 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based explanations of Segmentation and Detection models in Natural Disaster Management
Mar 24, 2026Deep learning models for flood and wildfire segmentation and object detection enable precise, real-time disaster localization when deployed on embedded drone platforms. However, in natural disaster management, the lack of transparency in their decision-making process hinders human trust required for emergency response. To address this, we present an explainability framework for understanding flood segmentation and car detection predictions on the widely used PIDNet and YOLO architectures. More specifically, we introduce a novel redistribution strategy that extends Layer-wise Relevance Propagation (LRP) explanations for sigmoid-gated element-wise fusion layers. This extension allows LRP relevances to flow through the fusion modules of PIDNet, covering the entire computation graph back to the input image. Furthermore, we apply Prototypical Concept-based Explanations (PCX) to provide both local and global explanations at the concept level, revealing which learned features drive the segmentation and detection of specific disaster semantic classes. Experiments on a publicly available flood dataset show that our framework provides reliable and interpretable explanations while maintaining near real-time inference capabilities, rendering it suitable for deployment on resource-constrained platforms, such as Unmanned Aerial Vehicles (UAVs).
Federated Unsupervised Semantic Segmentation
May 29, 2025This work explores the application of Federated Learning (FL) in Unsupervised Semantic image Segmentation (USS). Recent USS methods extract pixel-level features using frozen visual foundation models and refine them through self-supervised objectives that encourage semantic grouping. These features are then grouped to semantic clusters to produce segmentation masks. Extending these ideas to federated settings requires feature representation and cluster centroid alignment across distributed clients -- an inherently difficult task under heterogeneous data distributions in the absence of supervision. To address this, we propose FUSS Federated Unsupervised image Semantic Segmentation) which is, to our knowledge, the first framework to enable fully decentralized, label-free semantic segmentation training. FUSS introduces novel federation strategies that promote global consistency in feature and prototype space, jointly optimizing local segmentation heads and shared semantic centroids. Experiments on both benchmark and real-world datasets, including binary and multi-class segmentation tasks, show that FUSS consistently outperforms local-only client trainings as well as extensions of classical FL algorithms under varying client data distributions. To support reproducibility, full code will be released upon manuscript acceptance.
FCL-ViT: Task-Aware Attention Tuning for Continual Learning
Dec 03, 2024
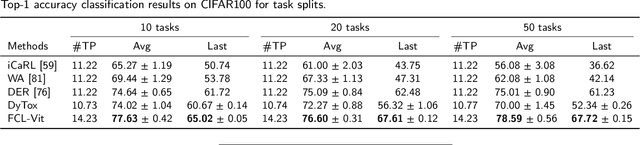
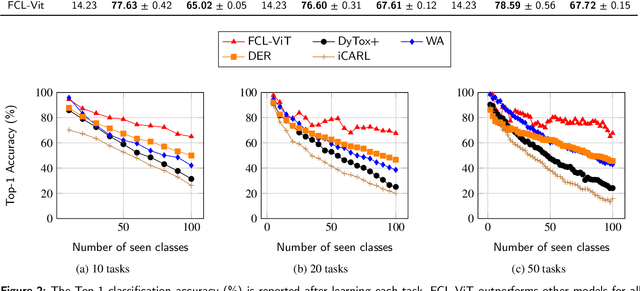

Continual Learning (CL) involves adapting the prior Deep Neural Network (DNN) knowledge to new tasks, without forgetting the old ones. However, modern CL techniques focus on provisioning memory capabilities to existing DNN models rather than designing new ones that are able to adapt according to the task at hand. This paper presents the novel Feedback Continual Learning Vision Transformer (FCL-ViT) that uses a feedback mechanism to generate real-time dynamic attention features tailored to the current task. The FCL-ViT operates in two Phases. In phase 1, the generic image features are produced and determine where the Transformer should attend on the current image. In phase 2, task-specific image features are generated that leverage dynamic attention. To this end, Tunable self-Attention Blocks (TABs) and Task Specific Blocks (TSBs) are introduced that operate in both phases and are responsible for tuning the TABs attention, respectively. The FCL-ViT surpasses state-of-the-art performance on Continual Learning compared to benchmark methods, while retaining a small number of trainable DNN parameters.
These Maps Are Made by Propagation: Adapting Deep Stereo Networks to Road Scenarios with Decisive Disparity Diffusion
Nov 06, 2024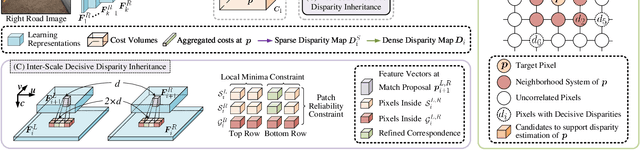
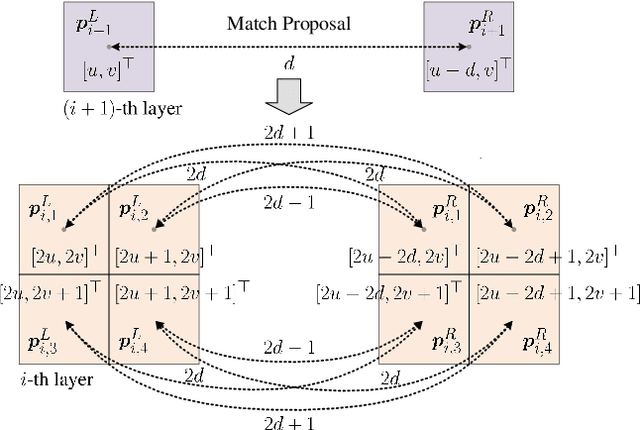
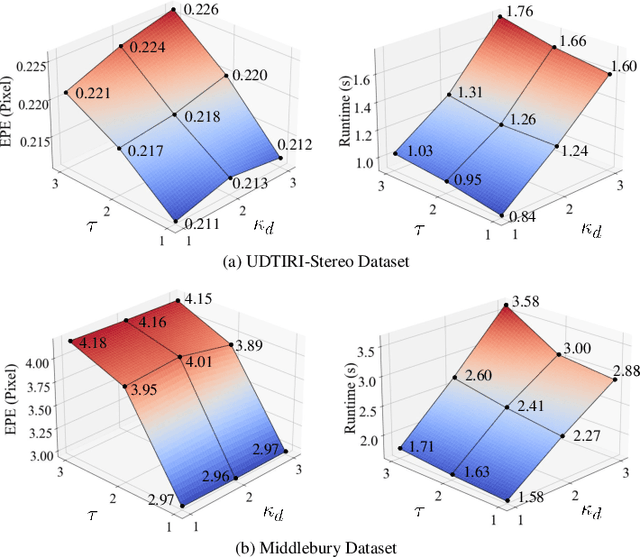
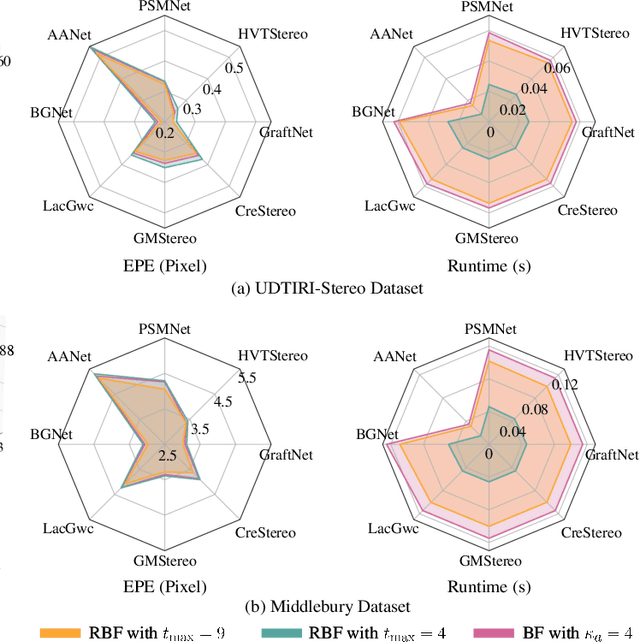
Stereo matching has emerged as a cost-effective solution for road surface 3D reconstruction, garnering significant attention towards improving both computational efficiency and accuracy. This article introduces decisive disparity diffusion (D3Stereo), marking the first exploration of dense deep feature matching that adapts pre-trained deep convolutional neural networks (DCNNs) to previously unseen road scenarios. A pyramid of cost volumes is initially created using various levels of learned representations. Subsequently, a novel recursive bilateral filtering algorithm is employed to aggregate these costs. A key innovation of D3Stereo lies in its alternating decisive disparity diffusion strategy, wherein intra-scale diffusion is employed to complete sparse disparity images, while inter-scale inheritance provides valuable prior information for higher resolutions. Extensive experiments conducted on our created UDTIRI-Stereo and Stereo-Road datasets underscore the effectiveness of D3Stereo strategy in adapting pre-trained DCNNs and its superior performance compared to all other explicit programming-based algorithms designed specifically for road surface 3D reconstruction. Additional experiments conducted on the Middlebury dataset with backbone DCNNs pre-trained on the ImageNet database further validate the versatility of D3Stereo strategy in tackling general stereo matching problems.
Gesture-Controlled Aerial Robot Formation for Human-Swarm Interaction in Safety Monitoring Applications
Mar 22, 2024
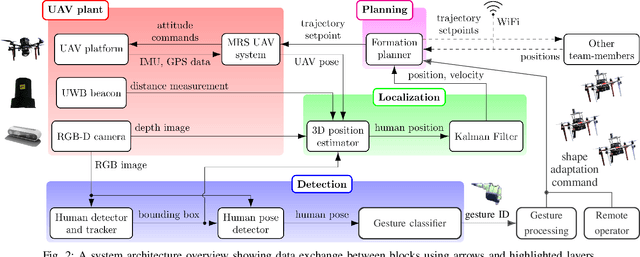
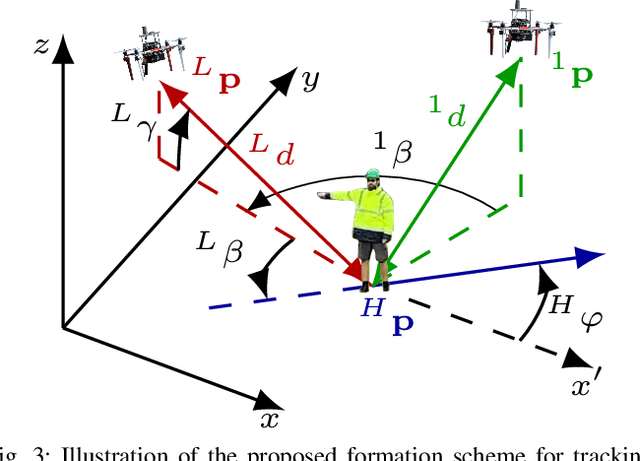
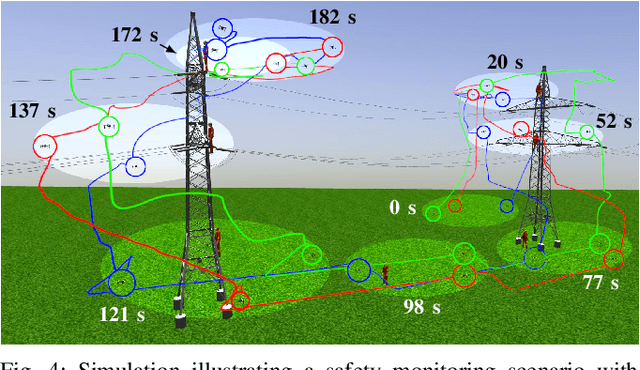
This paper presents a formation control approach for contactless gesture-based Human-Swarm Interaction (HSI) between a team of multi-rotor Unmanned Aerial Vehicles (UAVs) and a human worker. The approach is intended for monitoring the safety of human workers, especially those working at heights. In the proposed dynamic formation scheme, one UAV acts as the leader of the formation and is equipped with sensors for human worker detection and gesture recognition. The follower UAVs maintain a predetermined formation relative to the worker's position, thereby providing additional perspectives of the monitored scene. Hand gestures allow the human worker to specify movements and action commands for the UAV team and initiate other mission-related commands without the need for an additional communication channel or specific markers. Together with a novel unified human detection and tracking algorithm, human pose estimation approach and gesture detection pipeline, the proposed approach forms a first instance of an HSI system incorporating all these modules onboard real-world UAVs. Simulations and field experiments with three UAVs and a human worker in a mock-up scenario showcase the effectiveness and responsiveness of the proposed approach.
LIX: Implicitly Infusing Spatial Geometric Prior Knowledge into Visual Semantic Segmentation for Autonomous Driving
Mar 13, 2024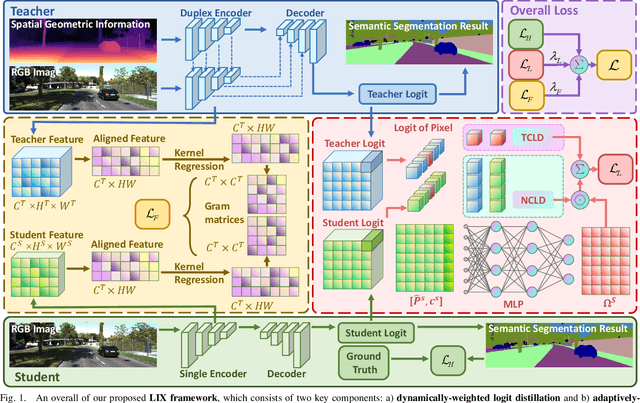
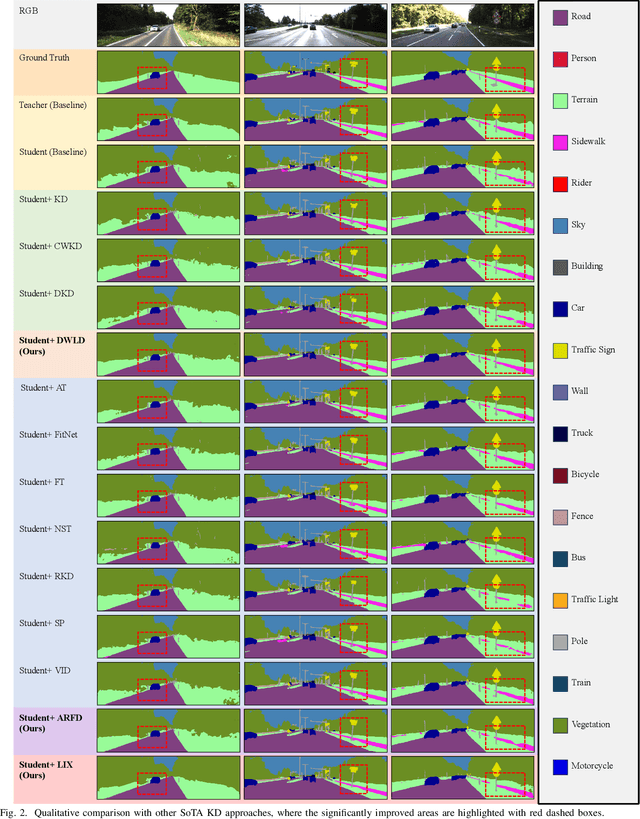
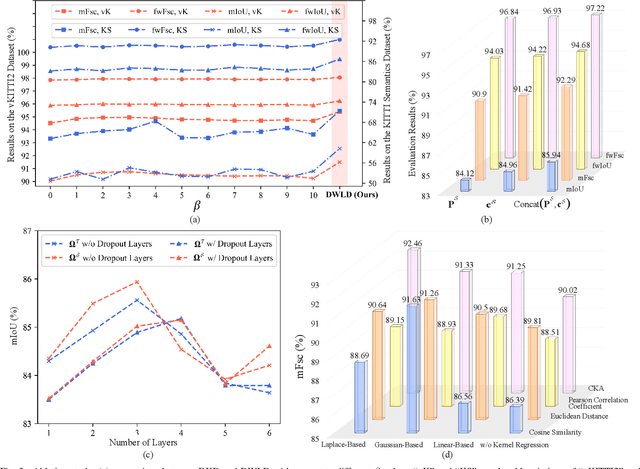
Despite the impressive performance achieved by data-fusion networks with duplex encoders for visual semantic segmentation, they become ineffective when spatial geometric data are not available. Implicitly infusing the spatial geometric prior knowledge acquired by a duplex-encoder teacher model into a single-encoder student model is a practical, albeit less explored research avenue. This paper delves into this topic and resorts to knowledge distillation approaches to address this problem. We introduce the Learning to Infuse "X" (LIX) framework, with novel contributions in both logit distillation and feature distillation aspects. We present a mathematical proof that underscores the limitation of using a single fixed weight in decoupled knowledge distillation and introduce a logit-wise dynamic weight controller as a solution to this issue. Furthermore, we develop an adaptively-recalibrated feature distillation algorithm, including two technical novelties: feature recalibration via kernel regression and in-depth feature consistency quantification via centered kernel alignment. Extensive experiments conducted with intermediate-fusion and late-fusion networks across various public datasets provide both quantitative and qualitative evaluations, demonstrating the superior performance of our LIX framework when compared to other state-of-the-art approaches.
SNE-RoadSegV2: Advancing Heterogeneous Feature Fusion and Fallibility Awareness for Freespace Detection
Feb 29, 2024



Feature-fusion networks with duplex encoders have proven to be an effective technique to solve the freespace detection problem. However, despite the compelling results achieved by previous research efforts, the exploration of adequate and discriminative heterogeneous feature fusion, as well as the development of fallibility-aware loss functions remains relatively scarce. This paper makes several significant contributions to address these limitations: (1) It presents a novel heterogeneous feature fusion block, comprising a holistic attention module, a heterogeneous feature contrast descriptor, and an affinity-weighted feature recalibrator, enabling a more in-depth exploitation of the inherent characteristics of the extracted features, (2) it incorporates both inter-scale and intra-scale skip connections into the decoder architecture while eliminating redundant ones, leading to both improved accuracy and computational efficiency, and (3) it introduces two fallibility-aware loss functions that separately focus on semantic-transition and depth-inconsistent regions, collectively contributing to greater supervision during model training. Our proposed heterogeneous feature fusion network (SNE-RoadSegV2), which incorporates all these innovative components, demonstrates superior performance in comparison to all other freespace detection algorithms across multiple public datasets. Notably, it ranks the 1st on the official KITTI Road benchmark.
AERIAL-CORE: AI-Powered Aerial Robots for Inspection and Maintenance of Electrical Power Infrastructures
Jan 04, 2024Large-scale infrastructures are prone to deterioration due to age, environmental influences, and heavy usage. Ensuring their safety through regular inspections and maintenance is crucial to prevent incidents that can significantly affect public safety and the environment. This is especially pertinent in the context of electrical power networks, which, while essential for energy provision, can also be sources of forest fires. Intelligent drones have the potential to revolutionize inspection and maintenance, eliminating the risks for human operators, increasing productivity, reducing inspection time, and improving data collection quality. However, most of the current methods and technologies in aerial robotics have been trialed primarily in indoor testbeds or outdoor settings under strictly controlled conditions, always within the line of sight of human operators. Additionally, these methods and technologies have typically been evaluated in isolation, lacking comprehensive integration. This paper introduces the first autonomous system that combines various innovative aerial robots. This system is designed for extended-range inspections beyond the visual line of sight, features aerial manipulators for maintenance tasks, and includes support mechanisms for human operators working at elevated heights. The paper further discusses the successful validation of this system on numerous electrical power lines, with aerial robots executing flights over 10 kilometers away from their ground control stations.
Graph Attention Layer Evolves Semantic Segmentation for Road Pothole Detection: A Benchmark and Algorithms
Sep 06, 2021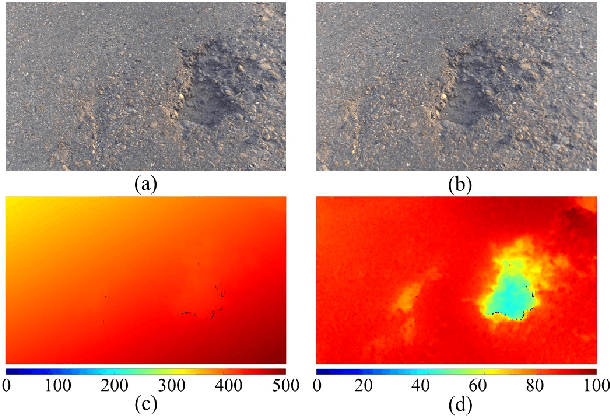
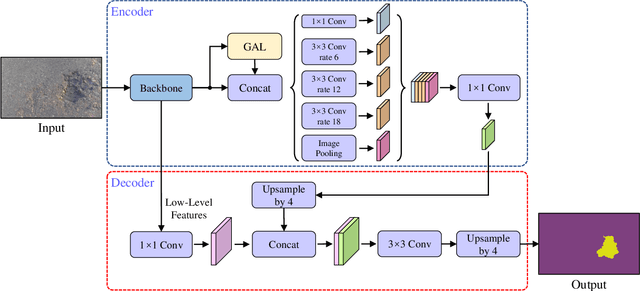
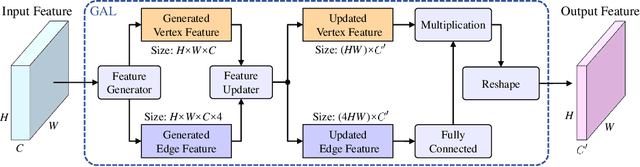
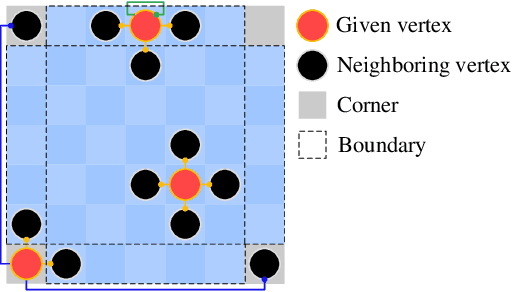
Existing road pothole detection approaches can be classified as computer vision-based or machine learning-based. The former approaches typically employ 2-D image analysis/understanding or 3-D point cloud modeling and segmentation algorithms to detect road potholes from vision sensor data. The latter approaches generally address road pothole detection using convolutional neural networks (CNNs) in an end-to-end manner. However, road potholes are not necessarily ubiquitous and it is challenging to prepare a large well-annotated dataset for CNN training. In this regard, while computer vision-based methods were the mainstream research trend in the past decade, machine learning-based methods were merely discussed. Recently, we published the first stereo vision-based road pothole detection dataset and a novel disparity transformation algorithm, whereby the damaged and undamaged road areas can be highly distinguished. However, there are no benchmarks currently available for state-of-the-art (SoTA) CNNs trained using either disparity images or transformed disparity images. Therefore, in this paper, we first discuss the SoTA CNNs designed for semantic segmentation and evaluate their performance for road pothole detection with extensive experiments. Additionally, inspired by graph neural network (GNN), we propose a novel CNN layer, referred to as graph attention layer (GAL), which can be easily deployed in any existing CNN to optimize image feature representations for semantic segmentation. Our experiments compare GAL-DeepLabv3+, our best-performing implementation, with nine SoTA CNNs on three modalities of training data: RGB images, disparity images, and transformed disparity images. The experimental results suggest that our proposed GAL-DeepLabv3+ achieves the best overall pothole detection accuracy on all training data modalities.
Rethinking Road Surface 3D Reconstruction and Pothole Detection: From Perspective Transformation to Disparity Map Segmentation
Dec 31, 2020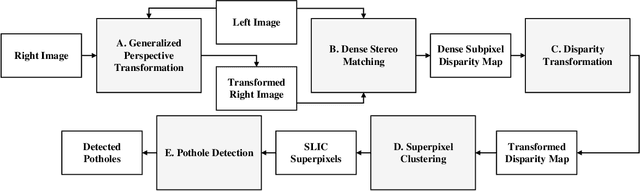

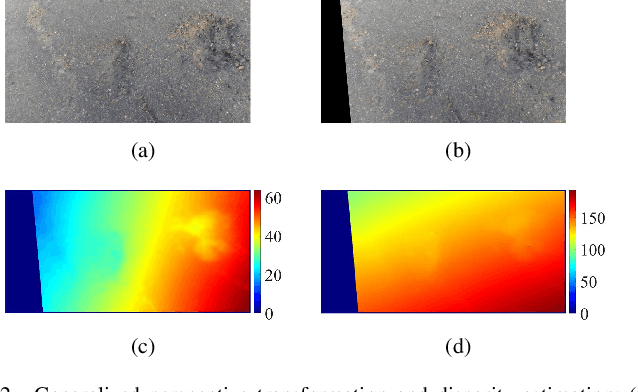
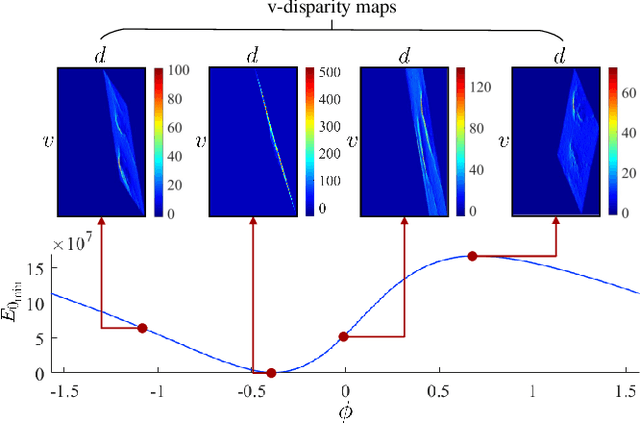
Potholes are one of the most common forms of road damage, which can severely affect driving comfort, road safety and vehicle condition. Pothole detection is typically performed by either structural engineers or certified inspectors. This task is, however, not only hazardous for the personnel but also extremely time-consuming. This paper presents an efficient pothole detection algorithm based on road disparity map estimation and segmentation. We first generalize the perspective transformation by incorporating the stereo rig roll angle. The road disparities are then estimated using semi-global matching. A disparity map transformation algorithm is then performed to better distinguish the damaged road areas. Finally, we utilize simple linear iterative clustering to group the transformed disparities into a collection of superpixels. The potholes are then detected by finding the superpixels, whose values are lower than an adaptively determined threshold. The proposed algorithm is implemented on an NVIDIA RTX 2080 Ti GPU in CUDA. The experiments demonstrate the accuracy and efficiency of our proposed road pothole detection algorithm, where an accuracy of 99.6% and an F-score of 89.4% are achieved.