 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Pretrained Speech Models for Automatic Speech Assessment of Voice Disorders
Jun 29, 2024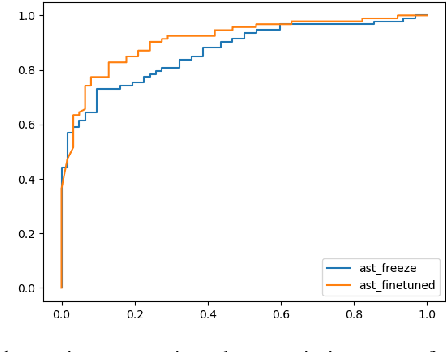
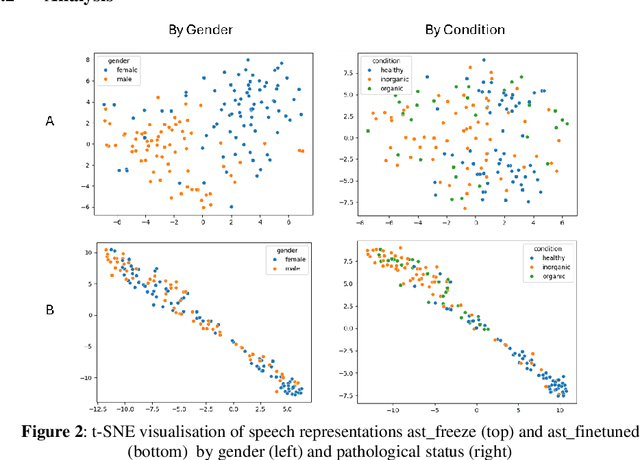
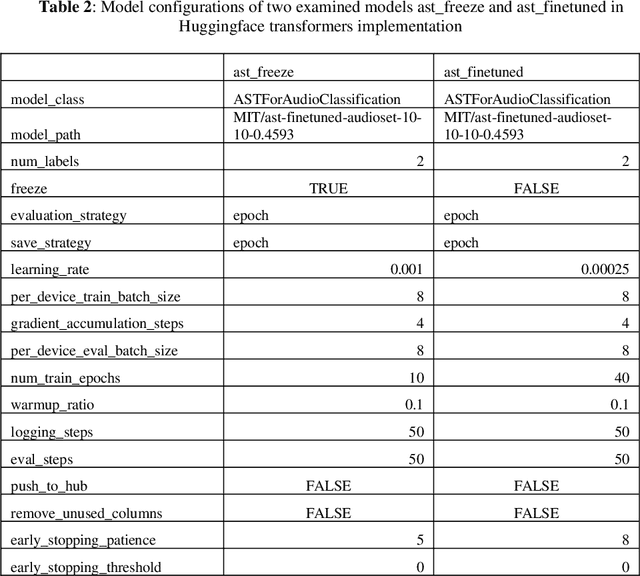
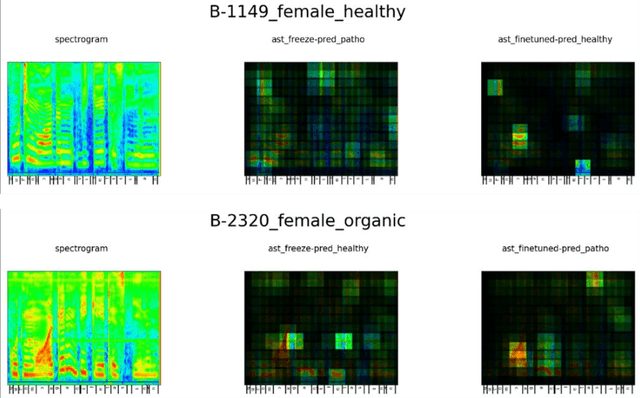
Speech contains information that is clinically relevant to some diseases, which has the potential to be used for health assessment. Recent work shows an interest in applying deep learning algorithms, especially pretrained large speech models to the applications of Automatic Speech Assessment. One question that has not been explored is how these models output the results based on their inputs. In this work, we train and compare two configurations of Audio Spectrogram Transformer in the context of Voice Disorder Detection and apply the attention rollout method to produce model relevance maps, the computed relevance of the spectrogram regions when the model makes predictions. We use these maps to analyse how models make predictions in different conditions and to show that the spread of attention is reduced as a model is finetuned, and the model attention is concentrated on specific phoneme regions.
Self-Supervised WiFi-Based Activity Recognition
Apr 19, 2021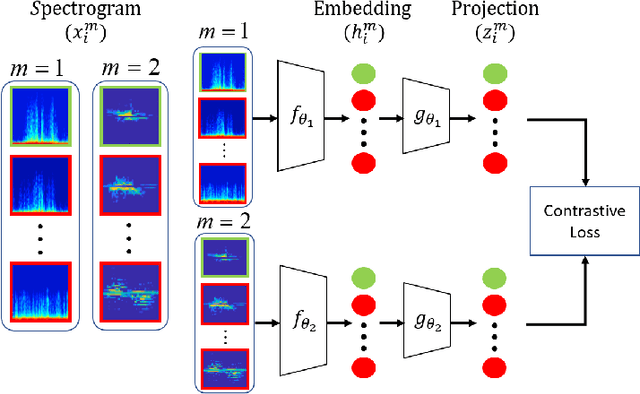

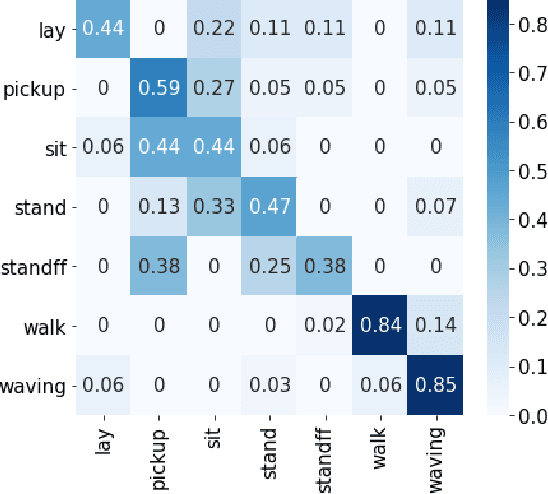
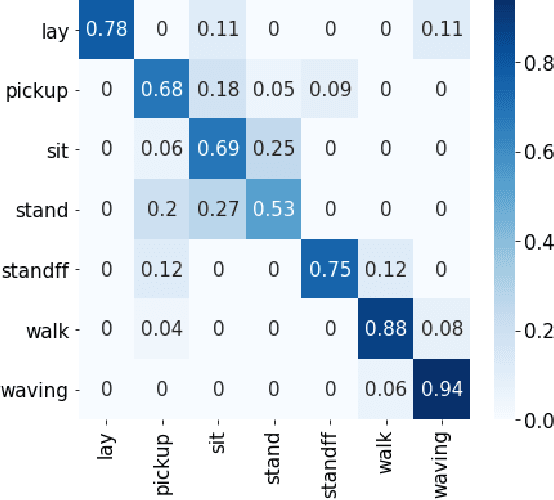
Traditional approaches to activity recognition involve the use of wearable sensors or cameras in order to recognise human activities. In this work, we extract fine-grained physical layer information from WiFi devices for the purpose of passive activity recognition in indoor environments. While such data is ubiquitous, few approaches are designed to utilise large amounts of unlabelled WiFi data. We propose the use of self-supervised contrastive learning to improve activity recognition performance when using multiple views of the transmitted WiFi signal captured by different synchronised receivers. We conduct experiments where the transmitters and receivers are arranged in different physical layouts so as to cover both Line-of-Sight (LoS) and non LoS (NLoS) conditions. We compare the proposed contrastive learning system with non-contrastive systems and observe a 17.7% increase in macro averaged F1 score on the task of WiFi based activity recognition, as well as significant improvements in one- and few-shot learning scenarios.