 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Natural Language Processing for Long Texts: A Survey of the State-of-the-Art
Paper and Code
May 25, 2023


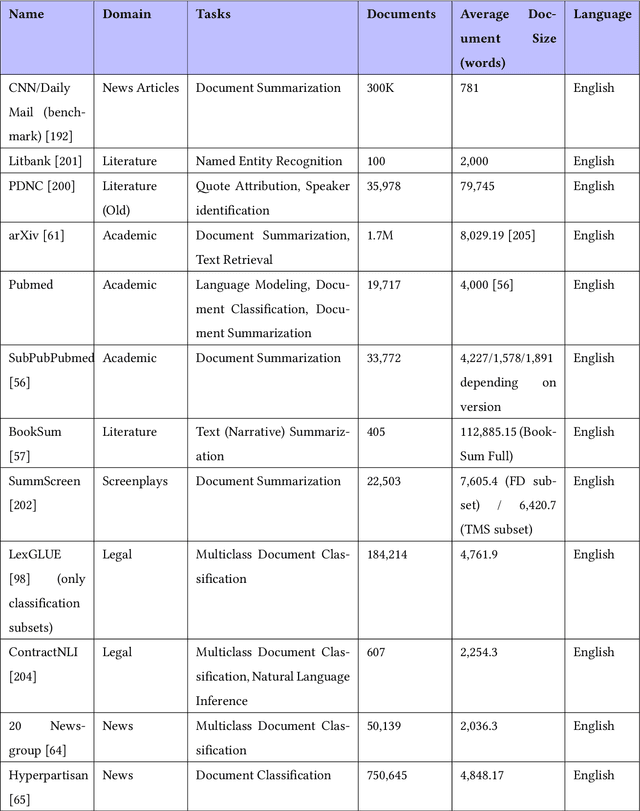
The adoption of Deep Neural Networks (DNNs) has greatly benefited Natural Language Processing (NLP) during the past decade. However, the demands of long documents analysis are quite different from those of shorter texts, with the ever increasing size of documents uploaded online rendering NLP on long documents a critical area of research. This paper surveys the current state-of-the-art in the domain, overviewing the relevant neural building blocks and subsequently focusing on two main NLP tasks: Document Classification, Summarization as well as mentioning uses in Sentiment Analysis. We detail the challenges, issues and current solutions related to long-document NLP. We also list publicly available, labelled, long-document datasets used in current research.