 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Diffusion Models for Image Data Augmentation: A Review of Methods, Models, Evaluation Metrics and Future Research Directions
Jul 04, 2024Image data augmentation constitutes a critical methodology in modern computer vision tasks, since it can facilitate towards enhancing the diversity and quality of training datasets; thereby, improving the performance and robustness of machine learning models in downstream tasks. In parallel, augmentation approaches can also be used for editing/modifying a given image in a context- and semantics-aware way. Diffusion Models (DMs), which comprise one of the most recent and highly promising classes of methods in the field of generative Artificial Intelligence (AI), have emerged as a powerful tool for image data augmentation, capable of generating realistic and diverse images by learning the underlying data distribution. The current study realizes a systematic, comprehensive and in-depth review of DM-based approaches for image augmentation, covering a wide range of strategies, tasks and applications. In particular, a comprehensive analysis of the fundamental principles, model architectures and training strategies of DMs is initially performed. Subsequently, a taxonomy of the relevant image augmentation methods is introduced, focusing on techniques regarding semantic manipulation, personalization and adaptation, and application-specific augmentation tasks. Then, performance assessment methodologies and respective evaluation metrics are analyzed. Finally, current challenges and future research directions in the field are discussed.
CEASEFIRE: An AI-powered system for combatting illicit firearms trafficking
Jun 21, 2024Modern technologies have led illicit firearms trafficking to partially merge with cybercrime, while simultaneously permitting its off-line aspects to become more sophisticated. Law enforcement officers face difficult challenges that require hi-tech solutions. This article presents a real-world system, powered by advanced Artificial Intelligence, for facilitating them in their everyday work.
Self-supervised visual learning in the low-data regime: a comparative evaluation
Apr 26, 2024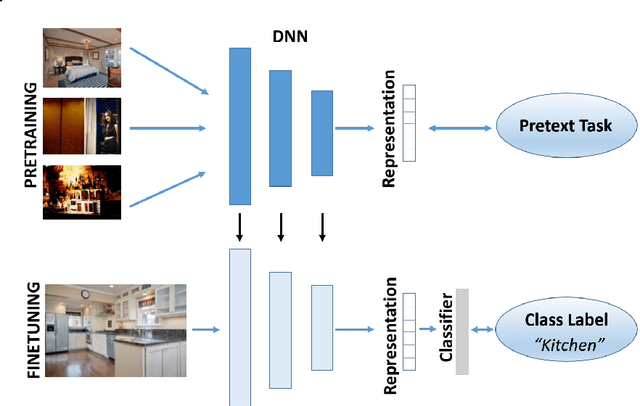



Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.
Illicit object detection in X-ray images using Vision Transformers
Mar 27, 2024



Illicit object detection is a critical task performed at various high-security locations, including airports, train stations, subways, and ports. The continuous and tedious work of examining thousands of X-ray images per hour can be mentally taxing. Thus, Deep Neural Networks (DNNs) can be used to automate the X-ray image analysis process, improve efficiency and alleviate the security officers' inspection burden. The neural architectures typically utilized in relevant literature are Convolutional Neural Networks (CNNs), with Vision Transformers (ViTs) rarely employed. In order to address this gap, this paper conducts a comprehensive evaluation of relevant ViT architectures on illicit item detection in X-ray images. This study utilizes both Transformer and hybrid backbones, such as SWIN and NextViT, and detectors, such as DINO and RT-DETR. The results demonstrate the remarkable accuracy of the DINO Transformer detector in the low-data regime, the impressive real-time performance of YOLOv8, and the effectiveness of the hybrid NextViT backbone.
Gesture-Controlled Aerial Robot Formation for Human-Swarm Interaction in Safety Monitoring Applications
Mar 22, 2024
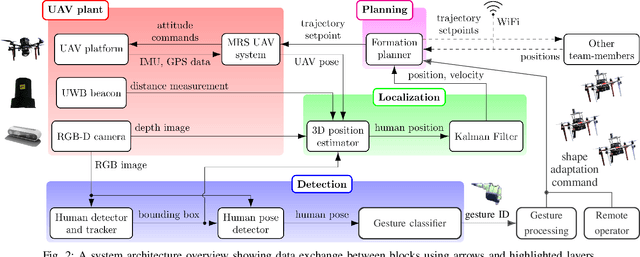
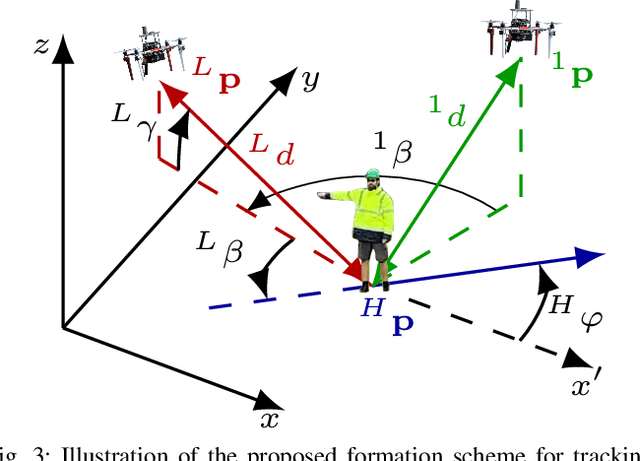
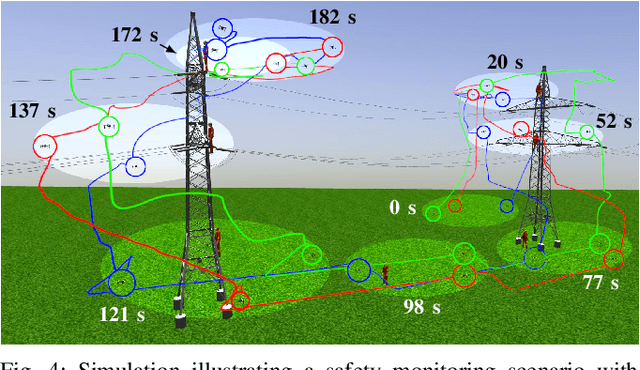
This paper presents a formation control approach for contactless gesture-based Human-Swarm Interaction (HSI) between a team of multi-rotor Unmanned Aerial Vehicles (UAVs) and a human worker. The approach is intended for monitoring the safety of human workers, especially those working at heights. In the proposed dynamic formation scheme, one UAV acts as the leader of the formation and is equipped with sensors for human worker detection and gesture recognition. The follower UAVs maintain a predetermined formation relative to the worker's position, thereby providing additional perspectives of the monitored scene. Hand gestures allow the human worker to specify movements and action commands for the UAV team and initiate other mission-related commands without the need for an additional communication channel or specific markers. Together with a novel unified human detection and tracking algorithm, human pose estimation approach and gesture detection pipeline, the proposed approach forms a first instance of an HSI system incorporating all these modules onboard real-world UAVs. Simulations and field experiments with three UAVs and a human worker in a mock-up scenario showcase the effectiveness and responsiveness of the proposed approach.
Self-supervised visual learning for analyzing firearms trafficking activities on the Web
Oct 12, 2023Automated visual firearms classification from RGB images is an important real-world task with applications in public space security, intelligence gathering and law enforcement investigations. When applied to images massively crawled from the World Wide Web (including social media and dark Web sites), it can serve as an important component of systems that attempt to identify criminal firearms trafficking networks, by analyzing Big Data from open-source intelligence. Deep Neural Networks (DNN) are the state-of-the-art methodology for achieving this, with Convolutional Neural Networks (CNN) being typically employed. The common transfer learning approach consists of pretraining on a large-scale, generic annotated dataset for whole-image classification, such as ImageNet-1k, and then finetuning the DNN on a smaller, annotated, task-specific, downstream dataset for visual firearms classification. Neither Visual Transformer (ViT) neural architectures nor Self-Supervised Learning (SSL) approaches have been so far evaluated on this critical task. SSL essentially consists of replacing the traditional supervised pretraining objective with an unsupervised pretext task that does not require ground-truth labels..
Visual inspection for illicit items in X-ray images using Deep Learning
Oct 05, 2023Automated detection of contraband items in X-ray images can significantly increase public safety, by enhancing the productivity and alleviating the mental load of security officers in airports, subways, customs/post offices, etc. The large volume and high throughput of passengers, mailed parcels, etc., during rush hours practically make it a Big Data problem. Modern computer vision algorithms relying on Deep Neural Networks (DNNs) have proven capable of undertaking this task even under resource-constrained and embedded execution scenarios, e.g., as is the case with fast, single-stage object detectors. However, no comparative experimental assessment of the various relevant DNN components/methods has been performed under a common evaluation protocol, which means that reliable cross-method comparisons are missing. This paper presents exactly such a comparative assessment, utilizing a public relevant dataset and a well-defined methodology for selecting the specific DNN components/modules that are being evaluated. The results indicate the superiority of Transformer detectors, the obsolete nature of auxiliary neural modules that have been developed in the past few years for security applications and the efficiency of the CSP-DarkNet backbone CNN.
Neural Natural Language Processing for Long Texts: A Survey of the State-of-the-Art
May 25, 2023


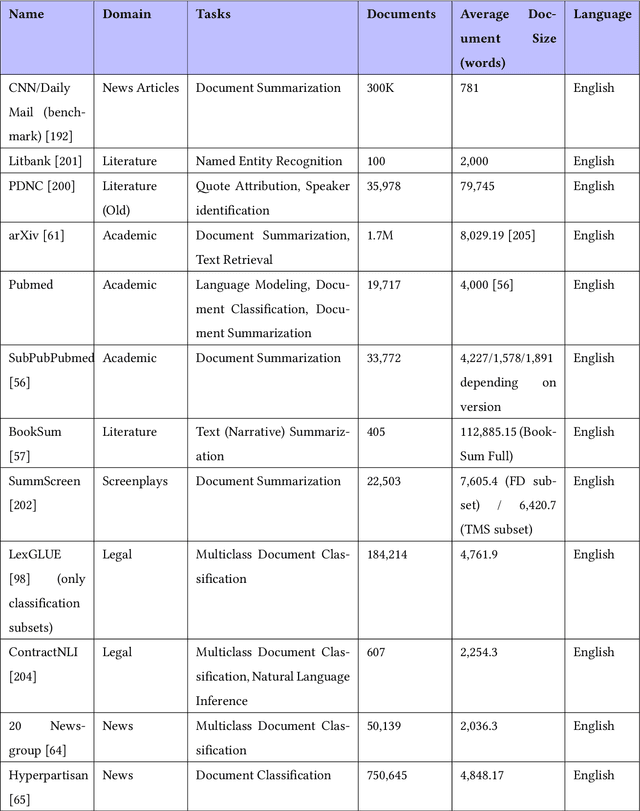
The adoption of Deep Neural Networks (DNNs) has greatly benefited Natural Language Processing (NLP) during the past decade. However, the demands of long documents analysis are quite different from those of shorter texts, with the ever increasing size of documents uploaded online rendering NLP on long documents a critical area of research. This paper surveys the current state-of-the-art in the domain, overviewing the relevant neural building blocks and subsequently focusing on two main NLP tasks: Document Classification, Summarization as well as mentioning uses in Sentiment Analysis. We detail the challenges, issues and current solutions related to long-document NLP. We also list publicly available, labelled, long-document datasets used in current research.
Illicit item detection in X-ray images for security applications
May 03, 2023



Automated detection of contraband items in X-ray images can significantly increase public safety, by enhancing the productivity and alleviating the mental load of security officers in airports, subways, customs/post offices, etc. The large volume and high throughput of passengers, mailed parcels, etc., during rush hours make it a Big Data analysis task. Modern computer vision algorithms relying on Deep Neural Networks (DNNs) have proven capable of undertaking this task even under resource-constrained and embedded execution scenarios, e.g., as is the case with fast, single-stage, anchor-based object detectors. This paper proposes a two-fold improvement of such algorithms for the X-ray analysis domain, introducing two complementary novelties. Firstly, more efficient anchors are obtained by hierarchical clustering the sizes of the ground-truth training set bounding boxes; thus, the resulting anchors follow a natural hierarchy aligned with the semantic structure of the data. Secondly, the default Non-Maximum Suppression (NMS) algorithm at the end of the object detection pipeline is modified to better handle occluded object detection and to reduce the number of false predictions, by inserting the Efficient Intersection over Union (E-IoU) metric into the Weighted Cluster NMS method. E-IoU provides more discriminative geometrical correlations between the candidate bounding boxes/Regions-of-Interest (RoIs). The proposed method is implemented on a common single-stage object detector (YOLOv5) and its experimental evaluation on a relevant public dataset indicates significant accuracy gains over both the baseline and competing approaches. This highlights the potential of Big Data analysis in enhancing public safety.