 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCL-ViT: Task-Aware Attention Tuning for Continual Learning
Dec 03, 2024
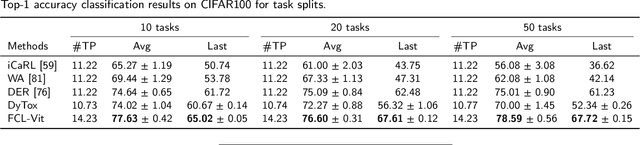
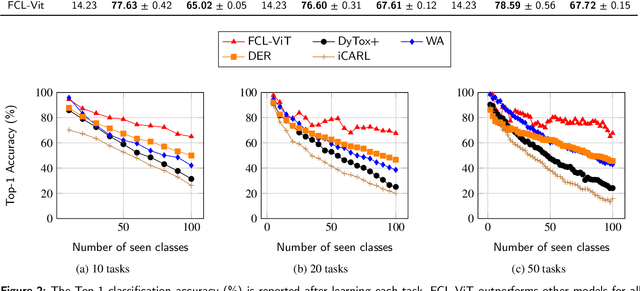

Continual Learning (CL) involves adapting the prior Deep Neural Network (DNN) knowledge to new tasks, without forgetting the old ones. However, modern CL techniques focus on provisioning memory capabilities to existing DNN models rather than designing new ones that are able to adapt according to the task at hand. This paper presents the novel Feedback Continual Learning Vision Transformer (FCL-ViT) that uses a feedback mechanism to generate real-time dynamic attention features tailored to the current task. The FCL-ViT operates in two Phases. In phase 1, the generic image features are produced and determine where the Transformer should attend on the current image. In phase 2, task-specific image features are generated that leverage dynamic attention. To this end, Tunable self-Attention Blocks (TABs) and Task Specific Blocks (TSBs) are introduced that operate in both phases and are responsible for tuning the TABs attention, respectively. The FCL-ViT surpasses state-of-the-art performance on Continual Learning compared to benchmark methods, while retaining a small number of trainable DNN parameters.