 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025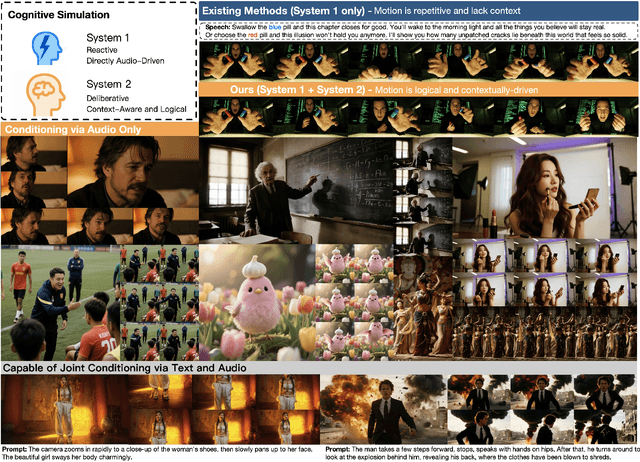
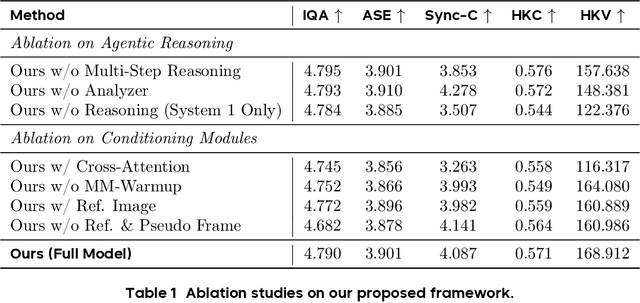
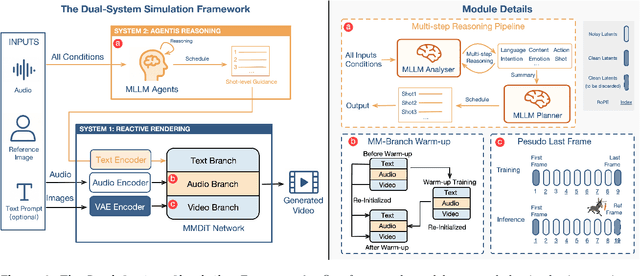

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025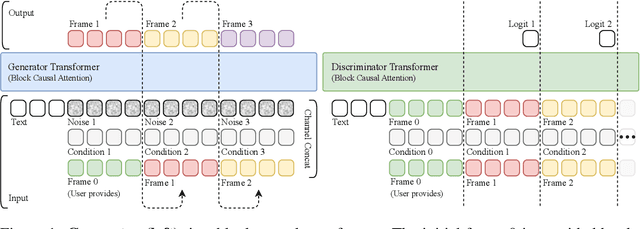
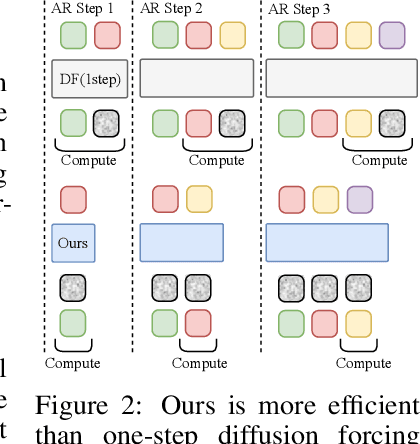
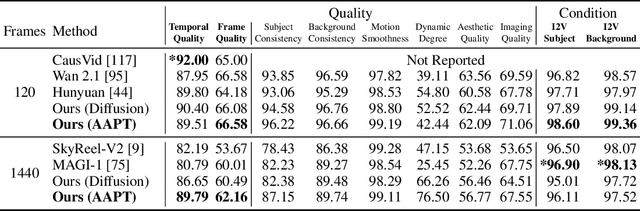

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Feb 03, 2025End-to-end human animation, such as audio-driven talking human generation, has undergone notable advancements in the recent few years. However, existing methods still struggle to scale up as large general video generation models, limiting their potential in real applications. In this paper, we propose OmniHuman, a Diffusion Transformer-based framework that scales up data by mixing motion-related conditions into the training phase. To this end, we introduce two training principles for these mixed conditions, along with the corresponding model architecture and inference strategy. These designs enable OmniHuman to fully leverage data-driven motion generation, ultimately achieving highly realistic human video generation. More importantly, OmniHuman supports various portrait contents (face close-up, portrait, half-body, full-body), supports both talking and singing, handles human-object interactions and challenging body poses, and accommodates different image styles. Compared to existing end-to-end audio-driven methods, OmniHuman not only produces more realistic videos, but also offers greater flexibility in inputs. It also supports multiple driving modalities (audio-driven, video-driven and combined driving signals). Video samples are provided on the ttfamily project page (https://omnihuman-lab.github.io)
FADA: Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation
Dec 22, 2024



Diffusion-based audio-driven talking avatar methods have recently gained attention for their high-fidelity, vivid, and expressive results. However, their slow inference speed limits practical applications. Despite the development of various distillation techniques for diffusion models, we found that naive diffusion distillation methods do not yield satisfactory results. Distilled models exhibit reduced robustness with open-set input images and a decreased correlation between audio and video compared to teacher models, undermining the advantages of diffusion models. To address this, we propose FADA (Fast Diffusion Avatar Synthesis with Mixed-Supervised Multi-CFG Distillation). We first designed a mixed-supervised loss to leverage data of varying quality and enhance the overall model capability as well as robustness. Additionally, we propose a multi-CFG distillation with learnable tokens to utilize the correlation between audio and reference image conditions, reducing the threefold inference runs caused by multi-CFG with acceptable quality degradation. Extensive experiments across multiple datasets show that FADA generates vivid videos comparable to recent diffusion model-based methods while achieving an NFE speedup of 4.17-12.5 times. Demos are available at our webpage http://fadavatar.github.io.
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Sep 04, 2024With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention
Sep 03, 2024



Diffusion-based video generation technology has advanced significantly, catalyzing a proliferation of research in human animation. However, the majority of these studies are confined to same-modality driving settings, with cross-modality human body animation remaining relatively underexplored. In this paper, we introduce, an end-to-end audio-driven human animation framework that ensures hand integrity, identity consistency, and natural motion. The key design of CyberHost is the Region Codebook Attention mechanism, which improves the generation quality of facial and hand animations by integrating fine-grained local features with learned motion pattern priors. Furthermore, we have developed a suite of human-prior-guided training strategies, including body movement map, hand clarity score, pose-aligned reference feature, and local enhancement supervision, to improve synthesis results. To our knowledge, CyberHost is the first end-to-end audio-driven human diffusion model capable of facilitating zero-shot video generation within the scope of human body. Extensive experiments demonstrate that CyberHost surpasses previous works in both quantitative and qualitative aspects.
MobilePortrait: Real-Time One-Shot Neural Head Avatars on Mobile Devices
Jul 08, 2024
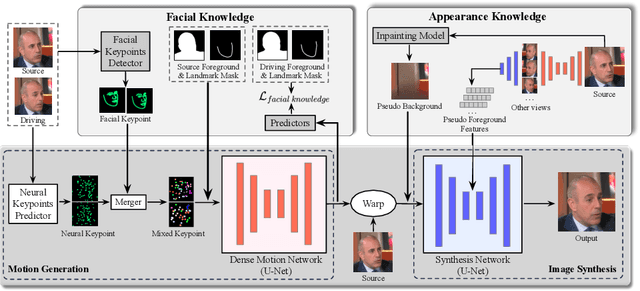


Existing neural head avatars methods have achieved significant progress in the image quality and motion range of portrait animation. However, these methods neglect the computational overhead, and to the best of our knowledge, none is designed to run on mobile devices. This paper presents MobilePortrait, a lightweight one-shot neural head avatars method that reduces learning complexity by integrating external knowledge into both the motion modeling and image synthesis, enabling real-time inference on mobile devices. Specifically, we introduce a mixed representation of explicit and implicit keypoints for precise motion modeling and precomputed visual features for enhanced foreground and background synthesis. With these two key designs and using simple U-Nets as backbones, our method achieves state-of-the-art performance with less than one-tenth the computational demand. It has been validated to reach speeds of over 100 FPS on mobile devices and support both video and audio-driven inputs.
Superior and Pragmatic Talking Face Generation with Teacher-Student Framework
Mar 26, 2024Talking face generation technology creates talking videos from arbitrary appearance and motion signal, with the "arbitrary" offering ease of use but also introducing challenges in practical applications. Existing methods work well with standard inputs but suffer serious performance degradation with intricate real-world ones. Moreover, efficiency is also an important concern in deployment. To comprehensively address these issues, we introduce SuperFace, a teacher-student framework that balances quality, robustness, cost and editability. We first propose a simple but effective teacher model capable of handling inputs of varying qualities to generate high-quality results. Building on this, we devise an efficient distillation strategy to acquire an identity-specific student model that maintains quality with significantly reduced computational load. Our experiments validate that SuperFace offers a more comprehensive solution than existing methods for the four mentioned objectives, especially in reducing FLOPs by 99\% with the student model. SuperFace can be driven by both video and audio and allows for localized facial attributes editing.