 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSkel-Mamba: Temporal Dynamic Modeling via State Space Model for Human Skeleton-based Action Recognition
Dec 12, 2025Skeleton-based action recognition has garnered significant attention in the computer vision community. Inspired by the recent success of the selective state-space model (SSM) Mamba in modeling 1D temporal sequences, we propose TSkel-Mamba, a hybrid Transformer-Mamba framework that effectively captures both spatial and temporal dynamics. In particular, our approach leverages Spatial Transformer for spatial feature learning while utilizing Mamba for temporal modeling. Mamba, however, employs separate SSM blocks for individual channels, which inherently limits its ability to model inter-channel dependencies. To better adapt Mamba for skeleton data and enhance Mamba`s ability to model temporal dependencies, we introduce a Temporal Dynamic Modeling (TDM) block, which is a versatile plug-and-play component that integrates a novel Multi-scale Temporal Interaction (MTI) module. The MTI module employs multi-scale Cycle operators to capture cross-channel temporal interactions, a critical factor in action recognition. Extensive experiments on NTU-RGB+D 60, NTU-RGB+D 120, NW-UCLA and UAV-Human datasets demonstrate that TSkel-Mamba achieves state-of-the-art performance while maintaining low inference time, making it both efficient and highly effective.
AutoICE: Automatically Synthesizing Verifiable C Code via LLM-driven Evolution
Dec 08, 2025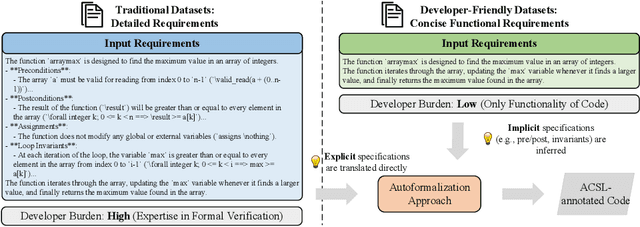
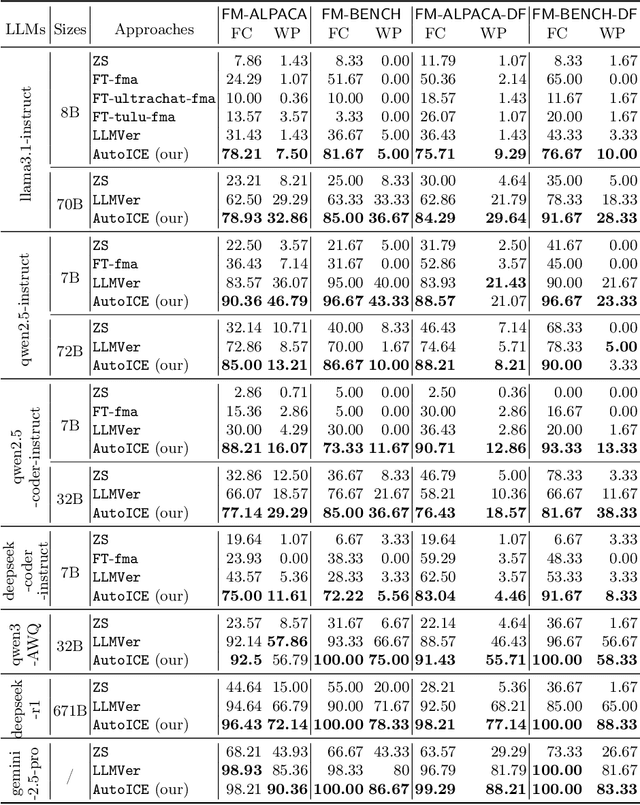

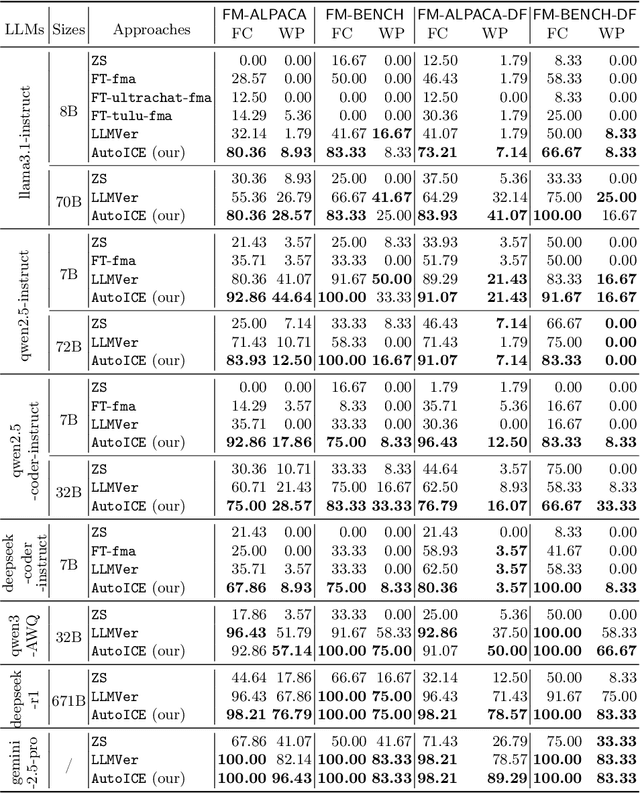
Automatically synthesizing verifiable code from natural language requirements ensures software correctness and reliability while significantly lowering the barrier to adopting the techniques of formal methods. With the rise of large language models (LLMs), long-standing efforts at autoformalization have gained new momentum. However, existing approaches suffer from severe syntactic and semantic errors due to the scarcity of domain-specific pre-training corpora and often fail to formalize implicit knowledge effectively. In this paper, we propose AutoICE, an LLM-driven evolutionary search for synthesizing verifiable C code. It introduces the diverse individual initialization and the collaborative crossover to enable diverse iterative updates, thereby mitigating error propagation inherent in single-agent iterations. Besides, it employs the self-reflective mutation to facilitate the discovery of implicit knowledge. Evaluation results demonstrate the effectiveness of AutoICE: it successfully verifies $90.36$\% of code, outperforming the state-of-the-art (SOTA) approach. Besides, on a developer-friendly dataset variant, AutoICE achieves a $88.33$\% verification success rate, significantly surpassing the $65$\% success rate of the SOTA approach.
Simultaneous Polysomnography and Cardiotocography Reveal Temporal Correlation Between Maternal Obstructive Sleep Apnea and Fetal Hypoxia
Apr 17, 2025Background: Obstructive sleep apnea syndrome (OSAS) during pregnancy is common and can negatively affect fetal outcomes. However, studies on the immediate effects of maternal hypoxia on fetal heart rate (FHR) changes are lacking. Methods: We used time-synchronized polysomnography (PSG) and cardiotocography (CTG) data from two cohorts to analyze the correlation between maternal hypoxia and FHR changes (accelerations or decelerations). Maternal hypoxic event characteristics were analyzed using generalized linear modeling (GLM) to assess their associations with different FHR changes. Results: A total of 118 pregnant women participated. FHR changes were significantly associated with maternal hypoxia, primarily characterized by accelerations. A longer hypoxic duration correlated with more significant FHR accelerations (P < 0.05), while prolonged hypoxia and greater SpO2 drop were linked to FHR decelerations (P < 0.05). Both cohorts showed a transient increase in FHR during maternal hypoxia, which returned to baseline after the event resolved. Conclusion: Maternal hypoxia significantly affects FHR, suggesting that maternal OSAS may contribute to fetal hypoxia. These findings highlight the importance of maternal-fetal interactions and provide insights for future interventions.
Egocentric Hand-object Interaction Detection
Nov 16, 2022In this paper, we propose a method to jointly determine the status of hand-object interaction. This is crucial for egocentric human activity understanding and interaction. From a computer vision perspective, we believe that determining whether a hand is interacting with an object depends on whether there is an interactive hand pose and whether the hand is touching the object. Thus, we extract the hand pose, hand-object masks to jointly determine the interaction status. In order to solve the problem of hand pose estimation due to in-hand object occlusion, we use a multi-cam system to capture hand pose data from multiple perspectives. We evaluate and compare our method with the most recent work from Shan et al. \cite{Shan20} on selected images from EPIC-KITCHENS \cite{damen2018scaling} dataset and achieve $89\%$ accuracy on HOI (hand-object interaction) detection which is comparative to Shan's ($92\%$). However, for real-time performance, our method can run over $\textbf{30}$ FPS which is much more efficient than Shan's ($\textbf{1}\sim\textbf{2}$ FPS). A demo can be found from https://www.youtube.com/watch?v=XVj3zBuynmQ
On-Sensor Binarized Fully Convolutional Neural Network with A Pixel Processor Array
Feb 02, 2022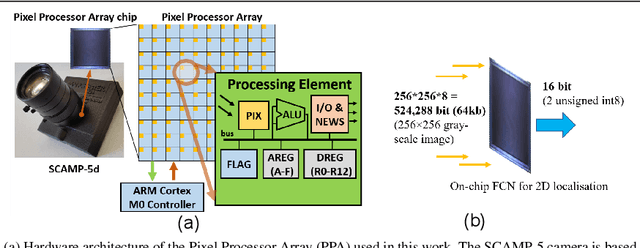
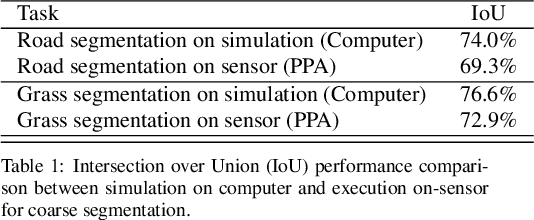


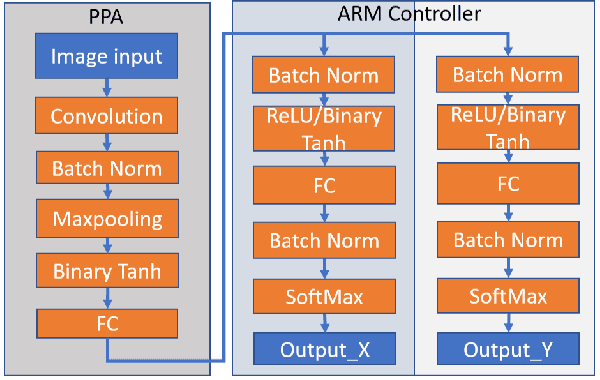
This work presents a method to implement fully convolutional neural networks (FCNs) on Pixel Processor Array (PPA) sensors, and demonstrates coarse segmentation and object localisation tasks. We design and train binarized FCN for both binary weights and activations using batchnorm, group convolution, and learnable threshold for binarization, producing networks small enough to be embedded on the focal plane of the PPA, with limited local memory resources, and using parallel elementary add/subtract, shifting, and bit operations only. We demonstrate the first implementation of an FCN on a PPA device, performing three convolution layers entirely in the pixel-level processors. We use this architecture to demonstrate inference generating heat maps for object segmentation and localisation at over 280 FPS using the SCAMP-5 PPA vision chip.
Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection
Dec 24, 2021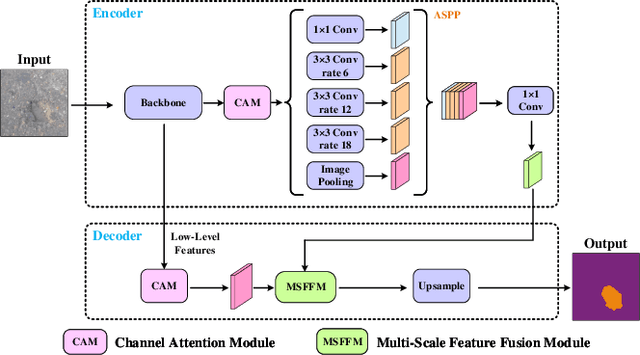
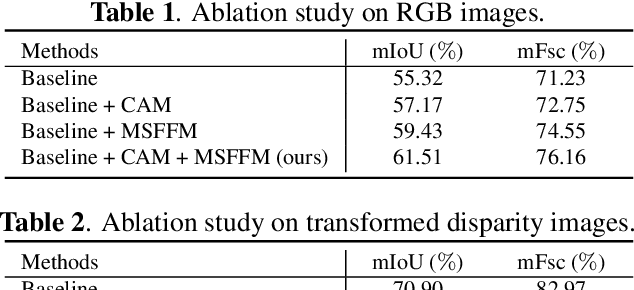
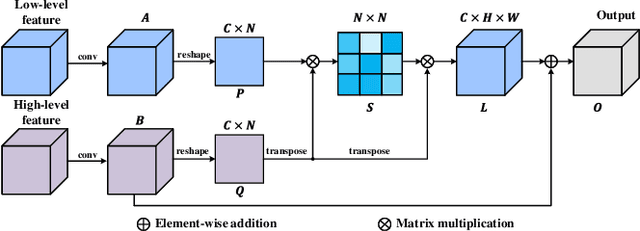
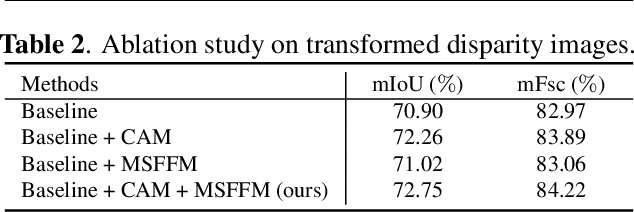
This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.
Fully-simulated Integration of Scamp5d Vision System and Robot Simulator
Oct 12, 2021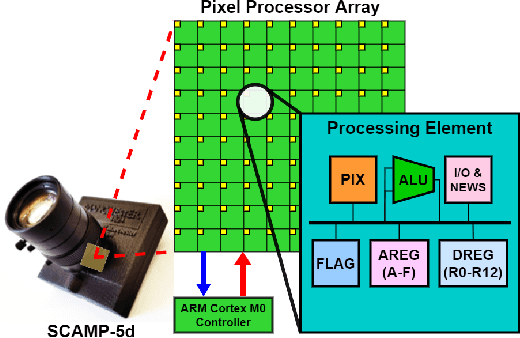

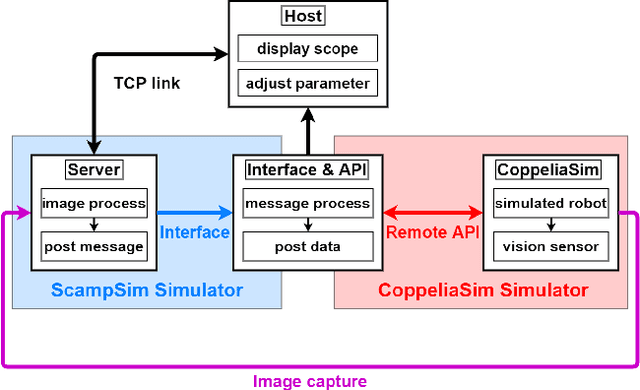
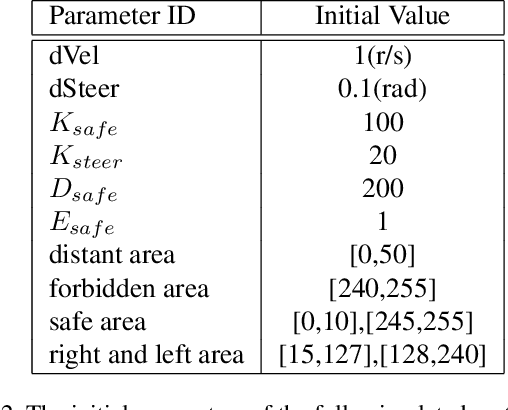
This paper proposed a fully-simulated environment by integrating an on-sensor visual computing device, SCAMP, and CoppeliaSim robot simulator via interface and remote API. Within this platform, a mobile robot obstacle avoidance and target navigation with pre-set barriers is exploited with on-sensor visual computing, where images are captured in a robot simulator and processed by an on-sensor processing server after being transferred. We made our developed platform and associated algorithms for mobile robot navigation available online.
Bringing A Robot Simulator to the SCAMP Vision System
May 21, 2021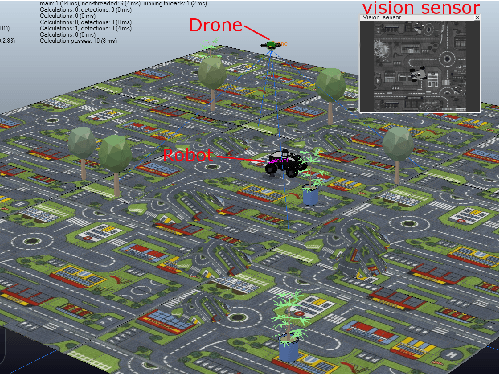
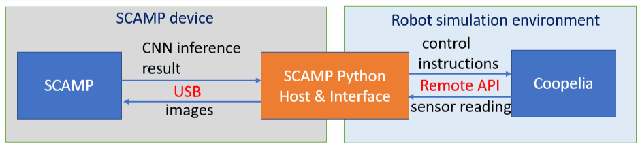

This work develops and demonstrates the integration of the SCAMP-5d vision system into the CoppeliaSim robot simulator, creating a semi-simulated environment. By configuring a camera in the simulator and setting up communication with the SCAMP python host through remote API, sensor images from the simulator can be transferred to the SCAMP vision sensor, where on-sensor image processing such as CNN inference can be performed. SCAMP output is then fed back into CoppeliaSim. This proposed platform integration enables rapid prototyping validations of SCAMP algorithms for robotic systems. We demonstrate a car localisation and tracking task using this proposed semi-simulated platform, with a CNN inference on SCAMP to command the motion of a robot. We made this platform available online.
Loop-box: Multi-Agent Direct SLAM Triggered by Single Loop Closure for Large-Scale Mapping
Sep 29, 2020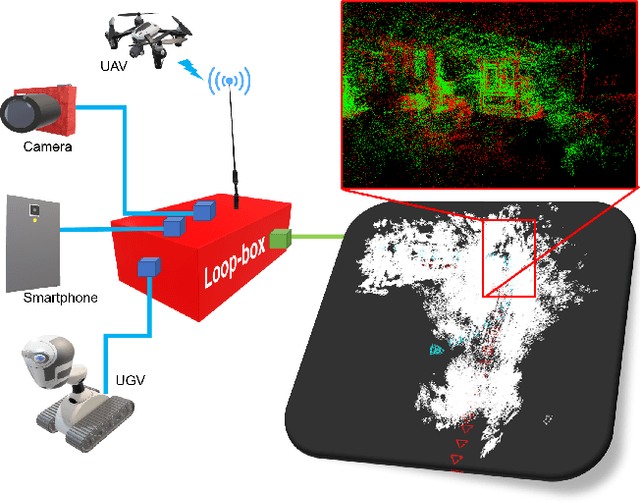
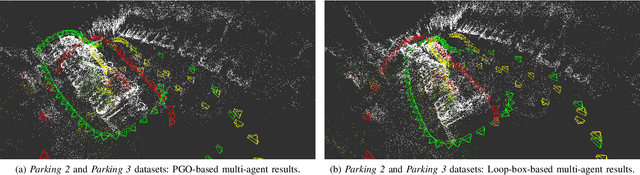
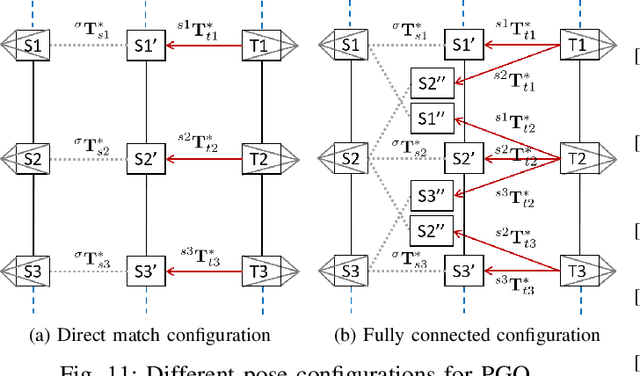
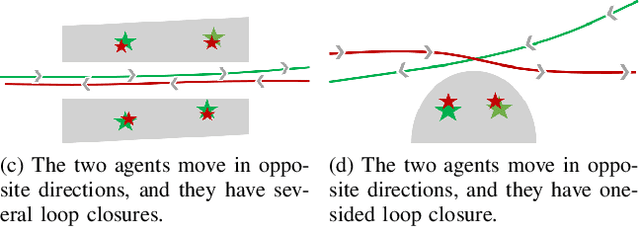
In this paper, we present a multi-agent framework for real-time large-scale 3D reconstruction applications. In SLAM, researchers usually build and update a 3D map after applying non-linear pose graph optimization techniques. Moreover, many multi-agent systems are prevalently using odometry information from additional sensors. These methods generally involve intensive computer vision algorithms and are tightly coupled with various sensors. We develop a generic method for the keychallenging scenarios in multi-agent 3D mapping based on different camera systems. The proposed framework performs actively in terms of localizing each agent after the first loop closure between them. It is shown that the proposed system only uses monocular cameras to yield real-time multi-agent large-scale localization and 3D global mapping. Based on the initial matching, our system can calculate the optimal scale difference between multiple 3D maps and then estimate an accurate relative pose transformation for large-scale global mapping.
* Material related to this work is available at https://usmanmaqbool.github.io/loop-box
Agile Reactive Navigation for A Non-Holonomic Mobile Robot Using A Pixel Processor Array
Sep 27, 2020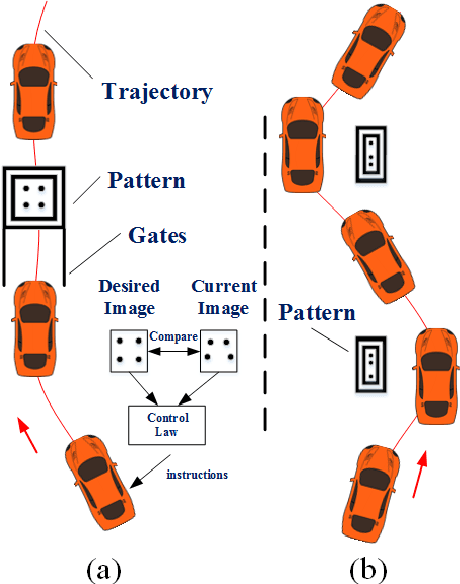

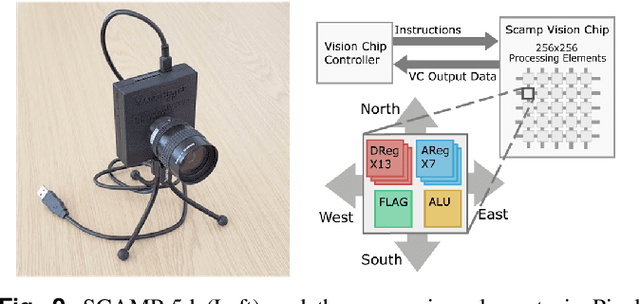
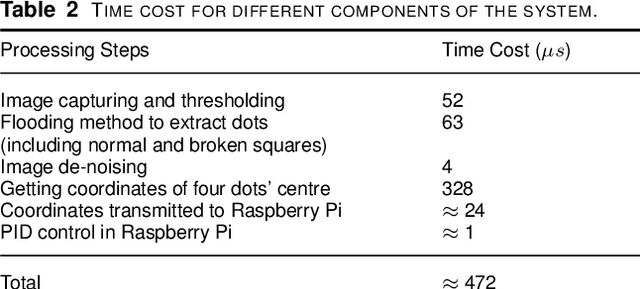
This paper presents an agile reactive navigation strategy for driving a non-holonomic ground vehicle around a preset course of gates in a cluttered environment using a low-cost processor array sensor. This enables machine vision tasks to be performed directly upon the sensor's image plane, rather than using a separate general-purpose computer. We demonstrate a small ground vehicle running through or avoiding multiple gates at high speed using minimal computational resources. To achieve this, target tracking algorithms are developed for the Pixel Processing Array and captured images are then processed directly on the vision sensor acquiring target information for controlling the ground vehicle. The algorithm can run at up to 2000 fps outdoors and 200fps at indoor illumination levels. Conducting image processing at the sensor level avoids the bottleneck of image transfer encountered in conventional sensors. The real-time performance of on-board image processing and robustness is validated through experiments. Experimental results demonstrate that the algorithm's ability to enable a ground vehicle to navigate at an average speed of 2.20 m/s for passing through multiple gates and 3.88 m/s for a 'slalom' task in an environment featuring significant visual clutter.