 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning
Nov 02, 2022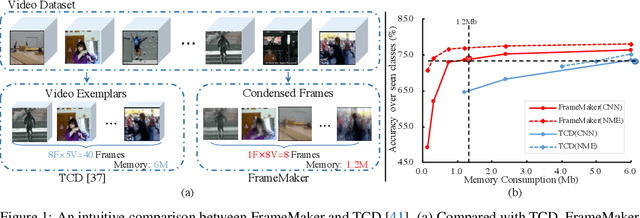
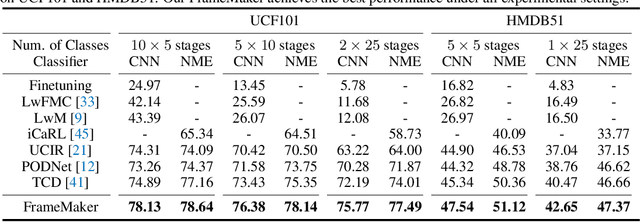
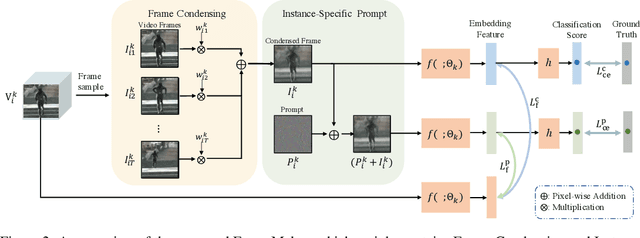
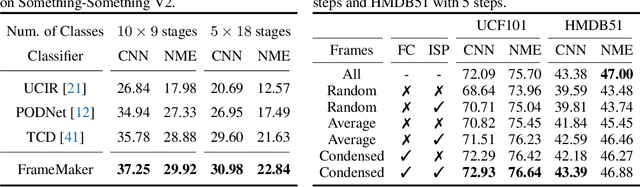
Recent incremental learning for action recognition usually stores representative videos to mitigate catastrophic forgetting. However, only a few bulky videos can be stored due to the limited memory. To address this problem, we propose FrameMaker, a memory-efficient video class-incremental learning approach that learns to produce a condensed frame for each selected video. Specifically, FrameMaker is mainly composed of two crucial components: Frame Condensing and Instance-Specific Prompt. The former is to reduce the memory cost by preserving only one condensed frame instead of the whole video, while the latter aims to compensate the lost spatio-temporal details in the Frame Condensing stage. By this means, FrameMaker enables a remarkable reduction in memory but keep enough information that can be applied to following incremental tasks. Experimental results on multiple challenging benchmarks, i.e., HMDB51, UCF101 and Something-Something V2, demonstrate that FrameMaker can achieve better performance to recent advanced methods while consuming only 20% memory. Additionally, under the same memory consumption conditions, FrameMaker significantly outperforms existing state-of-the-arts by a convincing margin.
Grow and Merge: A Unified Framework for Continuous Categories Discovery
Oct 09, 2022

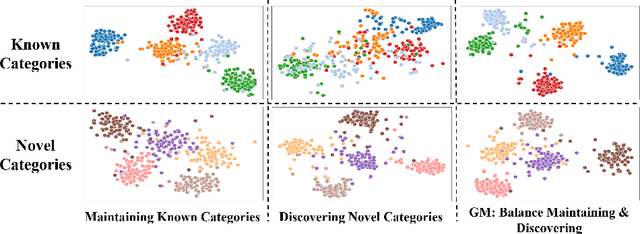
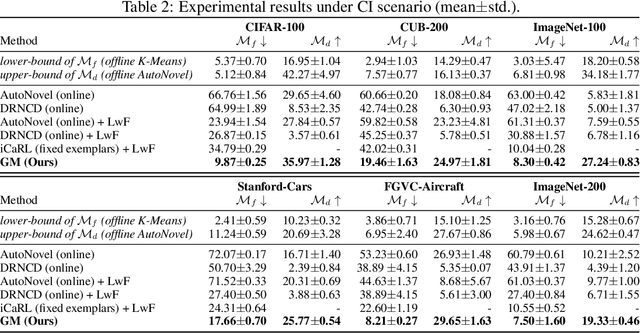
Although a number of studies are devoted to novel category discovery, most of them assume a static setting where both labeled and unlabeled data are given at once for finding new categories. In this work, we focus on the application scenarios where unlabeled data are continuously fed into the category discovery system. We refer to it as the {\bf Continuous Category Discovery} ({\bf CCD}) problem, which is significantly more challenging than the static setting. A common challenge faced by novel category discovery is that different sets of features are needed for classification and category discovery: class discriminative features are preferred for classification, while rich and diverse features are more suitable for new category mining. This challenge becomes more severe for dynamic setting as the system is asked to deliver good performance for known classes over time, and at the same time continuously discover new classes from unlabeled data. To address this challenge, we develop a framework of {\bf Grow and Merge} ({\bf GM}) that works by alternating between a growing phase and a merging phase: in the growing phase, it increases the diversity of features through a continuous self-supervised learning for effective category mining, and in the merging phase, it merges the grown model with a static one to ensure satisfying performance for known classes. Our extensive studies verify that the proposed GM framework is significantly more effective than the state-of-the-art approaches for continuous category discovery.
RLIP: Relational Language-Image Pre-training for Human-Object Interaction Detection
Sep 05, 2022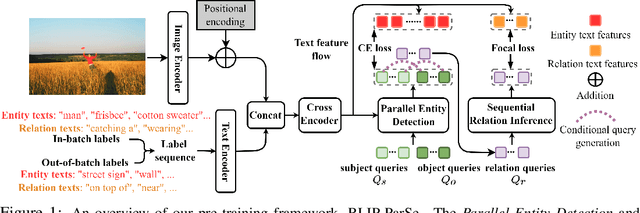
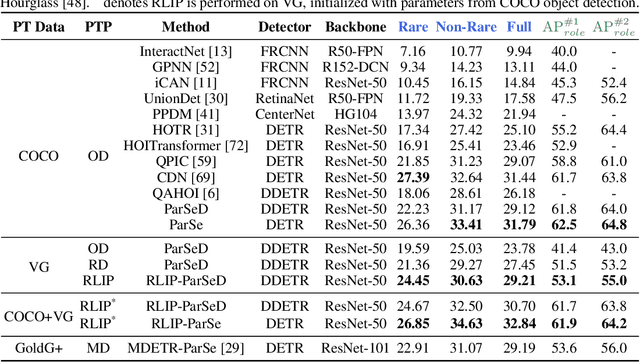
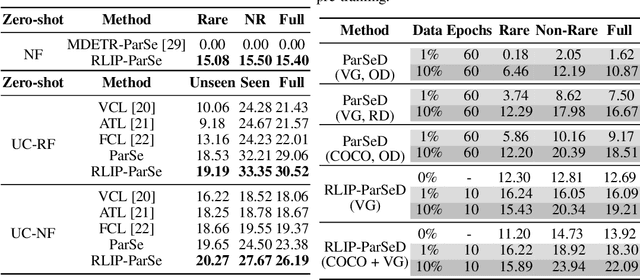

The task of Human-Object Interaction (HOI) detection targets fine-grained visual parsing of humans interacting with their environment, enabling a broad range of applications. Prior work has demonstrated the benefits of effective architecture design and integration of relevant cues for more accurate HOI detection. However, the design of an appropriate pre-training strategy for this task remains underexplored by existing approaches. To address this gap, we propose Relational Language-Image Pre-training (RLIP), a strategy for contrastive pre-training that leverages both entity and relation descriptions. To make effective use of such pre-training, we make three technical contributions: (1) a new Parallel entity detection and Sequential relation inference (ParSe) architecture that enables the use of both entity and relation descriptions during holistically optimized pre-training; (2) a synthetic data generation framework, Label Sequence Extension, that expands the scale of language data available within each minibatch; (3) mechanisms to account for ambiguity, Relation Quality Labels and Relation Pseudo-Labels, to mitigate the influence of ambiguous/noisy samples in the pre-training data. Through extensive experiments, we demonstrate the benefits of these contributions, collectively termed RLIP-ParSe, for improved zero-shot, few-shot and fine-tuning HOI detection performance as well as increased robustness to learning from noisy annotations. Code will be available at \url{https://github.com/JacobYuan7/RLIP}.
Open-world Semantic Segmentation for LIDAR Point Clouds
Jul 04, 2022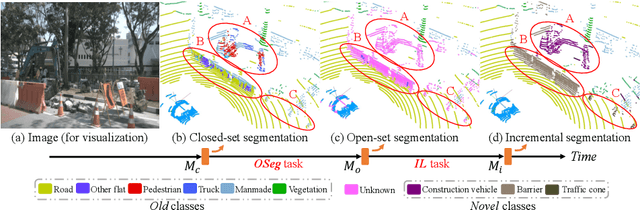
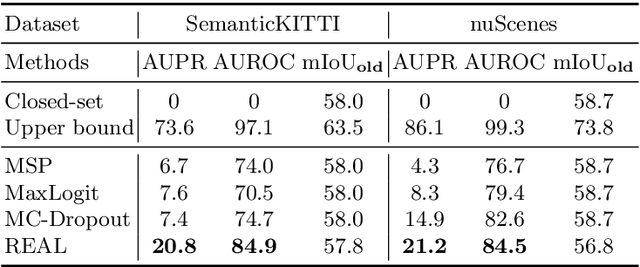
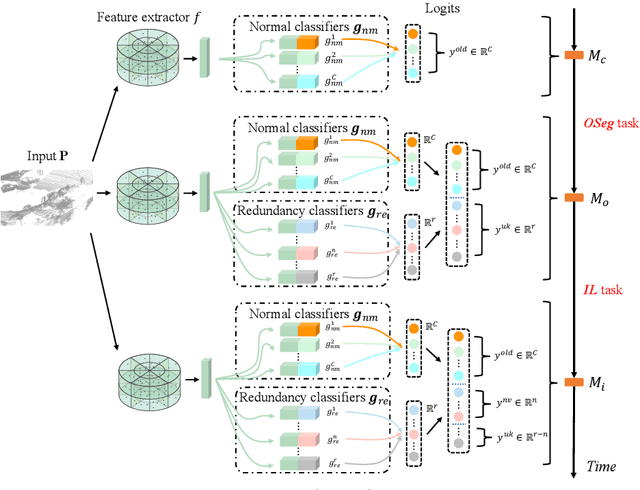

Current methods for LIDAR semantic segmentation are not robust enough for real-world applications, e.g., autonomous driving, since it is closed-set and static. The closed-set assumption makes the network only able to output labels of trained classes, even for objects never seen before, while a static network cannot update its knowledge base according to what it has seen. Therefore, in this work, we propose the open-world semantic segmentation task for LIDAR point clouds, which aims to 1) identify both old and novel classes using open-set semantic segmentation, and 2) gradually incorporate novel objects into the existing knowledge base using incremental learning without forgetting old classes. For this purpose, we propose a REdundAncy cLassifier (REAL) framework to provide a general architecture for both the open-set semantic segmentation and incremental learning problems. The experimental results show that REAL can simultaneously achieves state-of-the-art performance in the open-set semantic segmentation task on the SemanticKITTI and nuScenes datasets, and alleviate the catastrophic forgetting problem with a large margin during incremental learning.
Hybrid Relation Guided Set Matching for Few-shot Action Recognition
Apr 28, 2022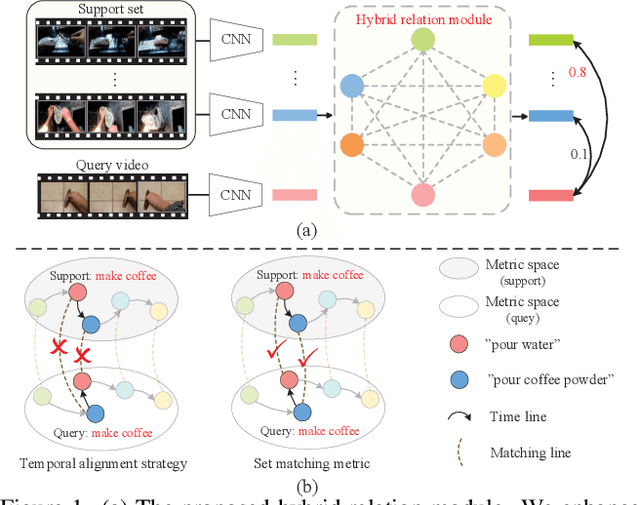
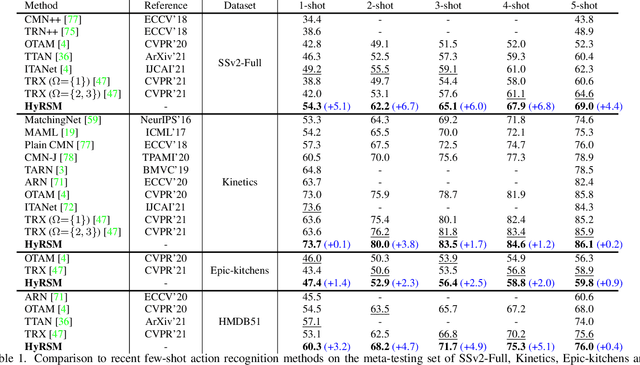
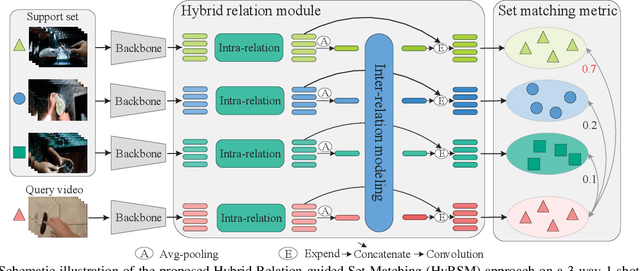
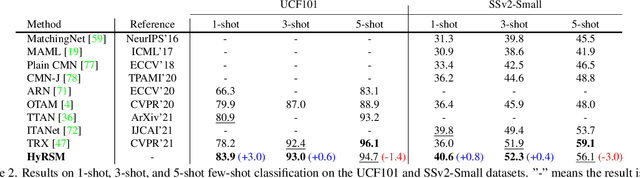
Current few-shot action recognition methods reach impressive performance by learning discriminative features for each video via episodic training and designing various temporal alignment strategies. Nevertheless, they are limited in that (a) learning individual features without considering the entire task may lose the most relevant information in the current episode, and (b) these alignment strategies may fail in misaligned instances. To overcome the two limitations, we propose a novel Hybrid Relation guided Set Matching (HyRSM) approach that incorporates two key components: hybrid relation module and set matching metric. The purpose of the hybrid relation module is to learn task-specific embeddings by fully exploiting associated relations within and cross videos in an episode. Built upon the task-specific features, we reformulate distance measure between query and support videos as a set matching problem and further design a bidirectional Mean Hausdorff Metric to improve the resilience to misaligned instances. By this means, the proposed HyRSM can be highly informative and flexible to predict query categories under the few-shot settings. We evaluate HyRSM on six challenging benchmarks, and the experimental results show its superiority over the state-of-the-art methods by a convincing margin. Project page: https://hyrsm-cvpr2022.github.io/.
Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency
Apr 06, 2022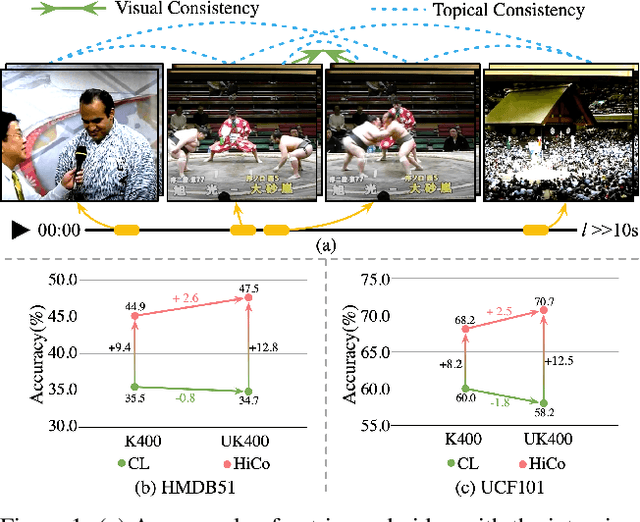
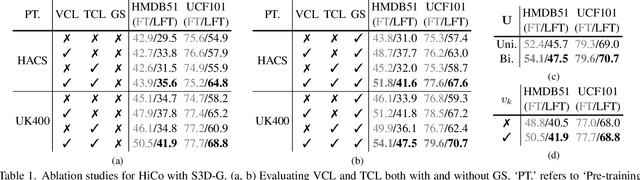
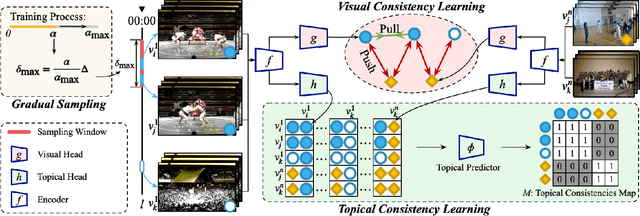
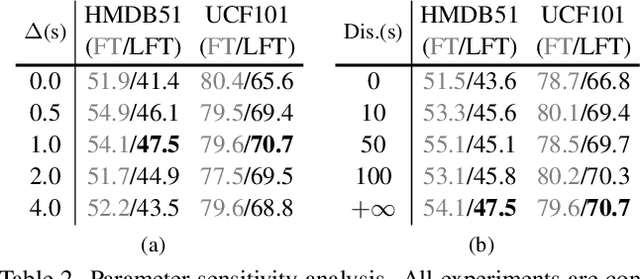
Natural videos provide rich visual contents for self-supervised learning. Yet most existing approaches for learning spatio-temporal representations rely on manually trimmed videos, leading to limited diversity in visual patterns and limited performance gain. In this work, we aim to learn representations by leveraging more abundant information in untrimmed videos. To this end, we propose to learn a hierarchy of consistencies in videos, i.e., visual consistency and topical consistency, corresponding respectively to clip pairs that tend to be visually similar when separated by a short time span and share similar topics when separated by a long time span. Specifically, a hierarchical consistency learning framework HiCo is presented, where the visually consistent pairs are encouraged to have the same representation through contrastive learning, while the topically consistent pairs are coupled through a topical classifier that distinguishes whether they are topic related. Further, we impose a gradual sampling algorithm for proposed hierarchical consistency learning, and demonstrate its theoretical superiority. Empirically, we show that not only HiCo can generate stronger representations on untrimmed videos, it also improves the representation quality when applied to trimmed videos. This is in contrast to standard contrastive learning that fails to learn appropriate representations from untrimmed videos.
TAda! Temporally-Adaptive Convolutions for Video Understanding
Oct 12, 2021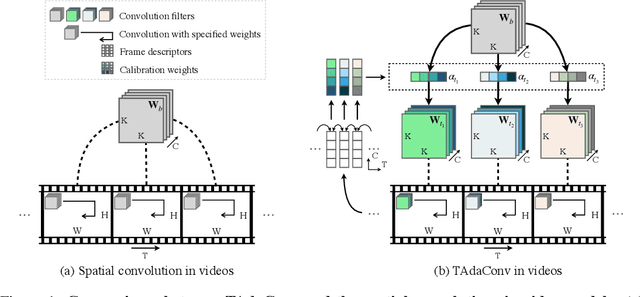

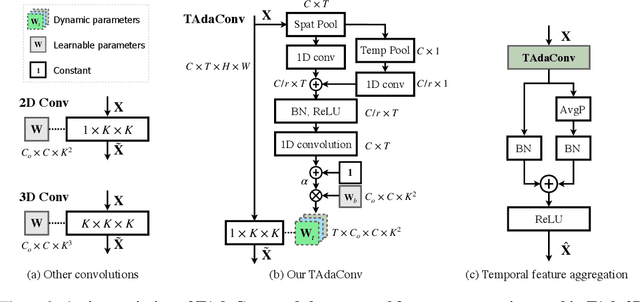
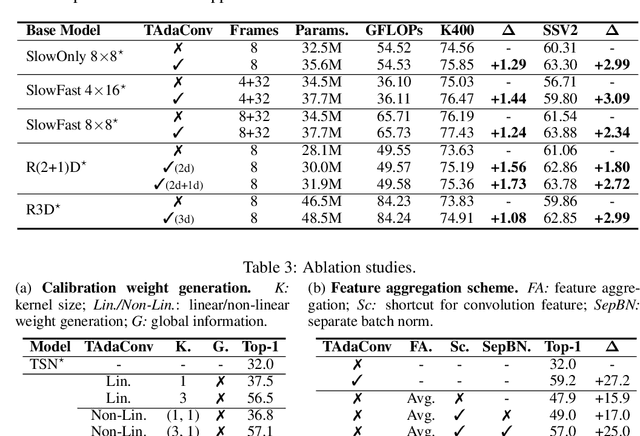
Spatial convolutions are widely used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modelling complex temporal dynamics in videos. Specifically, TAdaConv empowers the spatial convolutions with temporal modelling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to previous temporal modelling operations, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, the kernel calibration also brings an increased model capacity. We construct TAda2D networks by replacing the spatial convolutions in ResNet with TAdaConv, which leads to on par or better performance compared to state-of-the-art approaches on multiple video action recognition and localization benchmarks. We also demonstrate that as a readily plug-in operation with negligible computation overhead, TAdaConv can effectively improve many existing video models with a convincing margin. Codes and models will be made available at https://github.com/alibaba-mmai-research/pytorch-video-understanding.
Rethinking supervised pre-training for better downstream transferring
Oct 12, 2021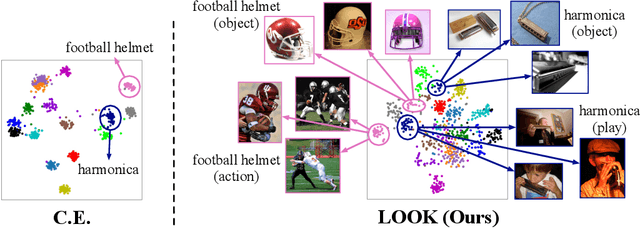
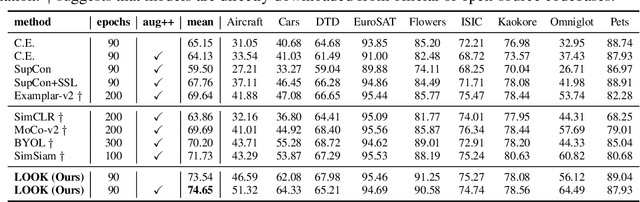
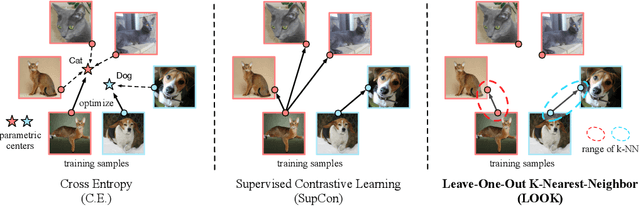
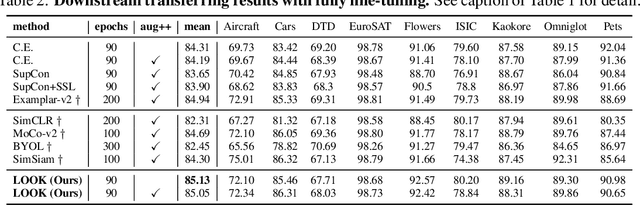
The pretrain-finetune paradigm has shown outstanding performance on many applications of deep learning, where a model is pre-trained on a upstream large dataset (e.g. ImageNet), and is then fine-tuned to different downstream tasks. Though for most cases, the pre-training stage is conducted based on supervised methods, recent works on self-supervised pre-training have shown powerful transferability and even outperform supervised pre-training on multiple downstream tasks. It thus remains an open question how to better generalize supervised pre-training model to downstream tasks. In this paper, we argue that the worse transferability of existing supervised pre-training methods arise from the negligence of valuable intra-class semantic difference. This is because these methods tend to push images from the same class close to each other despite of the large diversity in their visual contents, a problem to which referred as "overfit of upstream tasks". To alleviate this problem, we propose a new supervised pre-training method based on Leave-One-Out K-Nearest-Neighbor, or LOOK for short. It relieves the problem of overfitting upstream tasks by only requiring each image to share its class label with most of its k nearest neighbors, thus allowing each class to exhibit a multi-mode distribution and consequentially preserving part of intra-class difference for better transferring to downstream tasks. We developed efficient implementation of the proposed method that scales well to large datasets. Experimental studies on multiple downstream tasks show that LOOK outperforms other state-of-the-art methods for supervised and self-supervised pre-training.
ParamCrop: Parametric Cubic Cropping for Video Contrastive Learning
Sep 05, 2021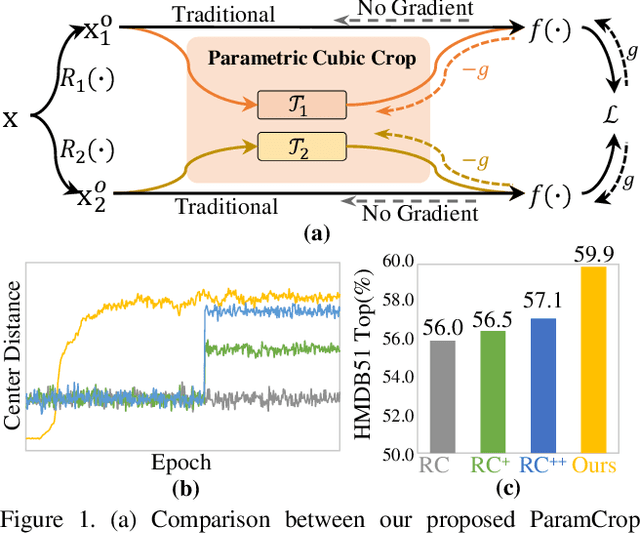

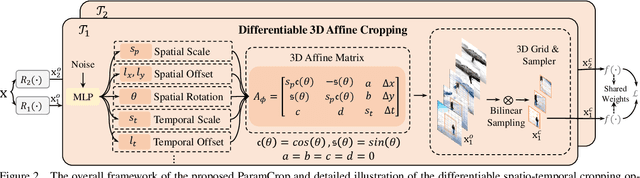
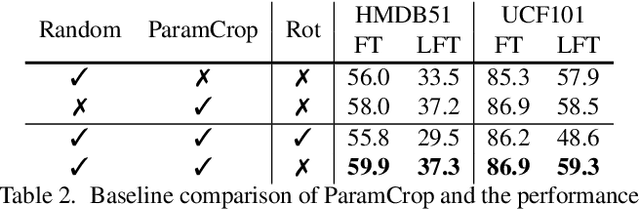
The central idea of contrastive learning is to discriminate between different instances and force different views of the same instance to share the same representation. To avoid trivial solutions, augmentation plays an important role in generating different views, among which random cropping is shown to be effective for the model to learn a strong and generalized representation. Commonly used random crop operation keeps the difference between two views statistically consistent along the training process. In this work, we challenge this convention by showing that adaptively controlling the disparity between two augmented views along the training process enhances the quality of the learnt representation. Specifically, we present a parametric cubic cropping operation, ParamCrop, for video contrastive learning, which automatically crops a 3D cubic from the video by differentiable 3D affine transformations. ParamCrop is trained simultaneously with the video backbone using an adversarial objective and learns an optimal cropping strategy from the data. The visualizations show that the center distance and the IoU between two augmented views are adaptively controlled by ParamCrop and the learned change in the disparity along the training process is beneficial to learning a strong representation. Extensive ablation studies demonstrate the effectiveness of the proposed ParamCrop on multiple contrastive learning frameworks and video backbones. With ParamCrop, we improve the state-of-the-art performance on both HMDB51 and UCF101 datasets.
NGC: A Unified Framework for Learning with Open-World Noisy Data
Aug 25, 2021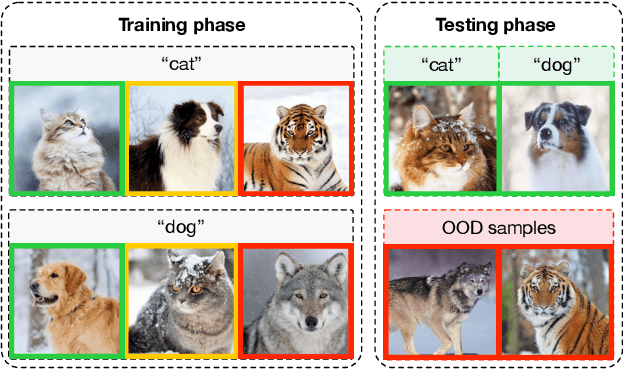
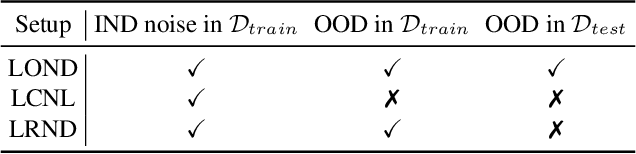
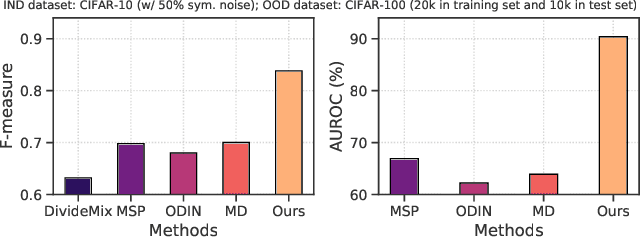
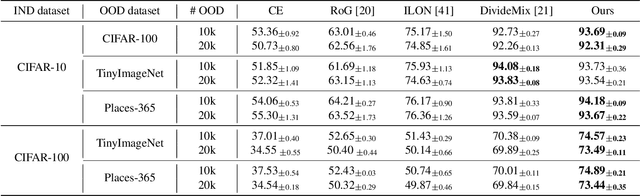
The existence of noisy data is prevalent in both the training and testing phases of machine learning systems, which inevitably leads to the degradation of model performance. There have been plenty of works concentrated on learning with in-distribution (IND) noisy labels in the last decade, i.e., some training samples are assigned incorrect labels that do not correspond to their true classes. Nonetheless, in real application scenarios, it is necessary to consider the influence of out-of-distribution (OOD) samples, i.e., samples that do not belong to any known classes, which has not been sufficiently explored yet. To remedy this, we study a new problem setup, namely Learning with Open-world Noisy Data (LOND). The goal of LOND is to simultaneously learn a classifier and an OOD detector from datasets with mixed IND and OOD noise. In this paper, we propose a new graph-based framework, namely Noisy Graph Cleaning (NGC), which collects clean samples by leveraging geometric structure of data and model predictive confidence. Without any additional training effort, NGC can detect and reject the OOD samples based on the learned class prototypes directly in testing phase. We conduct experiments on multiple benchmarks with different types of noise and the results demonstrate the superior performance of our method against state of the arts.