Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal sensor fusion in the latent representation space
Paper and Code
Aug 03, 2022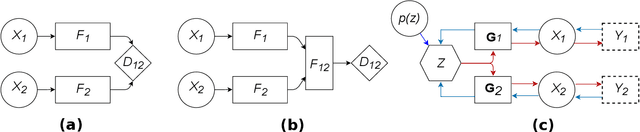
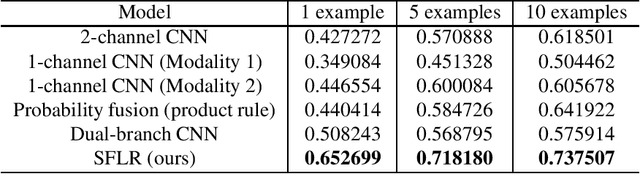
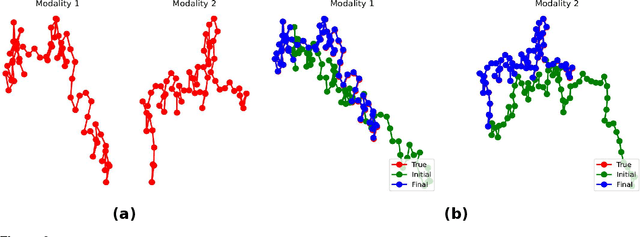
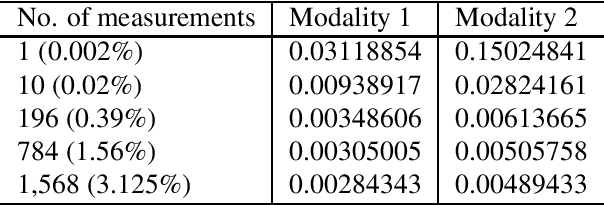
A new method for multimodal sensor fusion is introduced. The technique relies on a two-stage process. In the first stage, a multimodal generative model is constructed from unlabelled training data. In the second stage, the generative model serves as a reconstruction prior and the search manifold for the sensor fusion tasks. The method also handles cases where observations are accessed only via subsampling i.e. compressed sensing. We demonstrate the effectiveness and excellent performance on a range of multimodal fusion experiments such as multisensory classification, denoising, and recovery from subsampled observations.
* Under review for Nature Scientific Reports
View paper on