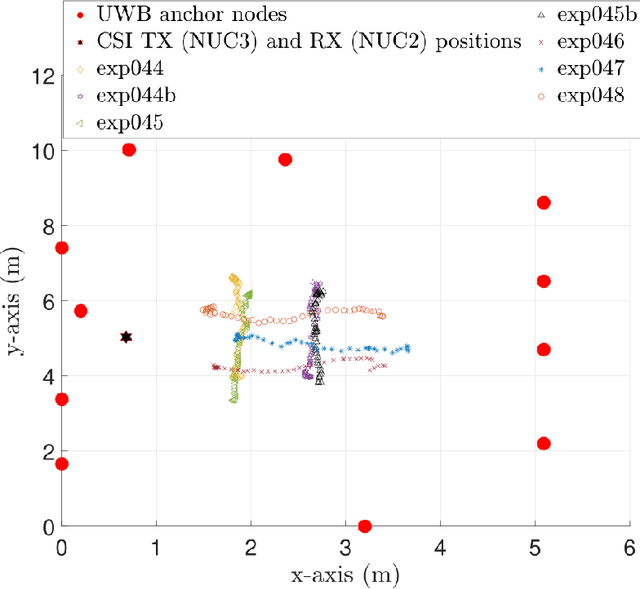
This paper presents a comprehensive dataset intended to evaluate passive Human Activity Recognition (HAR) and localization techniques with measurements obtained from synchronized Radio-Frequency (RF) devices and vision-based sensors. The dataset consists of RF data including Channel State Information (CSI) extracted from a WiFi Network Interface Card (NIC), Passive WiFi Radar (PWR) built upon a Software Defined Radio (SDR) platform, and Ultra-Wideband (UWB) signals acquired via commercial off-the-shelf hardware. It also consists of vision/Infra-red based data acquired from Kinect sensors. Approximately 8 hours of annotated measurements are provided, which are collected across two rooms from 6 participants performing 6 daily activities. This dataset can be exploited to advance WiFi and vision-based HAR, for example, using pattern recognition, skeletal representation, deep learning algorithms or other novel approaches to accurately recognize human activities. Furthermore, it can potentially be used to passively track a human in an indoor environment. Such datasets are key tools required for the development of new algorithms and methods in the context of smart homes, elderly care, and surveillance applications.
Self-Supervised WiFi-Based Activity Recognition
Apr 19, 2021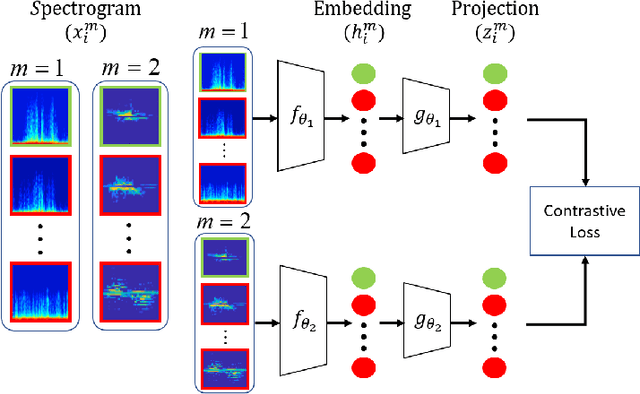

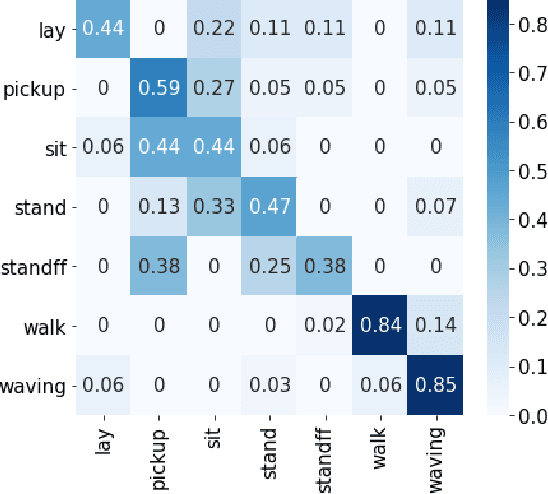
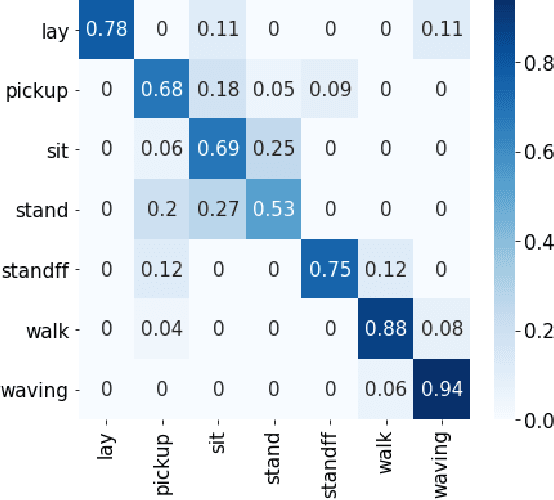
Traditional approaches to activity recognition involve the use of wearable sensors or cameras in order to recognise human activities. In this work, we extract fine-grained physical layer information from WiFi devices for the purpose of passive activity recognition in indoor environments. While such data is ubiquitous, few approaches are designed to utilise large amounts of unlabelled WiFi data. We propose the use of self-supervised contrastive learning to improve activity recognition performance when using multiple views of the transmitted WiFi signal captured by different synchronised receivers. We conduct experiments where the transmitters and receivers are arranged in different physical layouts so as to cover both Line-of-Sight (LoS) and non LoS (NLoS) conditions. We compare the proposed contrastive learning system with non-contrastive systems and observe a 17.7% increase in macro averaged F1 score on the task of WiFi based activity recognition, as well as significant improvements in one- and few-shot learning scenarios.
ATG-PVD: Ticketing Parking Violations on A Drone
Aug 21, 2020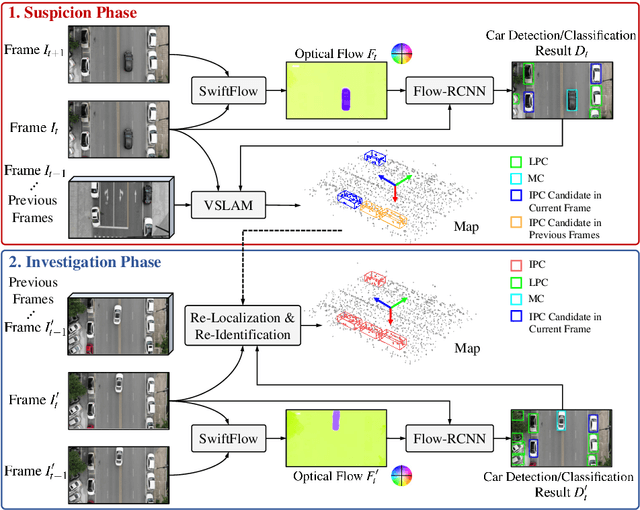
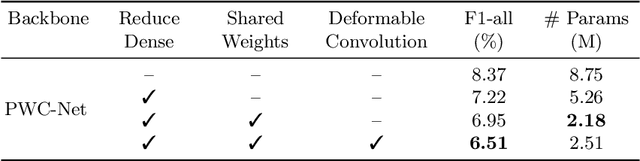
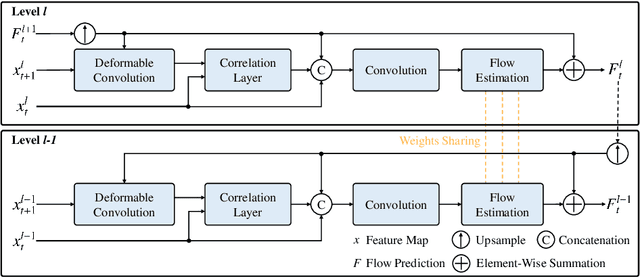
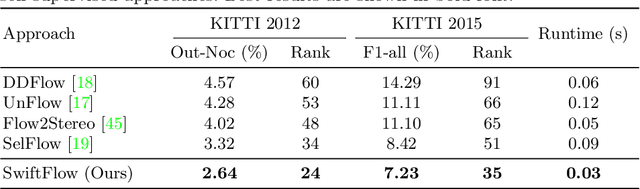
In this paper, we introduce a novel suspect-and-investigate framework, which can be easily embedded in a drone for automated parking violation detection (PVD). Our proposed framework consists of: 1) SwiftFlow, an efficient and accurate convolutional neural network (CNN) for unsupervised optical flow estimation; 2) Flow-RCNN, a flow-guided CNN for car detection and classification; and 3) an illegally parked car (IPC) candidate investigation module developed based on visual SLAM. The proposed framework was successfully embedded in a drone from ATG Robotics. The experimental results demonstrate that, firstly, our proposed SwiftFlow outperforms all other state-of-the-art unsupervised optical flow estimation approaches in terms of both speed and accuracy; secondly, IPC candidates can be effectively and efficiently detected by our proposed Flow-RCNN, with a better performance than our baseline network, Faster-RCNN; finally, the actual IPCs can be successfully verified by our investigation module after drone re-localization.
We Learn Better Road Pothole Detection: from Attention Aggregation to Adversarial Domain Adaptation
Aug 16, 2020
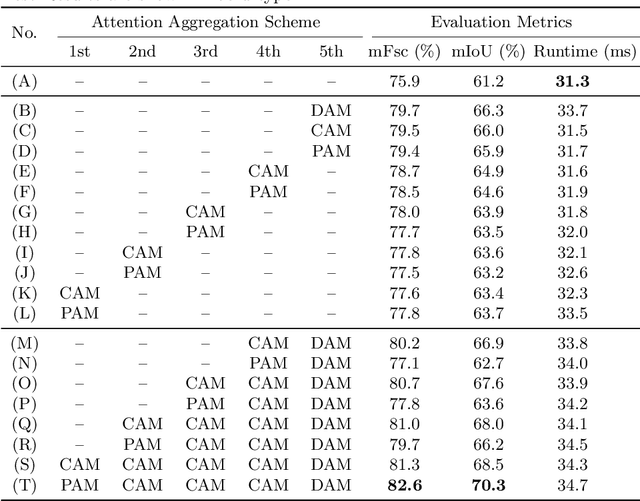
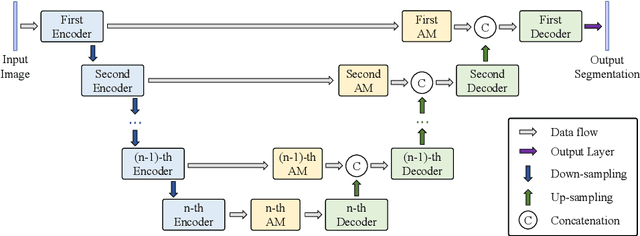
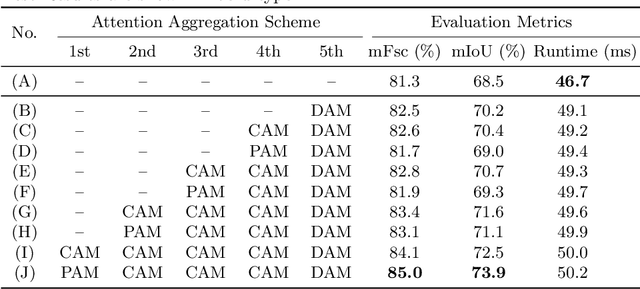
Manual visual inspection performed by certified inspectors is still the main form of road pothole detection. This process is, however, not only tedious, time-consuming and costly, but also dangerous for the inspectors. Furthermore, the road pothole detection results are always subjective, because they depend entirely on the individual experience. Our recently introduced disparity (or inverse depth) transformation algorithm allows better discrimination between damaged and undamaged road areas, and it can be easily deployed to any semantic segmentation network for better road pothole detection results. To boost the performance, we propose a novel attention aggregation (AA) framework, which takes the advantages of different types of attention modules. In addition, we develop an effective training set augmentation technique based on adversarial domain adaptation, where the synthetic road RGB images and transformed road disparity (or inverse depth) images are generated to enhance the training of semantic segmentation networks. The experimental results demonstrate that, firstly, the transformed disparity (or inverse depth) images become more informative; secondly, AA-UNet and AA-RTFNet, our best performing implementations, respectively outperform all other state-of-the-art single-modal and data-fusion networks for road pothole detection; and finally, the training set augmentation technique based on adversarial domain adaptation not only improves the accuracy of the state-of-the-art semantic segmentation networks, but also accelerates their convergence.