 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIX: Implicitly Infusing Spatial Geometric Prior Knowledge into Visual Semantic Segmentation for Autonomous Driving
Paper and Code
Mar 13, 2024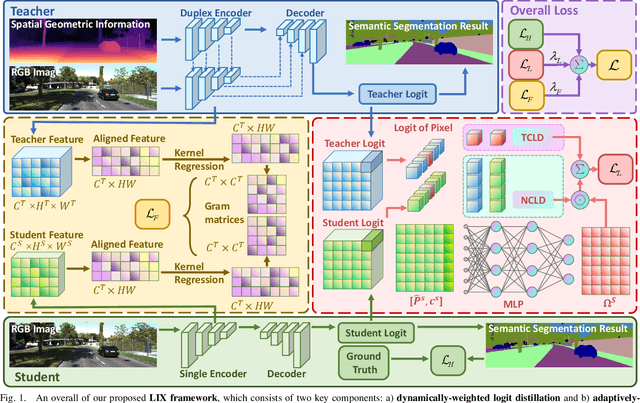
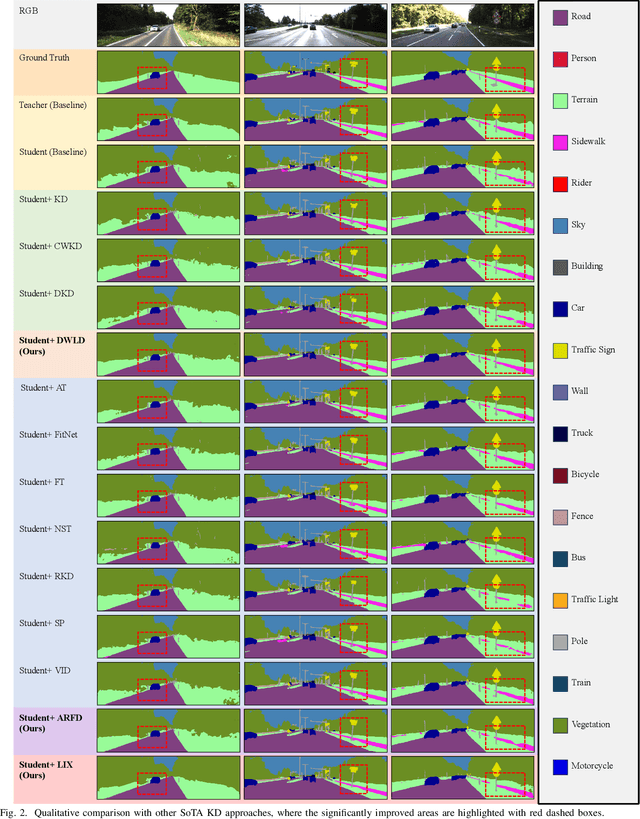
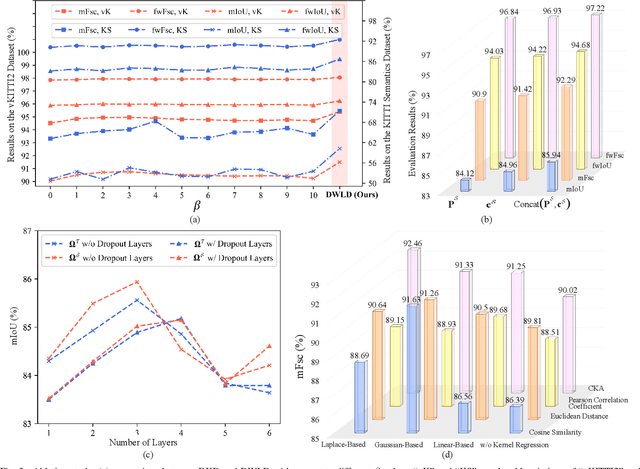
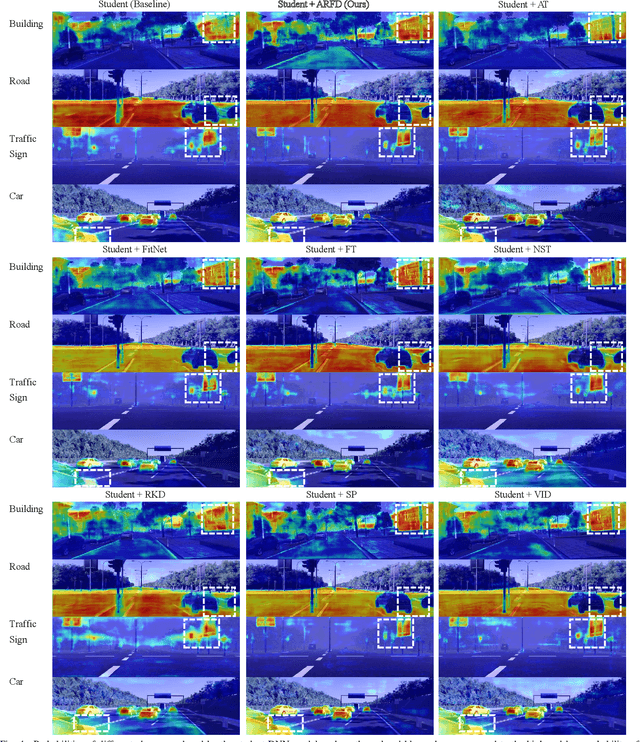
Despite the impressive performance achieved by data-fusion networks with duplex encoders for visual semantic segmentation, they become ineffective when spatial geometric data are not available. Implicitly infusing the spatial geometric prior knowledge acquired by a duplex-encoder teacher model into a single-encoder student model is a practical, albeit less explored research avenue. This paper delves into this topic and resorts to knowledge distillation approaches to address this problem. We introduce the Learning to Infuse "X" (LIX) framework, with novel contributions in both logit distillation and feature distillation aspects. We present a mathematical proof that underscores the limitation of using a single fixed weight in decoupled knowledge distillation and introduce a logit-wise dynamic weight controller as a solution to this issue. Furthermore, we develop an adaptively-recalibrated feature distillation algorithm, including two technical novelties: feature recalibration via kernel regression and in-depth feature consistency quantification via centered kernel alignment. Extensive experiments conducted with intermediate-fusion and late-fusion networks across various public datasets provide both quantitative and qualitative evaluations, demonstrating the superior performance of our LIX framework when compared to other state-of-the-art approaches.