 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Reinforced Deep Priors for Reparameterized Full Waveform Inversion
Dec 09, 2025

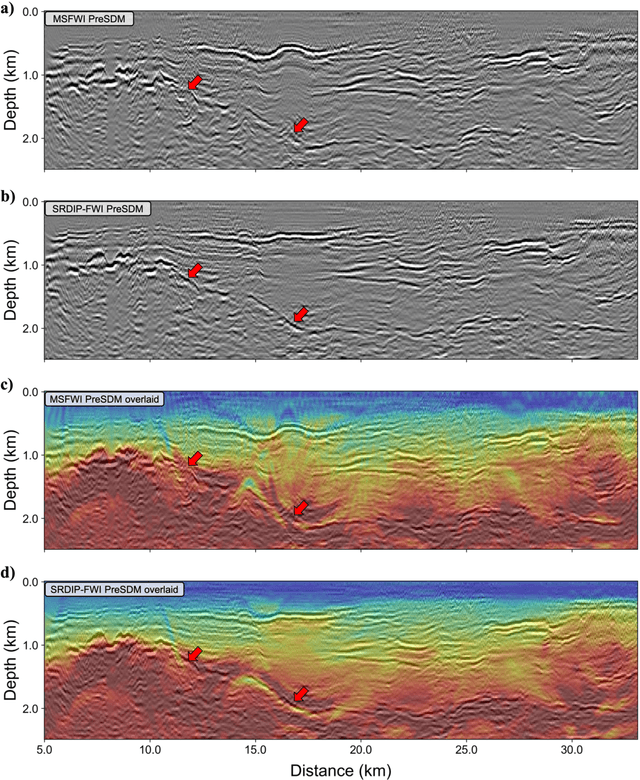

Full waveform inversion (FWI) has become a widely adopted technique for high-resolution subsurface imaging. However, its inherent strong nonlinearity often results in convergence toward local minima. Recently, deep image prior-based reparameterized FWI (DIP-FWI) has been proposed to alleviate the dependence on massive training data. By exploiting the spectral bias and implicit regularization in the neural network architecture, DIP-FWI can effectively avoid local minima and reconstruct more geologically plausible velocity models. Nevertheless, existing DIP-FWI typically use a fixed random input throughout the inversion process, which fails to utilize the mapping and correlation between the input and output of the network. Moreover, under complex geological conditions, the lack of informative prior in the input can exacerbate the ill-posedness of the inverse problem, leading to artifacts and unstable reconstructions. To address these limitations, we propose a self-reinforced DIP-FWI (SRDIP-FWI) framework, in which a steering algorithm alternately updates both the network parameters and the input at each iteration using feedback from the current network output. This design allows adaptive structural enhancement and improved regularization, thereby effectively mitigating the ill-posedness in FWI. Additionally, we analyze the spectral bias of the network in SRDIP-FWI and quantify its role in multiscale velocity model building. Synthetic tests and field land data application demonstrate that SRDIP-FWI achieves superior resolution, improved accuracy and greater depth penetration compared to multiscale FWI. More importantly, SRDIP-FWI eliminates the need for manual frequency-band selection and time-window picking, substantially simplifying the inversion workflow. Overall, the proposed method provides a novel, adaptive and robust framework for accurate subsurface velocity model reconstruction.
Multi-Agent Reinforcement Learning with a Hierarchy of Reward Machines
Mar 08, 2024In this paper, we study the cooperative Multi-Agent Reinforcement Learning (MARL) problems using Reward Machines (RMs) to specify the reward functions such that the prior knowledge of high-level events in a task can be leveraged to facilitate the learning efficiency. Unlike the existing work that RMs have been incorporated into MARL for task decomposition and policy learning in relatively simple domains or with an assumption of independencies among the agents, we present Multi-Agent Reinforcement Learning with a Hierarchy of RMs (MAHRM) that is capable of dealing with more complex scenarios when the events among agents can occur concurrently and the agents are highly interdependent. MAHRM exploits the relationship of high-level events to decompose a task into a hierarchy of simpler subtasks that are assigned to a small group of agents, so as to reduce the overall computational complexity. Experimental results in three cooperative MARL domains show that MAHRM outperforms other MARL methods using the same prior knowledge of high-level events.
Reinforcement Learning with Knowledge Representation and Reasoning: A Brief Survey
Apr 24, 2023Reinforcement Learning(RL) has achieved tremendous development in recent years, but still faces significant obstacles in addressing complex real-life problems due to the issues of poor system generalization, low sample efficiency as well as safety and interpretability concerns. The core reason underlying such dilemmas can be attributed to the fact that most of the work has focused on the computational aspect of value functions or policies using a representational model to describe atomic components of rewards, states and actions etc, thus neglecting the rich high-level declarative domain knowledge of facts, relations and rules that can be either provided a priori or acquired through reasoning over time. Recently, there has been a rapidly growing interest in the use of Knowledge Representation and Reasoning(KRR) methods, usually using logical languages, to enable more abstract representation and efficient learning in RL. In this survey, we provide a preliminary overview on these endeavors that leverage the strengths of KRR to help solving various problems in RL, and discuss the challenging open problems and possible directions for future work in this area.
Lifelong Reinforcement Learning with Temporal Logic Formulas and Reward Machines
Nov 18, 2021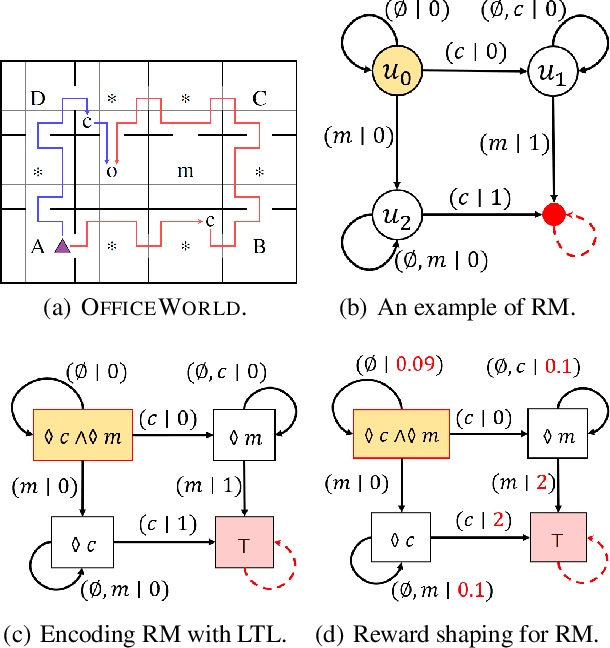
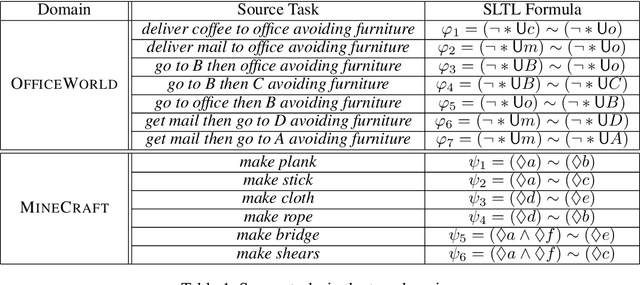
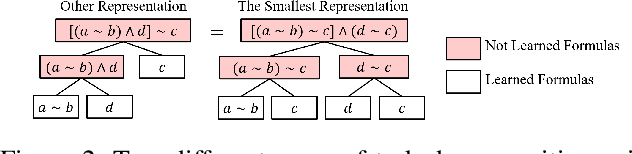
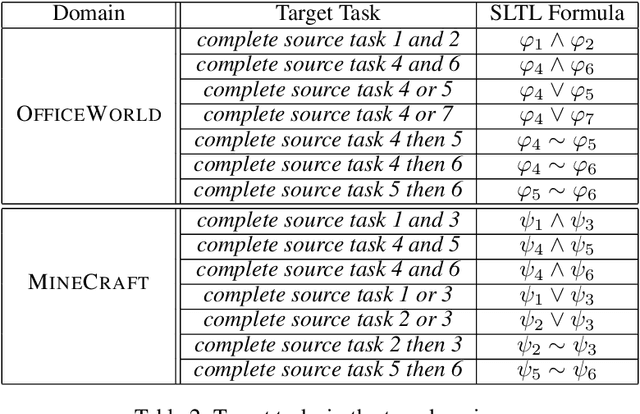
Continuously learning new tasks using high-level ideas or knowledge is a key capability of humans. In this paper, we propose Lifelong reinforcement learning with Sequential linear temporal logic formulas and Reward Machines (LSRM), which enables an agent to leverage previously learned knowledge to fasten learning of logically specified tasks. For the sake of more flexible specification of tasks, we first introduce Sequential Linear Temporal Logic (SLTL), which is a supplement to the existing Linear Temporal Logic (LTL) formal language. We then utilize Reward Machines (RM) to exploit structural reward functions for tasks encoded with high-level events, and propose automatic extension of RM and efficient knowledge transfer over tasks for continuous learning in lifetime. Experimental results show that LSRM outperforms the methods that learn the target tasks from scratch by taking advantage of the task decomposition using SLTL and knowledge transfer over RM during the lifelong learning process.