 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgeDreamer: Industrial Text-to-3D Generation with Multi-Expert LoRA and Cross-View Hypergraph
Mar 10, 2026Current text-to-3D generation methods excel in natural scenes but struggle with industrial applications due to two critical limitations: domain adaptation challenges where conventional LoRA fusion causes knowledge interference across categories, and geometric reasoning deficiencies where pairwise consistency constraints fail to capture higher-order structural dependencies essential for precision manufacturing. We propose a novel framework named ForgeDreamer addressing both challenges through two key innovations. First, we introduce a Multi-Expert LoRA Ensemble mechanism that consolidates multiple category-specific LoRA models into a unified representation, achieving superior cross-category generalization while eliminating knowledge interference. Second, building on enhanced semantic understanding, we develop a Cross-View Hypergraph Geometric Enhancement approach that captures structural dependencies spanning multiple viewpoints simultaneously. These components work synergistically improved semantic understanding, enables more effective geometric reasoning, while hypergraph modeling ensures manufacturing-level consistency. Extensive experiments on a custom industrial dataset demonstrate superior semantic generalization and enhanced geometric fidelity compared to state-of-the-art approaches. Our code and data are provided in the supplementary material attached in the appendix for review purposes.
InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Generative Artificial Intelligence in Robotic Manipulation: A Survey
Mar 05, 2025



This survey provides a comprehensive review on recent advancements of generative learning models in robotic manipulation, addressing key challenges in the field. Robotic manipulation faces critical bottlenecks, including significant challenges in insufficient data and inefficient data acquisition, long-horizon and complex task planning, and the multi-modality reasoning ability for robust policy learning performance across diverse environments. To tackle these challenges, this survey introduces several generative model paradigms, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), diffusion models, probabilistic flow models, and autoregressive models, highlighting their strengths and limitations. The applications of these models are categorized into three hierarchical layers: the Foundation Layer, focusing on data generation and reward generation; the Intermediate Layer, covering language, code, visual, and state generation; and the Policy Layer, emphasizing grasp generation and trajectory generation. Each layer is explored in detail, along with notable works that have advanced the state of the art. Finally, the survey outlines future research directions and challenges, emphasizing the need for improved efficiency in data utilization, better handling of long-horizon tasks, and enhanced generalization across diverse robotic scenarios. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/GAI4Manipulation/AwesomeGAIManipulation
Toward Scalable and Efficient Visual Data Transmission in 6G Networks
Sep 24, 2024
6G network technology will emerge in a landscape where visual data transmissions dominate global mobile traffic and are expected to grow continuously, driven by the increasing demand for AI-based computer vision applications. This will make already challenging task of visual data transmission even more difficult. In this work, we review effective techniques for visual data transmission, such as content compression and adaptive video streaming, highlighting their advantages and limitations. Further, considering the scalability and cost issues of cloud-based and on-device AI services, we explore distributed in-network computing architecture like fog-computing as a direction of 6G networks, and investigate the necessary technical properties for the timely delivery of visual data.
Gaussian-Informed Continuum for Physical Property Identification and Simulation
Jun 21, 2024This paper studies the problem of estimating physical properties (system identification) through visual observations. To facilitate geometry-aware guidance in physical property estimation, we introduce a novel hybrid framework that leverages 3D Gaussian representation to not only capture explicit shapes but also enable the simulated continuum to deduce implicit shapes during training. We propose a new dynamic 3D Gaussian framework based on motion factorization to recover the object as 3D Gaussian point sets across different time states. Furthermore, we develop a coarse-to-fine filling strategy to generate the density fields of the object from the Gaussian reconstruction, allowing for the extraction of object continuums along with their surfaces and the integration of Gaussian attributes into these continuums. In addition to the extracted object surfaces, the Gaussian-informed continuum also enables the rendering of object masks during simulations, serving as implicit shape guidance for physical property estimation. Extensive experimental evaluations demonstrate that our pipeline achieves state-of-the-art performance across multiple benchmarks and metrics. Additionally, we illustrate the effectiveness of the proposed method through real-world demonstrations, showcasing its practical utility. Our project page is at https://jukgei.github.io/project/gic.
IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images
Mar 30, 2024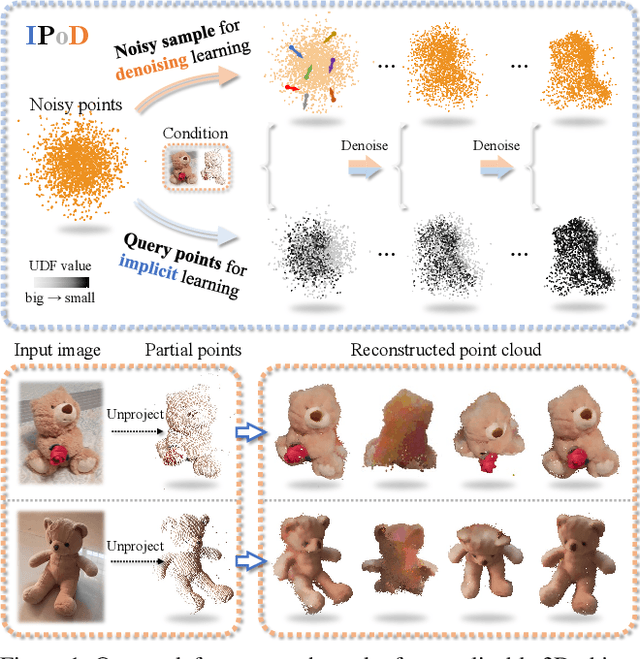
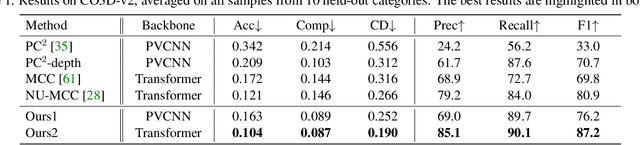
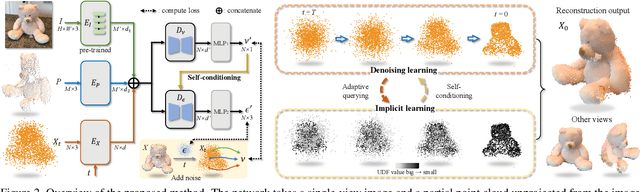
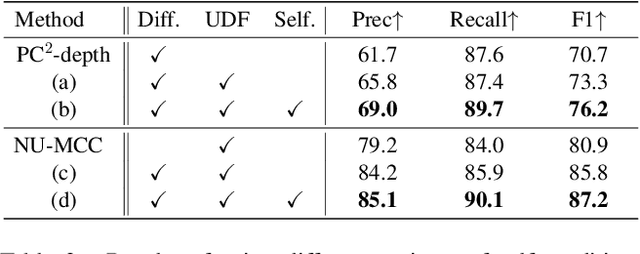
Generalizable 3D object reconstruction from single-view RGB-D images remains a challenging task, particularly with real-world data. Current state-of-the-art methods develop Transformer-based implicit field learning, necessitating an intensive learning paradigm that requires dense query-supervision uniformly sampled throughout the entire space. We propose a novel approach, IPoD, which harmonizes implicit field learning with point diffusion. This approach treats the query points for implicit field learning as a noisy point cloud for iterative denoising, allowing for their dynamic adaptation to the target object shape. Such adaptive query points harness diffusion learning's capability for coarse shape recovery and also enhances the implicit representation's ability to delineate finer details. Besides, an additional self-conditioning mechanism is designed to use implicit predictions as the guidance of diffusion learning, leading to a cooperative system. Experiments conducted on the CO3D-v2 dataset affirm the superiority of IPoD, achieving 7.8% improvement in F-score and 28.6% in Chamfer distance over existing methods. The generalizability of IPoD is also demonstrated on the MVImgNet dataset. Our project page is at https://yushuang-wu.github.io/IPoD.
OV9D: Open-Vocabulary Category-Level 9D Object Pose and Size Estimation
Mar 19, 2024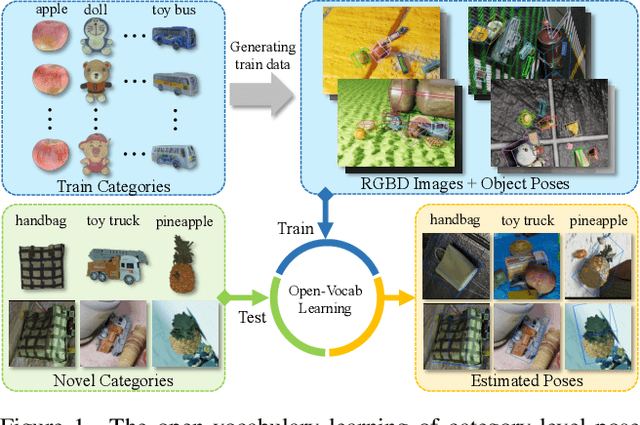
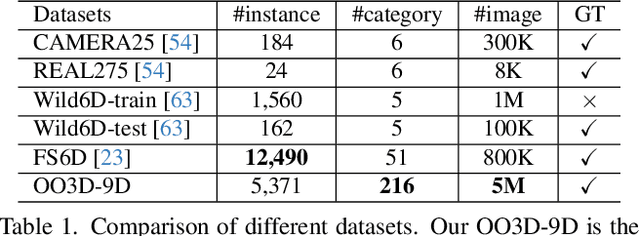

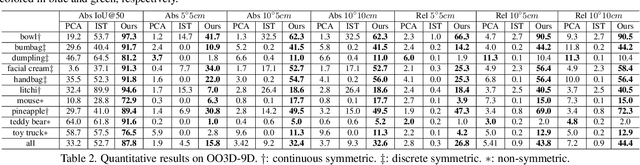
This paper studies a new open-set problem, the open-vocabulary category-level object pose and size estimation. Given human text descriptions of arbitrary novel object categories, the robot agent seeks to predict the position, orientation, and size of the target object in the observed scene image. To enable such generalizability, we first introduce OO3D-9D, a large-scale photorealistic dataset for this task. Derived from OmniObject3D, OO3D-9D is the largest and most diverse dataset in the field of category-level object pose and size estimation. It includes additional annotations for the symmetry axis of each category, which help resolve symmetric ambiguity. Apart from the large-scale dataset, we find another key to enabling such generalizability is leveraging the strong prior knowledge in pre-trained visual-language foundation models. We then propose a framework built on pre-trained DinoV2 and text-to-image stable diffusion models to infer the normalized object coordinate space (NOCS) maps of the target instances. This framework fully leverages the visual semantic prior from DinoV2 and the aligned visual and language knowledge within the text-to-image diffusion model, which enables generalization to various text descriptions of novel categories. Comprehensive quantitative and qualitative experiments demonstrate that the proposed open-vocabulary method, trained on our large-scale synthesized data, significantly outperforms the baseline and can effectively generalize to real-world images of unseen categories. The project page is at https://ov9d.github.io.
ERRA: An Embodied Representation and Reasoning Architecture for Long-horizon Language-conditioned Manipulation Tasks
Apr 05, 2023This letter introduces ERRA, an embodied learning architecture that enables robots to jointly obtain three fundamental capabilities (reasoning, planning, and interaction) for solving long-horizon language-conditioned manipulation tasks. ERRA is based on tightly-coupled probabilistic inferences at two granularity levels. Coarse-resolution inference is formulated as sequence generation through a large language model, which infers action language from natural language instruction and environment state. The robot then zooms to the fine-resolution inference part to perform the concrete action corresponding to the action language. Fine-resolution inference is constructed as a Markov decision process, which takes action language and environmental sensing as observations and outputs the action. The results of action execution in environments provide feedback for subsequent coarse-resolution reasoning. Such coarse-to-fine inference allows the robot to decompose and achieve long-horizon tasks interactively. In extensive experiments, we show that ERRA can complete various long-horizon manipulation tasks specified by abstract language instructions. We also demonstrate successful generalization to the novel but similar natural language instructions.
Flipbot: Learning Continuous Paper Flipping via Coarse-to-Fine Exteroceptive-Proprioceptive Exploration
Apr 05, 2023This paper tackles the task of singulating and grasping paper-like deformable objects. We refer to such tasks as paper-flipping. In contrast to manipulating deformable objects that lack compression strength (such as shirts and ropes), minor variations in the physical properties of the paper-like deformable objects significantly impact the results, making manipulation highly challenging. Here, we present Flipbot, a novel solution for flipping paper-like deformable objects. Flipbot allows the robot to capture object physical properties by integrating exteroceptive and proprioceptive perceptions that are indispensable for manipulating deformable objects. Furthermore, by incorporating a proposed coarse-to-fine exploration process, the system is capable of learning the optimal control parameters for effective paper-flipping through proprioceptive and exteroceptive inputs. We deploy our method on a real-world robot with a soft gripper and learn in a self-supervised manner. The resulting policy demonstrates the effectiveness of Flipbot on paper-flipping tasks with various settings beyond the reach of prior studies, including but not limited to flipping pages throughout a book and emptying paper sheets in a box.
Learn to Grasp via Intention Discovery and its Application to Challenging Clutter
Apr 05, 2023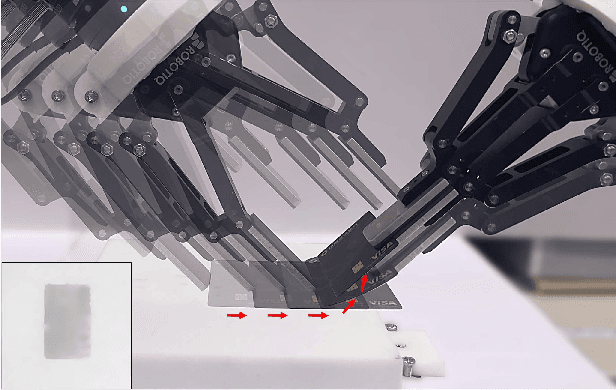
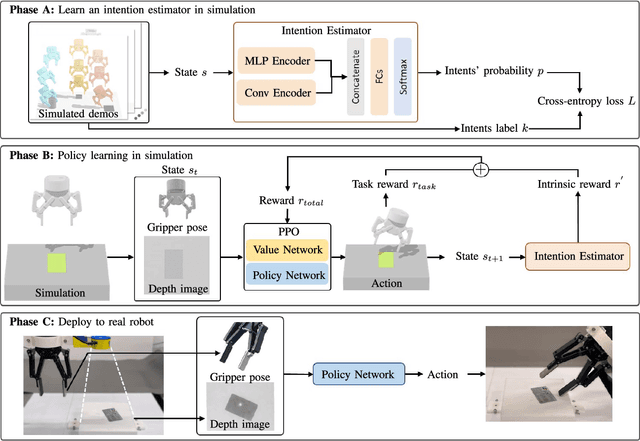
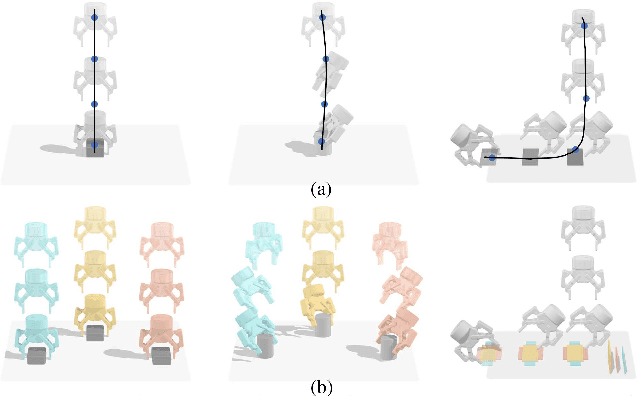
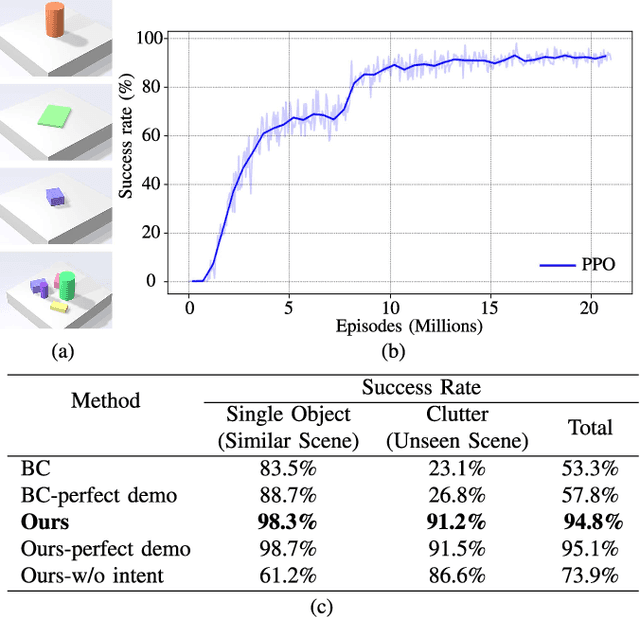
Humans excel in grasping objects through diverse and robust policies, many of which are so probabilistically rare that exploration-based learning methods hardly observe and learn. Inspired by the human learning process, we propose a method to extract and exploit latent intents from demonstrations, and then learn diverse and robust grasping policies through self-exploration. The resulting policy can grasp challenging objects in various environments with an off-the-shelf parallel gripper. The key component is a learned intention estimator, which maps gripper pose and visual sensory to a set of sub-intents covering important phases of the grasping movement. Sub-intents can be used to build an intrinsic reward to guide policy learning. The learned policy demonstrates remarkable zero-shot generalization from simulation to the real world while retaining its robustness against states that have never been encountered during training, novel objects such as protractors and user manuals, and environments such as the cluttered conveyor.
* Accepted to IEEE Robotics and Automation Letters (RA-L)