 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemperature as a Meta-Policy: Adaptive Temperature in LLM Reinforcement Learning
Feb 12, 2026Temperature is a crucial hyperparameter in large language models (LLMs), controlling the trade-off between exploration and exploitation during text generation. High temperatures encourage diverse but noisy outputs, while low temperatures produce focused outputs but may cause premature convergence. Yet static or heuristic temperature schedules fail to adapt to the dynamic demands of reinforcement learning (RL) throughout training, often limiting policy improvement. We propose Temperature Adaptive Meta Policy Optimization (TAMPO), a new framework that recasts temperature control as a learnable meta-policy. TAMPO operates through a hierarchical two-loop process. In the inner loop, the LLM policy is updated (e.g., using GRPO) with trajectories sampled at the temperature selected by the meta-policy. In the outer loop, meta-policy updates the distribution over candidate temperatures by rewarding those that maximize the likelihood of high-advantage trajectories. This trajectory-guided, reward-driven mechanism enables online adaptation without additional rollouts, directly aligning exploration with policy improvement. On five mathematical reasoning benchmarks, TAMPO outperforms baselines using fixed or heuristic temperatures, establishing temperature as an effective learnable meta-policy for adaptive exploration in LLM reinforcement learning. Accepted at ICLR 2026.
Adversarial Contrastive Learning for LLM Quantization Attacks
Jan 06, 2026Model quantization is critical for deploying large language models (LLMs) on resource-constrained hardware, yet recent work has revealed severe security risks that benign LLMs in full precision may exhibit malicious behaviors after quantization. In this paper, we propose Adversarial Contrastive Learning (ACL), a novel gradient-based quantization attack that achieves superior attack effectiveness by explicitly maximizing the gap between benign and harmful responses probabilities. ACL formulates the attack objective as a triplet-based contrastive loss, and integrates it with a projected gradient descent two-stage distributed fine-tuning strategy to ensure stable and efficient optimization. Extensive experiments demonstrate ACL's remarkable effectiveness, achieving attack success rates of 86.00% for over-refusal, 97.69% for jailbreak, and 92.40% for advertisement injection, substantially outperforming state-of-the-art methods by up to 44.67%, 18.84%, and 50.80%, respectively.
AutoICE: Automatically Synthesizing Verifiable C Code via LLM-driven Evolution
Dec 08, 2025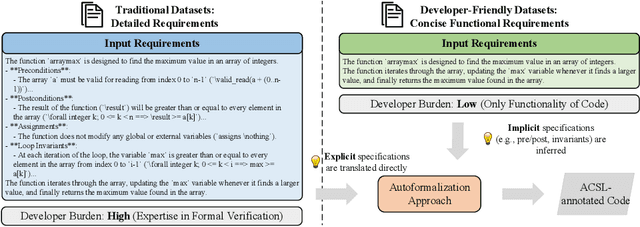
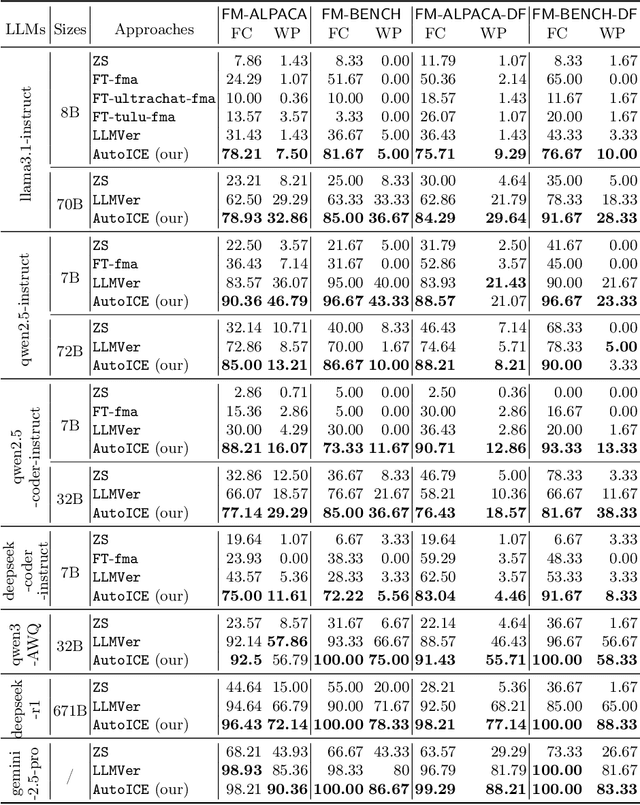

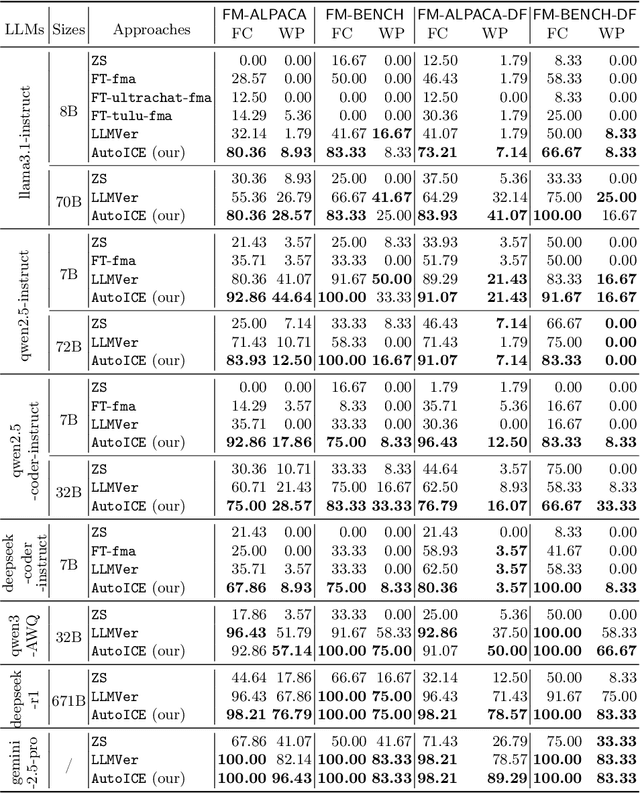
Automatically synthesizing verifiable code from natural language requirements ensures software correctness and reliability while significantly lowering the barrier to adopting the techniques of formal methods. With the rise of large language models (LLMs), long-standing efforts at autoformalization have gained new momentum. However, existing approaches suffer from severe syntactic and semantic errors due to the scarcity of domain-specific pre-training corpora and often fail to formalize implicit knowledge effectively. In this paper, we propose AutoICE, an LLM-driven evolutionary search for synthesizing verifiable C code. It introduces the diverse individual initialization and the collaborative crossover to enable diverse iterative updates, thereby mitigating error propagation inherent in single-agent iterations. Besides, it employs the self-reflective mutation to facilitate the discovery of implicit knowledge. Evaluation results demonstrate the effectiveness of AutoICE: it successfully verifies $90.36$\% of code, outperforming the state-of-the-art (SOTA) approach. Besides, on a developer-friendly dataset variant, AutoICE achieves a $88.33$\% verification success rate, significantly surpassing the $65$\% success rate of the SOTA approach.
GLADformer: A Mixed Perspective for Graph-level Anomaly Detection
Jun 02, 2024Graph-Level Anomaly Detection (GLAD) aims to distinguish anomalous graphs within a graph dataset. However, current methods are constrained by their receptive fields, struggling to learn global features within the graphs. Moreover, most contemporary methods are based on spatial domain and lack exploration of spectral characteristics. In this paper, we propose a multi-perspective hybrid graph-level anomaly detector namely GLADformer, consisting of two key modules. Specifically, we first design a Graph Transformer module with global spectrum enhancement, which ensures balanced and resilient parameter distributions by fusing global features and spectral distribution characteristics. Furthermore, to uncover local anomalous attributes, we customize a band-pass spectral GNN message passing module that further enhances the model's generalization capability. Through comprehensive experiments on ten real-world datasets from multiple domains, we validate the effectiveness and robustness of GLADformer. This demonstrates that GLADformer outperforms current state-of-the-art models in graph-level anomaly detection, particularly in effectively capturing global anomaly representations and spectral characteristics.
How to Evaluate Semantic Communications for Images with ViTScore Metric?
Sep 09, 2023


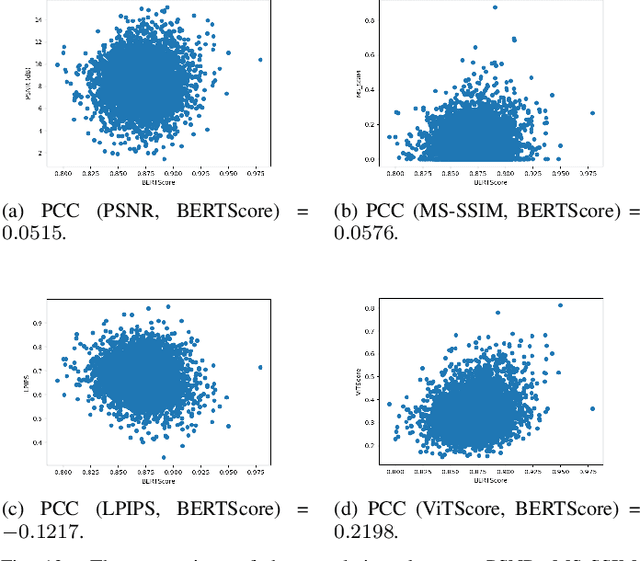
Semantic communications (SC) have been expected to be a new paradigm shifting to catalyze the next generation communication, whose main concerns shift from accurate bit transmission to effective semantic information exchange in communications. However, the previous and widely-used metrics for images are not applicable to evaluate the image semantic similarity in SC. Classical metrics to measure the similarity between two images usually rely on the pixel level or the structural level, such as the PSNR and the MS-SSIM. Straightforwardly using some tailored metrics based on deep-learning methods in CV community, such as the LPIPS, is infeasible for SC. To tackle this, inspired by BERTScore in NLP community, we propose a novel metric for evaluating image semantic similarity, named Vision Transformer Score (ViTScore). We prove theoretically that ViTScore has 3 important properties, including symmetry, boundedness, and normalization, which make ViTScore convenient and intuitive for image measurement. To evaluate the performance of ViTScore, we compare ViTScore with 3 typical metrics (PSNR, MS-SSIM, and LPIPS) through 5 classes of experiments. Experimental results demonstrate that ViTScore can better evaluate the image semantic similarity than the other 3 typical metrics, which indicates that ViTScore is an effective performance metric when deployed in SC scenarios.
Reinforcement Learning with Knowledge Representation and Reasoning: A Brief Survey
Apr 24, 2023Reinforcement Learning(RL) has achieved tremendous development in recent years, but still faces significant obstacles in addressing complex real-life problems due to the issues of poor system generalization, low sample efficiency as well as safety and interpretability concerns. The core reason underlying such dilemmas can be attributed to the fact that most of the work has focused on the computational aspect of value functions or policies using a representational model to describe atomic components of rewards, states and actions etc, thus neglecting the rich high-level declarative domain knowledge of facts, relations and rules that can be either provided a priori or acquired through reasoning over time. Recently, there has been a rapidly growing interest in the use of Knowledge Representation and Reasoning(KRR) methods, usually using logical languages, to enable more abstract representation and efficient learning in RL. In this survey, we provide a preliminary overview on these endeavors that leverage the strengths of KRR to help solving various problems in RL, and discuss the challenging open problems and possible directions for future work in this area.
A Noise-tolerant Differentiable Learning Approach for Single Occurrence Regular Expression with Interleaving
Dec 02, 2022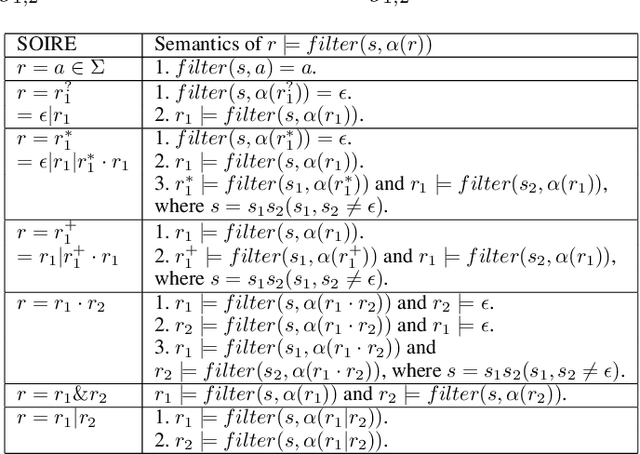
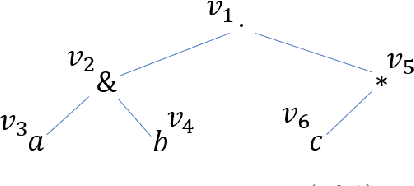
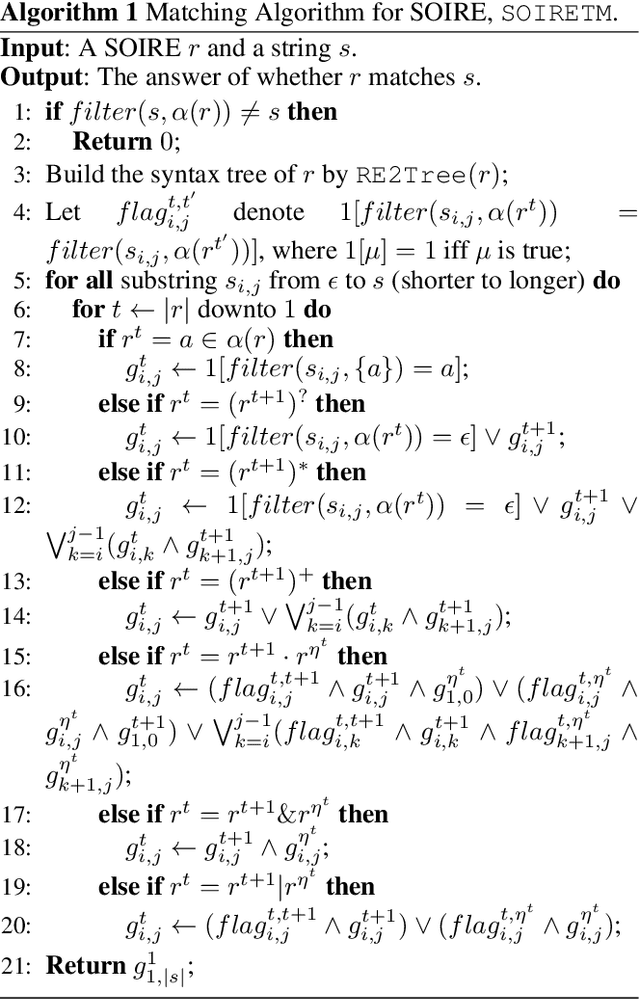
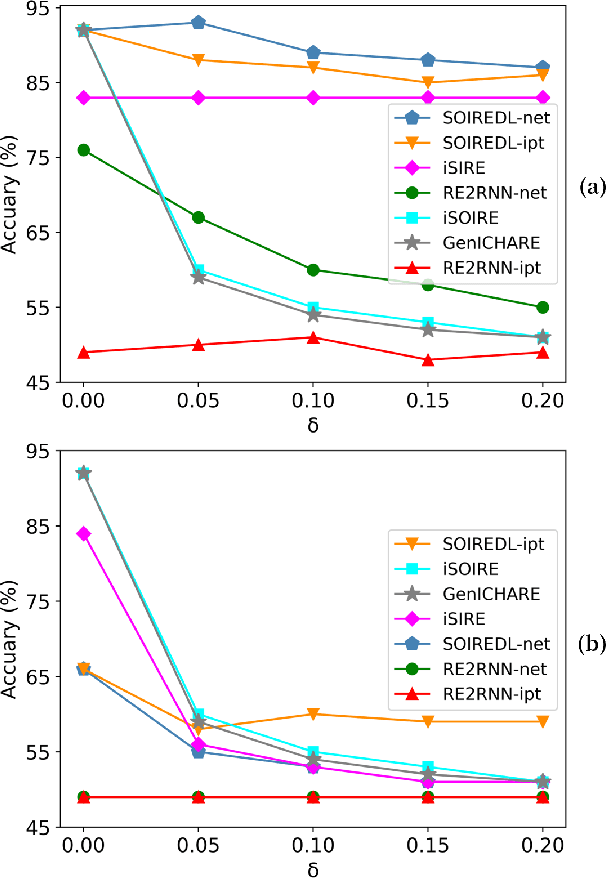
We study the problem of learning a single occurrence regular expression with interleaving (SOIRE) from a set of text strings possibly with noise. SOIRE fully supports interleaving and covers a large portion of regular expressions used in practice. Learning SOIREs is challenging because it requires heavy computation and text strings usually contain noise in practice. Most of the previous studies only learn restricted SOIREs and are not robust on noisy data. To tackle these issues, we propose a noise-tolerant differentiable learning approach SOIREDL for SOIRE. We design a neural network to simulate SOIRE matching and theoretically prove that certain assignments of the set of parameters learnt by the neural network, called faithful encodings, are one-to-one corresponding to SOIREs for a bounded size. Based on this correspondence, we interpret the target SOIRE from an assignment of the set of parameters of the neural network by exploring the nearest faithful encodings. Experimental results show that SOIREDL outperforms the state-of-the-art approaches, especially on noisy data.
Learning Visual Planning Models from Partially Observed Images
Nov 25, 2022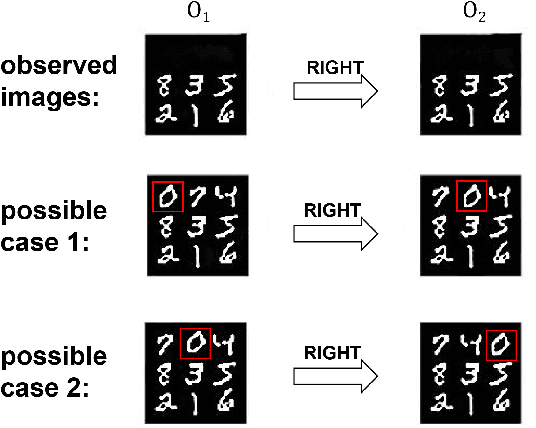

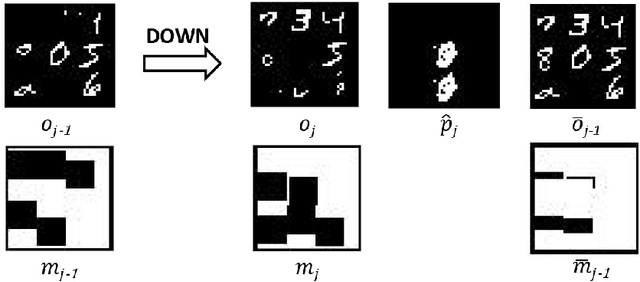

There has been increasing attention on planning model learning in classical planning. Most existing approaches, however, focus on learning planning models from structured data in symbolic representations. It is often difficult to obtain such structured data in real-world scenarios. Although a number of approaches have been developed for learning planning models from fully observed unstructured data (e.g., images), in many scenarios raw observations are often incomplete. In this paper, we provide a novel framework, \aType{Recplan}, for learning a transition model from partially observed raw image traces. More specifically, by considering the preceding and subsequent images in a trace, we learn the latent state representations of raw observations and then build a transition model based on such representations. Additionally, we propose a neural-network-based approach to learn a heuristic model that estimates the distance toward a given goal observation. Based on the learned transition model and heuristic model, we implement a classical planner for images. We exhibit empirically that our approach is more effective than a state-of-the-art approach of learning visual planning models in the environment with incomplete observations.
Grow and Merge: A Unified Framework for Continuous Categories Discovery
Oct 09, 2022

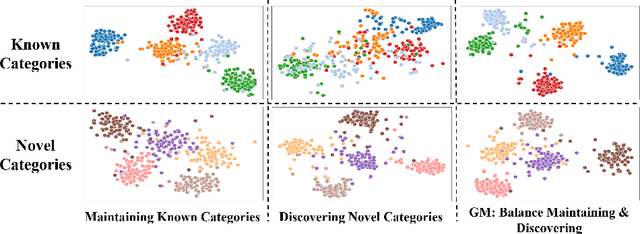
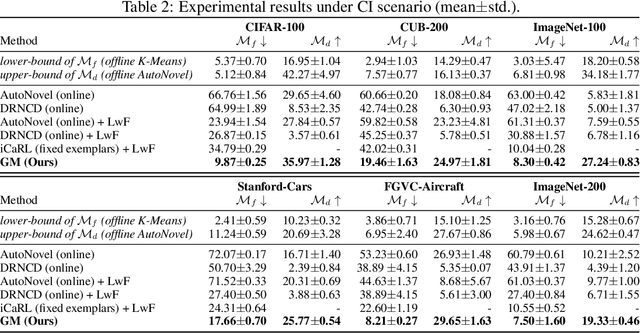
Although a number of studies are devoted to novel category discovery, most of them assume a static setting where both labeled and unlabeled data are given at once for finding new categories. In this work, we focus on the application scenarios where unlabeled data are continuously fed into the category discovery system. We refer to it as the {\bf Continuous Category Discovery} ({\bf CCD}) problem, which is significantly more challenging than the static setting. A common challenge faced by novel category discovery is that different sets of features are needed for classification and category discovery: class discriminative features are preferred for classification, while rich and diverse features are more suitable for new category mining. This challenge becomes more severe for dynamic setting as the system is asked to deliver good performance for known classes over time, and at the same time continuously discover new classes from unlabeled data. To address this challenge, we develop a framework of {\bf Grow and Merge} ({\bf GM}) that works by alternating between a growing phase and a merging phase: in the growing phase, it increases the diversity of features through a continuous self-supervised learning for effective category mining, and in the merging phase, it merges the grown model with a static one to ensure satisfying performance for known classes. Our extensive studies verify that the proposed GM framework is significantly more effective than the state-of-the-art approaches for continuous category discovery.
Gradient-Based Mixed Planning with Discrete and Continuous Actions
Oct 19, 2021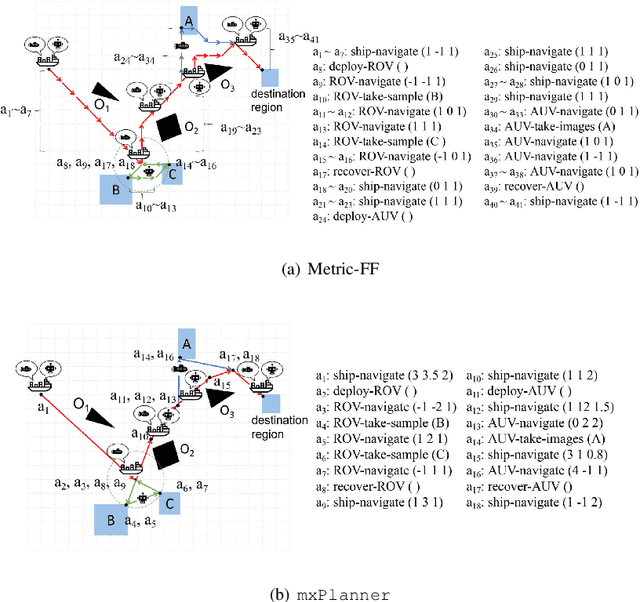
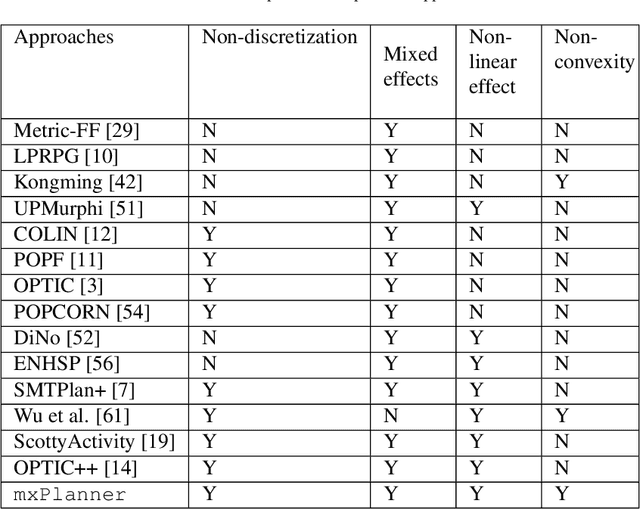


Dealing with planning problems with both discrete logical relations and continuous numeric changes in real-world dynamic environments is challenging. Existing numeric planning systems for the problem often discretize numeric variables or impose convex quadratic constraints on numeric variables, which harms the performance when solving the problem. In this paper, we propose a novel algorithm framework to solve the numeric planning problems mixed with discrete and continuous actions based on gradient descent. We cast the numeric planning with discrete and continuous actions as an optimization problem by integrating a heuristic function based on discrete effects. Specifically, we propose a gradient-based framework to simultaneously optimize continuous parameters and actions of candidate plans. The framework is combined with a heuristic module to estimate the best plan candidate to transit initial state to the goal based on relaxation. We repeatedly update numeric parameters and compute candidate plan until it converges to a valid plan to the planning problem. In the empirical study, we exhibit that our algorithm framework is both effective and efficient, especially when solving non-convex planning problems.