 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised visual learning in the low-data regime: a comparative evaluation
Paper and Code
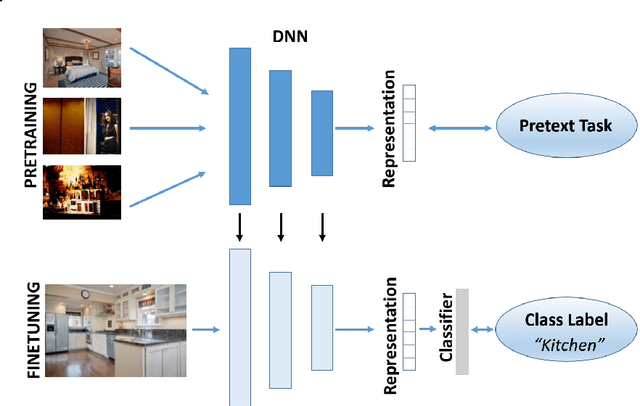



Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.